- The AI Timeline
- Posts
- The AI Timeline #4 - Machine Learning 2.0 Is Here?
The AI Timeline #4 - Machine Learning 2.0 Is Here?
Latest AI Research Explained Simply
by cloud
May 07, 2024

In this issue: x3 AI research papers
KAN: Kolmogorov–Arnold Networks
Ziming Liu et al. [MiT, Cal Tech, NEU]
♥ 4.9k Machine Learning Theory

Multi-Layer Perceptron vs Kolmogorov-Arnold Network
Overview
Most AI models rely on a fundamental concept, Multi-layer Perceptron (MLP) – a mathematical way of mimicking the neurons of a human brain. These perceptrons have two main parts – a weight (which changes as we train the model) and an activation function (which never changes).
Instead of using a fixed activation function, KANs use a learnable-activation function, i.e. a function that changes as we train the model.
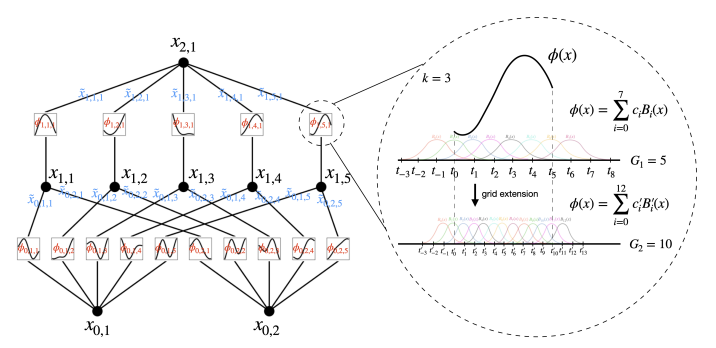
B-spline activation functions in Kolmogorov–Arnold Networks.
How Does KAN Work?
In order to make the activation function trainable, they used B-spline which is a piece-wise polynomial function which can be parameterized.
The B-spline parameters are like a series of points that acts as magnets, which pulls the curve and changes its shapes. This set of points is referred to as a grid in the paper.

B-spline visualized
Highlights
Do more with less parameters: KANs use x100 less parameters than standard MLP to have equal performance, but KAN is x10 slower to train.
Scalability: It potentially scales better than MLP with Kolmogorov-Arnold representation theorem.
Interpretability: Unlike MLP which is like a black box, you can perform symbolic regression and extract interpretable equations for your network thanks to the B-spline’s properties.

Interpretability of KAN: how symbolic regression can be done
Results
For solving Partial Differential Equations (PDE), a 2-Layer width-10 KAN is shown to be 100 times more accurate and 100 times more parameter efficient than a 4-Layer width-100 MLP.
KAN is able to avoid catastrophic forgetting in a simple toy case setting

Moreover, these networks are not only applicable to the machine learning tasks, but they can also rediscover complex relations in knot theory and phase transition boundaries in condensed matter physics with x100 less parameters

Criticisms
The MLP within the paper might be potentially undertrained which may have made KAN looked better. However, keep in mind that KAN is a new method and doesn’t have the same pre-existing knowledge that MLP has (discussion on X).
KAN could easily overfit to training data, especially when there is noise, which is common for real world.

