- The AI Timeline
- Posts
- Chameleon Unifying Vision & Text
In this issue: x4 industry news, x3 AI research papers
May 13th ~ May 19th
🗞️ Industry News in 1 Line
♥ 64k OpenAI released their newest & fastest flagship model called GPT-4o which works with both images as well as text. It is the best multimodal model they have trained so far.
♥ 3.9k During Google I/O, Google announced Veo, an advanced vision-language model; Project Astra, a mode which can interpret things that you show using your mobile camera; and updates to Gemini 1.5 Pro which boost its accuracy and performance in vision-language tasks.
♥ 797 Get ready to be interviewed by an AI. Apriora recently raised $2.8M funding to build an AI interviewer agent which can ask relevant questions and detect when candidates use AI-generated answers to cheat in an interview.
♥ 76k Following the release of GPT-4o’s voice assistant “Sky,” which has an extreme similarity to Scarlett Johansson’s voice, it turns out that OpenAI originally wanted to use her voice, but the actress declined the offer. However, OpenAI still proceeded with a voice that many has recognized as Scarlett Johansson’s. She is now pursuing legal action, and “Sky” was taken down two days after its launch.
1. Chameleon: Mixed-Modal Early-Fusion Foundation Models
Facebook AI Research at Meta [FAIR]
♥ 921 Multimodal LLM

Chameleon’s architecture
Chameleon Overview
The researchers at Meta have introduced Chameleon, a multimodal foundation model that integrates text and images using a novel unified token-based transformer architecture. This approach removes the need for separate encoders/decoders, enabling superior performance in multimodal tasks like visual question answering and image captioning, while maintaining strong results in text-only tasks.
State-of-the-art in image captioning
Comparable with Mixtral 8x7B and Gemini-Pro on text-only tasks
Comparable with Gemini Pro and GPT-4 Vision on a new long-form mixed-modal generation benchmark
How Does Chameleon work?
Image and Text Tokenization
Chameleon uses separate tokenization strategies for images and text. For images, it employs a tokenizer inspired by previous work, encoding a 512x512 image into 1024 discrete tokens drawn from a codebook of size 8192. This image tokenizer particularly focuses on human faces, up-sampling such images during pre-training. However, it faces challenges in accurately reconstructing images containing large amounts of text.
For text, Chameleon uses a Byte Pair Encoding (BPE) tokenizer, creating a vocabulary of 65,536 tokens, which includes the 8192 image codebook tokens. This tokenizer is trained on a diverse subset of textual data to ensure robust performance across various text-related tasks.

Early-Fusion
The text and image embeddings generated in the previous step are combined to form a single sequence of embeddings, which is then fed into the shared transformer model.
The combined embedding is processed through the transformer’s layers, where self-attention mechanisms operate over the entire sequence, allowing the model to learn joint representations that capture relationships within and between modalities.
By processing text and image data together, the model can learn more cohesive and integrated representations, potentially capturing complex interactions between modalities that separate encoders/decoders might miss.
Training Methodology
During training, the Chameleon model uses query-key normalization, which adjusts the scale of query and key vectors in the attention mechanism to ensure balanced contributions from different modalities. This adjustment prevents the model from being overwhelmed by one type of information, enhancing its ability to learn effectively from both text and images.
Additionally, revised layer norms are used to standardize the inputs across layers. This allows the model to better handle mixed data types, such as text and images, during training, ensuring smoother and more stable learning, leading to better convergence.

Editor’s note: The generated image looks very realistic
Chameleon’s Results
Chameleon achieves strong performance across various vision-language tasks and provides a better way for building multimodal models which maintain competitive performance in text-only benchmarks. It outperforms existing models on tasks like image captioning and visual question answering, which shows its effectiveness in multimodal interaction and mixed-modal reasoning.

