- The AI Timeline
- Posts
- LSTM Is Back?! DeepSeek V2, and You Only Cache Once

In this issue: x3 industry news, x3 AI research papers
Week May 6th ~ May 12th
🗞️ Industry News in 1 Line
♥ 1.8k ElevenLabs created a new model which can generate music clips along with vocals, beats, and background music – all from just a single text prompt!
♥ 318 Any ML scientist will tell you that when creating a model, a large chunk of time is spent on cleaning and labeling the data. RefuelAI has released RefuelLLM-2, a model for labeling data and creating datasets which outperforms all state-of-the-art models including GPT-4-Turbo, Claude-3-Opus, and Gemini-1.5-Pro for speeding up this mundane work.
♥ 6.4k We often see AI being used for productivity, so it was nice to see a big update in the medical AI field. The researchers at Google DeepMind have released AlphaFold 3, a model which can speed up medical research and drug discovery by predicting how different proteins and molecules react under different circumstances.
1. xLSTM: Extended Long Short-Term Memory
Beck et al. [ELLIS Unit, LIT AI Lab, Institute for Machine Learning, JKU Linz, NXAI Lab, NXAI GmbH]
♥ 1.8k Machine Learning Theory

LSTM vs xLSTM
Overview
The idea of Long-Short Term Memory (LSTM) was introduced in the 1990s to handle the inputs of varying length. The introduction of LSTMs solved the problem of vanishing and exploding gradients, and it is pretty good at language modeling. However, they have three key limitations:
Inability to revise storage decisions: LSTMs struggle to update a stored value when a more similar vector is found during tasks like Nearest Neighbor Search.
Limited storage capacities: LSTMs compress information into scalar cell states, which can lead to poor performance on tasks like predicting rare tokens.
Lack of parallelizability due to memory mixing: The connections between hidden states in LSTMs enforce sequential processing, which limits parallelization, and makes it slow to use.
Due to the above limitations, with its slow speed as its biggest downfall, LSTMs were outshined by Transformer models for language modeling tasks. This paper introduces an enhancement to the LSTM architecture which aims to overcome the above-mentioned drawbacks and challenge against existing state of the art LLMs.
How Does xLSTM work?
The xLSTM approach aims to address the limitations of LSTM-based language models using the following enhancements:
Exponential Gating: xLSTM introduces exponential gating with appropriate normalization and stabilization techniques which enhances the gating mechanism, to address the inability of revising storage decisions.
Modified Memory Structures:
sLSTM (Scalar LSTM): A variant of LSTM with a scalar memory, scalar update, and new memory mixing – it retains some parallelizability. This aims to solve the lack of parallelization that LSTM has.
mLSTM (Matrix LSTM): An improvement of sLSTM which uses a matrix memory and a covariance update rule that makes it fully parallelizable and allows for efficient computation across time steps.

This paper tested the above modifications with two different residual block architectures for accurately predicting the next element in a sequence, such as the next token:
Post up-projection (like Transformers): This type of block first summarizes the past non-linearly in the original space, and maps it linearly into a high-dimensional space. Then it applies a non-linear activation function, and finally maps it back linearly to the original space.
Pre up-projection (like State Space Models): This block first maps linearly to a high-dimensional space, then summarizes the past non-linearly in this high-dimensional space, and finally maps it back linearly to the original space.
Results
This modification to the LSTM architecture significantly improves its performance for the language modeling tasks as the resulting model performs as good as state-of-the-art Transformers and State Space Models in terms of both performance and scalability. The following chart shows how xLSTM performed in natural language processing tasks when being trained on 15B tokens from SlimPajama dataset.