Editor’s note
KAN is interesting because it needs less parameters than MLP to have similar performance, and also provide a rigorous way to do AI interpretation, which opens the door for practical usages in engineering and physics.
The KAN’s authors did not test it on image classification or sequential data (for LLMs etc), which should definitely be explored.
The downside is it seems very difficult to train, and the researchers would need more time to figure out the optimal way to train them and see if it’s actually worth developing or not.
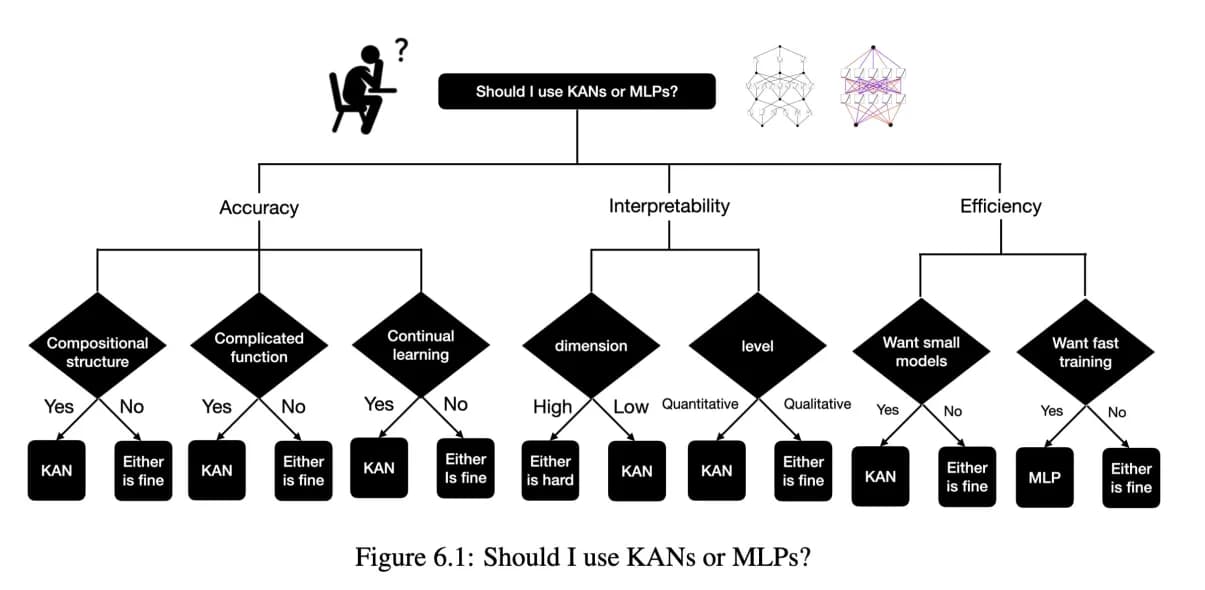
Flowchart of when you should use KAN
Better & Faster Large Language Models via Multi-token Prediction
Fabian Gloeckle et al. [FAIR, Meta, CERMICS, LISN]
♥ 900 LLM
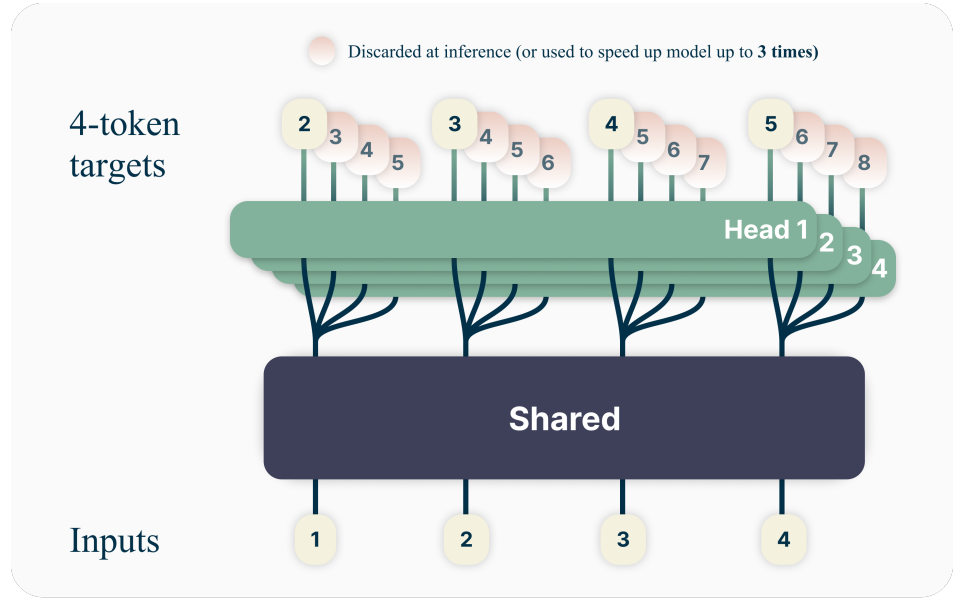
Using multiple attention heads on a single trunk to predict multiple tokens.
Overview
Most LLMs predicted only one token (part of a word) in a sequence. This research proposed the use of multiple attention heads on a shared trunk to predict multiple future tokens at once.
The researchers showed that it led to significant performance improvements, especially for larger models and coding tasks.
How Does Multi-Token Prediction Work?
Let’s break down the architecture of the multi-token prediction model which consists of three main components:
Shared Trunk: This part of the model produces a hidden representation of the past tokens.
Independent Output Heads: We then have n heads, each head is used for predicting one each of the n future tokens.
Shared Unembedding Matrix: A matrix then converts the predicted token representations back into actual tokens.
Highlights & Results
Models trained with multi-token prediction can leverage the additional output heads for faster inference through speculative decoding, achieving up to x3 speedup.
The proposed multi-token prediction approach does not add computational overhead during training, thanks to a memory-efficient implementation.
Pre-training with multi-token prediction improves the performance of larger models when fine-tuned on downstream tasks, such as code generation and NLP tasks like summarization.
InstantFamily: Masked Attention for Zero-shot Multi-ID Image Generation
Chanran Kim et al. [SK Telecom]
♥ 743 Image Generation

Personalized Text-to-Image Generation with multiple identities
Overview
Until now, generating 2 or more people in a single image within a single pass was extremely difficult as the identities of people could easily blend together, which would made the resulting image not resemble anyone.
This paper introduces a way to generate a single image with multiple consistent identities and allows dynamic control over their poses as well as spatial relations.
How Does InstantFamily Work?

Architecture overview
Input Features:
InstantFamily integrates both global and local features from faces.
Global features capture overall facial characteristics, while local features provide detailed information.
Multimodal Embedding Stack:

The multimodal embedding stack combines text embedding with multi-ID embedding.
Multi-ID embedding is obtained from face recognition encoders for multiple faces in an image.
Masked Cross-Attention

To weight multi-ID embedding, a masked cross-attention mechanism is introduced.
The mask ensures that attention focuses on important parts of the input image.
This process occurs in both UNet and ControlNet.
Results
In terms of identity preservation, the InstantFamily model beats other state of the art models without needing to tweak prompts even when generating images of more than four people, this makes it a good option to create interesting images in a variety of settings.

InstantFamily results compared with existing state of the art research

InstantFamily supporting text and image conditionings
Reply