Chameleon’s benchmark results
2. A Generalist Learner for Multifaceted Medical Image Interpretation
Zhou et al. [Harvard Medical School, Jawaharlal Institute of Postgraduate Medical Education and Research, Scripps Research]
♥ 550 medical AI

A diagram explaining how MedVersa integrates to real-life medical applications.
MedVersa Overview
We have seen ML models being used for assisting in diagnosis for a specific disease but till now, there was no model which could work on a broad range of clinical scenarios. The research paper introduces MedVersa, a versatile medical artificial intelligence system designed to enhance medical image interpretation across various tasks.
This model supports multimodal inputs and dynamic task specification, which allows for comprehensive medical image analysis. To develop and validate MedVersa, the authors created MedInterp, the largest multimodal dataset to date, comprising over 13 million annotated instances across 11 tasks and 3 modalities.
How Does MedVersa Work?
MedVersa was trained on both visual and textual data during training, which helped it develop robust shared representations that enhance task accuracy and mitigate potential data biases. The underlying system is structured around three main components:
Multimodal Input Coordinator: This component handles the diverse input data, including various types of medical images and textual requests. It employs different vision encoders which extract visual tokens that are mapped to the language space via a vision-language adapter, which reduces the number of visual tokens using adaptive pooling and projects the visual representations into the language space.
Large Language Model Based Learnable Orchestrator: The LLM acts as the decision-making hub which determines whether the task can be handled independently or if it requires assistance from the vision modules.
Vision Modules: MedVersa includes several vision modules designed for specific tasks, such as visual detection and 2D/3D visual segmentation. These modules are integrated into the system and can be expanded or replaced as needed to accommodate new advancements in medical imaging and diagnostics. For example, the visual detection module processes visual data directly, while the 2D and 3D segmentation modules use UNet architectures, with the 2D UNet initialized using pretrained ResNet-18 weights.
Unlike traditional medical AI models, MedVersa's integration of the LLM provides a platform that can be updated with new specialist models as medical technology evolves. This modular design ensures the system remains relevant and effective as the technology advances.

MeVersa’s Flowchart
MedVersa’s Applications & Results
Due to its multi-modal nature, the MedVersa can be used a variety of situations such as:
Generating radiology reports
Detecting skin lesion and abdominal organs using image segmentation
Visual question answering
Region of interest captioning
The best part about this model is that it outperforms many state-of-the-art models in accuracy and efficiency on various medical AI tasks, including pathology detection, longitudinal studies, and classification, showcasing its robustness and versatility.

MedVersa’s Architecture
Limitations of MedVersa
Data Quality and Diversity: MedVersa's performance heavily depends on the quality and diversity of its training data. This means that a model trained on data from American patients might not detect diseases in German patients as effectively.
Integration Complexity: Integrating LLMs with vision modules is hard and it will only get more complex as more vision modules are added.
Manageability and Scalability: While MedVersa's dynamic nature allows adapting to new technologies, this makes it difficult to scale it up and increases maintenance cost.
Interpretability and Explainability: The decision-making process of MedVersa involves complex interactions between different AI models, which can obscure the reasoning behind specific diagnostic conclusions. This lack of transparency can make it challenging for medical professionals to fully understand and trust the AI's recommendations.
3. What matters when building vision-language models?
Laurençon et al. [Hugging Face, Sorbonne Université]
♥ 494 VLM

Idefics2-chatty analyzes the table to compute and answer the query
Overview
Vision-language models (VLMs), i.e. models which can handle both images as well as text, are on the rise but how do these models work? Researchers in the past have used advanced techniques without providing justification for using them.
This paper aims to provide justification for critical steps in building such models and verifies their results by developing a model which achieves state-of-the-art performance across various multimodal benchmarks and often matches or outperforms models four times its size.
How Do Vision-language Models Work?
The design of VLMs involves careful consideration of various factors. Let's try to understand some of these design choices and their impacts on performance and efficiency:
Pre-Trained Backbones: VLMs often build upon pre-trained unimodal backbones for both vision and language which significantly influences performance. For instance, replacing a less effective language model backbone with a more powerful one yields substantial performance improvements.
Architecture Comparison: There are several ways to build a VLM architecture – the fully autoregressive and cross-attention architectures are two of the most common approaches. While cross-attention architecture may outperform fully autoregressive with frozen backbones, the latter excels when training the backbones.
Efficiency Gains: You can improve the performance of an LLM by using strategies like learned pooling, reducing the number of visual tokens, and preserving the original aspect ratio as well as resolution of images.
Trade-off between Compute and Performance: Splitting images into sub-images during training provides better performance at the time of inference but it reduces compute efficiency. This strategy proves particularly beneficial for tasks involving text extraction from images.