Limitations
The limitations of the xLSTM architecture include:
Parallelizability: The sLSTM variant of xLSTM does not support parallelizable operations due to memory mixing, which can affect performance and speed.
Optimization: The CUDA kernels for mLSTM are not fully optimized, which may result in slower performance compared to other optimized methods.
Computational Complexity: The matrix memory in mLSTM requires processing of large matrices, leading to high computational complexity.
Initialization Sensitivity: The initialization of forget gates in xLSTM must be chosen carefully to ensure proper functioning.
Memory Overload: For very long context sizes, the matrix memory might become overloaded, although this has not been observed for contexts up to 16k.
Hyperparameter Tuning: Extensive optimization of architecture and hyperparameters is needed for xLSTM to reach its full potential, especially for larger models.
Criticisms
The paper used a small dataset called Penn Tree Bank which only contains 1 million words, while this might sound like a lot, modern transformer models are trained on billions and sometimes trillions of words which would indicate that the learning capacity of this model questionable.
When testing the scalability of different LLMs, experts recommend using FLOP control for the same number of parameters; not doing so can lead to misleading results.
The critics have pointed out that the learning rates of transformer based models were not increased with the token-counts unlike xLSTM which makes it an unfair comparison.
The paper itself mentions that existing xLSTMs do not show an improvement in performance across the board – there are still quite a few tasks where the original LSTM beats the modified architecture.
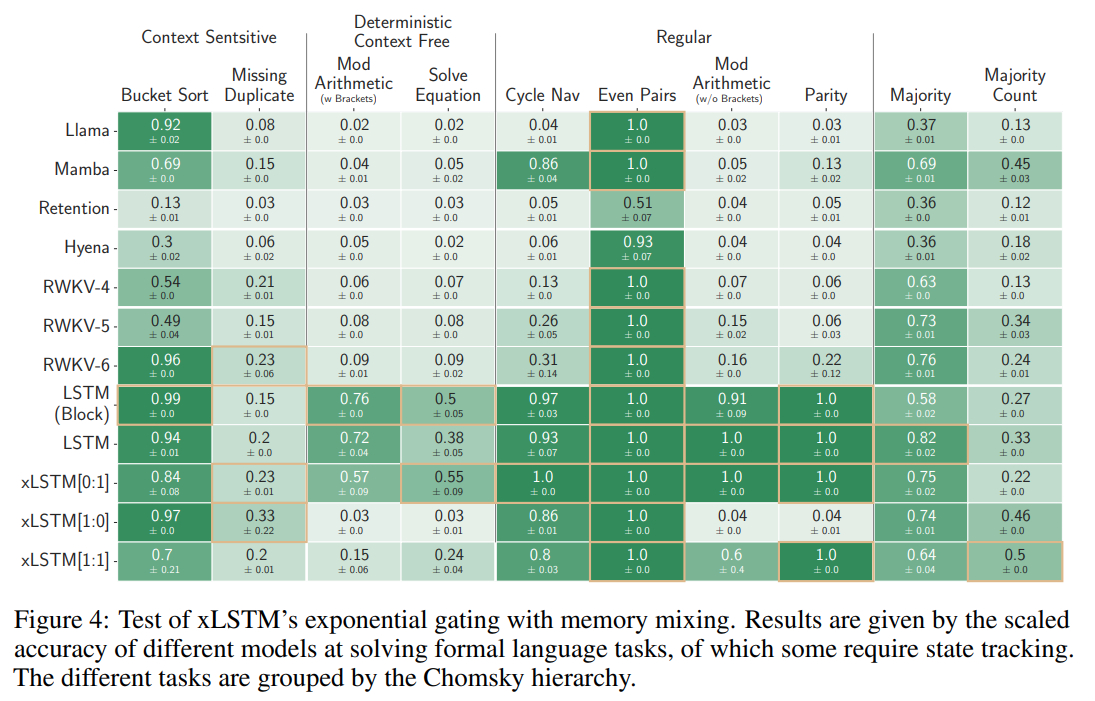
quite a few tasks that the original LSTMs outperforms xLSTMs on
2. DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek-AI
♥ 939 LLM

DeepSeek-V2 vs other Open Source Models
Overview
In LLMs, the performance improves as the model grows larger; however, bigger models require more computation resources at the training stage and can be extremely slow during the inference stage. DeepSeek-V2 aims to fix both of these problems by introducing two new ideas – Multi-head Latent Attention (MLA) and DeepSeekMoE.
MLA
LLMs rely on Attention mechanism, a clever trick that helps them distinguish between two different meaning of the same word (eg. bank vs river bank). This mechanism uses a key-value cache which is used in the inference step – if we can improve the efficiency of this cache, it will speed up our LLMs.
Although other researchers in the past have tried to efficiently store key-value cache by introducing Grouped-Query Attention and Multi-Query Attention, this paper introduces MLA, a better method which outperforms both previous methods by significantly reducing the number of k-v caches during inference.