Idefics2’s fully-autoregressive architecture
The researchers used the above findings to develop a model called Idefics2 and trained it using the following steps:
Multi-Stage Pre-Training: Idefics2 starts from pre-trained unimodal backbones (SigLIP-SO400M and Mistral-7B-v0.1) and is trained on:
Interleaved image-text documents from the OBELICS dataset.
Image-text pairs from human-annotated and web-scale sources, with synthetic captions to improve data quality.
OCR data from PDF documents, including industry documents and rendered text to enhance OCR capabilities.
Training Strategy: The pre-training process is divided into two stages.
In the first stage, the model is trained with a lower image resolution and a large global batch size.
In the second stage, higher-resolution PDF documents are introduced, requiring adjustments in batch size and memory management.
Instruction Fine-Tuning: After pre-training, the model undergoes instruction fine-tuning using a diverse collection of vision-language datasets covering various tasks. Researchers also used various techniques such as noise injection, random image resolution scaling, and data shuffling to avoid over-fitting.
Idefics2’s Results
In this paper, researchers were able to explain the rationale behind some of the common steps taken when building a VLM. The model built by using these findings was able to outperform many state of the art models on different benchmark datasets.
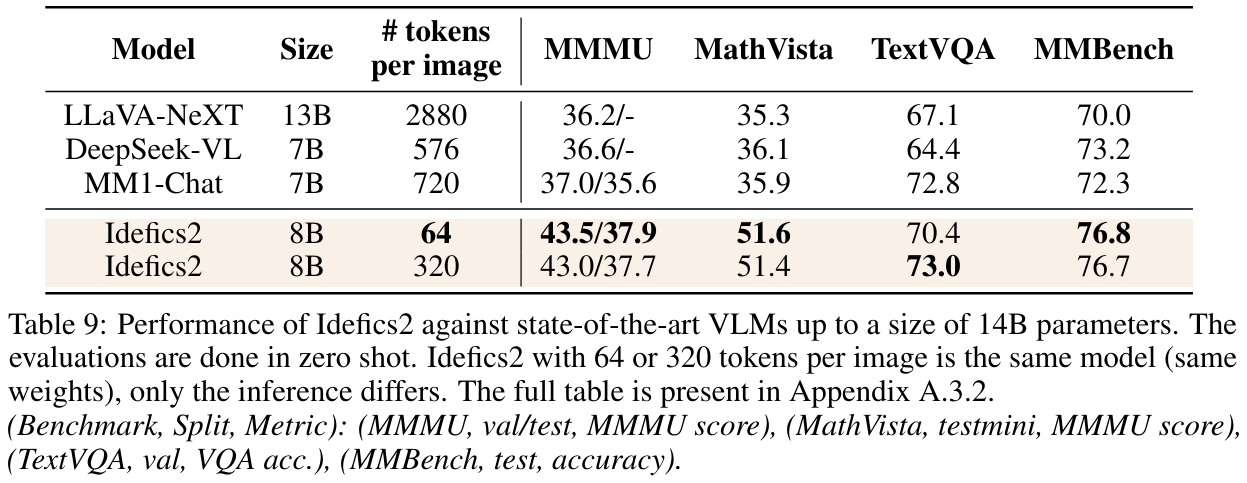
Performance of Idefics2 (zero-shot) against SoTA VLMs up to a size of 14B parameters.
Reply