Image description: Diagram depicting how often the latent vectors are cached in different architectures.
DeepSeekMoE
Another innovation in DeepSeek-V2 is the decoupled Rotary Position Embedding (RoPE) strategy which uses additional multi-head queries and a shared key to carry RoPE; this decoupling allows MLA to perform computations more efficiently during inference.
To reduce the training costs, this paper proposed DeepSeekMoE architecture instead of using feed forward networks in the transformer framework. This approach introduces two key ideas to improve model performance and efficiency:
Segmentation of experts into finer granularity which allows for higher expert specialization and more accurate knowledge acquisition.
Isolation of some shared experts to mitigate knowledge redundancy among routed experts.
The architecture computes the output of each token in the FFN by adding the input to the outputs of two sets of functions. The first set is applied to all inputs, while the second set is applied only to the top-k inputs based on a certain score calculated using a softmax function.

Results
Economical Training: The model reduces training costs by 42.5% compared to its predecessor, DeepSeek 67B, making it more cost-effective to train.
Inference Efficiency: DeepSeek-V2 significantly compresses the Key-Value (KV) cache by 93.3%, leading to 5.76 times increase in maximum generation throughput. This makes the model not only faster but also more resource-efficient during inference.
Extended Context Support: The model can handle a context length of 128K tokens, which is beneficial for tasks requiring long-context understanding.
Open-Source Model Weights: DeepSeek-V2 is fully open-source and free for commercial use – you can either download the DeepSeek-V2 model weights from Hugging Face or use the pay as you go model for as little as $0.28 for 1 million tokens.

DeepSeek-V2 pricing comparison
3. You Only Cache Once: Decoder-Decoder Architectures for Language Models
Sun et al. [Microsoft, Tsinghua University]
♥ 643 LLM

You Only Cache Once (YOCO) vs Standard Transformers
Overview
As we discussed in the previous section, the key-value cache in LLMs is a bottleneck during the inference stage – as the number of tokens increases, the GPU memory consumption also increases leading to slow prefilling times, this makes it difficult to deploy long-context LLMs in practice.
To solve this, the paper introduces YOCO (You Only Cache Once), a decoder-decoder architecture for LLMs that caches key-value pairs only once and reuses them via cross-attention mechanism. This approach significantly reduces GPU memory demands and speeds up the prefill stage, while retaining global attention capability.
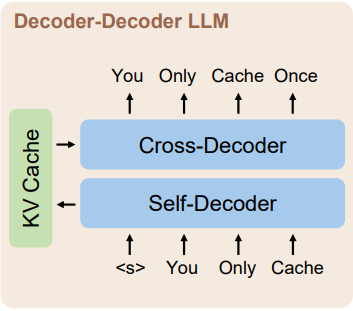
YOCO’s Architecture overview
How Does YOCO work?
The decoder-decoder architecture is a part of the YOCO model, here is how it works:
Self-Decoder: This component generates global key-value (KV) caches using efficient self-attention mechanisms. It encodes the input sequence and produces intermediate vector representations that are used to create KV caches.
Cross-Decoder: Stacked upon the self-decoder, the cross-decoder employs cross-attention to reuse the shared KV caches produced by the self-decoder.
Causal Masking: Both the self-decoder and cross-decoder use causal masking to ensure that the prediction for a certain position only depends on known outputs at previous positions.

The above architecture behaves like a decoder-only Transformer model, which aims to reduce GPU memory demands while retaining global attention capability, this addresses memory consumption in several ways:
Reduced KV Cache Memory: YOCO caches key-value pairs only once, significantly reducing GPU memory demands for KV caches.
Efficient Self-Attention: The self-decoder uses efficient self-attention mechanisms, like sliding-window attention, which require a constant number of KV caches, i.e. O(1) memory complexity, regardless of input length.
Early Exit Prefilling: The model architecture allows for early exit during prefilling, speeding up the process and reducing memory usage.
Results
This decoder-decoder architecture demonstrates substantial reductions in:
GPU memory demands (6.4 times)
Prefilling latency (30.3 times)
Improvements in throughput (9.3 times)
YOCO can scale up in terms of model size, number of training tokens, and context length while maintaining competitive performance even at 1M tokens.
Reply