- The AI Timeline
- Posts
- Autoregressive models in Data-Constrained Settings
Autoregressive models in Data-Constrained Settings
Plus more on Group Sequence Policy Optimization and "AlphaGo Moment" for Model Architecture Discovery...?
by cloud
July 29, 2025
July 21st ~ July 27th
#66 Latest AI Research Explained Simply
🗞️ Industry News in 1 Line
♥ 5.2k Chinese tech giant Alibaba has announced its entry into wearables with the Quark AI Glasses, which directly embed the firm's advanced Qwen AI assistant into the hardware. These glasses are going to be released in late 2025 and will offer hands-free calling, music streaming, real-time language translation, and meeting transcription. The glasses also feature a built-in camera.
♥ 1.5k Anthropic has published a new blog post on autonomous auditing agents that not only scale the search for AI alignment failures but also solve a key validation problem in safety research. These "auditing agents" successfully uncovered intentionally planted flaws in testing and are now being used to help vet the safety of frontier models like Claude 4.
♥ 11k Tencent has just open-sourced Hunyuan3D, the industry's first model that can generate entire interactive 3D worlds from a single sentence or image. This new model can transform workflows in game development and VR, and because it's fully open-source, you can dive into the code or download model weights for yourself.

Move Fast, Ship Smart with Korbit AI

At Korbit, we know speed and quality go hand‑in‑hand. Our AI‑powered code review and engineering insights platform gives your team:
Instant, Context‑Aware Feedback on every PR - catch critical issues before they hit production
Automated PR Summaries so reviewers spend time fixing, not guessing
High Signal‑to‑Noise Reviews tuned to your codebase and standards
Actionable Team Insights on review velocity, compliance, and quality trends
Join hundreds of engineering leaders already using Korbit to unblock bottlenecks, enforce coding standards, and upskill their devs in real time.
Ready to see Korbit in action?
Group Sequence Policy Optimization
Zheng et al. [Qwen Team, Alibaba Inc.]
♥ 1.4K LLM Reasoning bycloud’s pick
Introduction to Group Sequence Policy Optimization (GSPO)
Reinforcement learning helps large language models tackle complex problems like advanced math and coding. However, existing methods like GRPO become unstable with massive models, which ends up causing catastrophic failures during training.
The biggest problem is that GRPO uses token-level importance ratios that create noisy gradients, especially in long responses or sparse models like Mixture-of-Experts (MoE).
In this paper, the researchers have introduced Group Sequence Policy Optimization (GSPO), a new algorithm that replaces token-level adjustments with sequence-level optimization, promising stability and efficiency.
How Group Sequence Policy Optimization (GSPO) works
GSPO rethinks reinforcement learning by aligning optimization with how rewards are given: at the sequence level, not per token. For a group of responses to the same query, a single importance ratio is calculated based on the entire sequence likelihood. This ratio, normalized by response length, measures how much the current policy deviates from the old one. Rewards are then compared relatively within the group, similar to GRPO, but applied uniformly to all tokens in a response.
Unlike GRPO, which weights each token’s gradient by its individual importance ratio, GSPO assigns equal weight to every token in a sequence. This avoids the high variance from fluctuating token-level ratios, which destabilizes training. For cases needing token-level rewards (like multi-turn dialogues), GSPO-token, a variant, adjusts advantages per token while mathematically matching the sequence-level approach. Additionally, GSPO clips entire responses, not tokens, ensuring only representative samples guide updates.

Group Sequence Policy Optimization (GSPO) Algorithm
This sequence-first design naturally handles challenges like MoE volatility, where experts activate inconsistently across updates. By focusing on overall sequence likelihood instead of token-level probabilities, GSPO sidesteps the noise that cripples GRPO in sparse models.
Results and implications of Group Sequence Policy Optimization (GSPO)
GSPO outperforms GRPO in stability, efficiency, and benchmark performance. Tests on a Qwen3-30B model showed higher training rewards and superior results on coding benchmarks (AIME’24, LiveCodeBench, CodeForces) using the same compute.
Notably, it stabilized MoE training without GRPO’s workaround (Routing Replay), which forced expert consistency at extra cost. GSPO also clipped over 100× more tokens than GRPO yet trained faster, proving token-level gradients in GRPO are inefficiently noisy.

These gains contributed to the improved Qwen3 models. GSPO’s sequence-level logic also simplifies infrastructure: it could allow inference engines (like vLLM) to supply likelihoods directly, skipping recomputation during training.
Diffusion Beats Autoregressive in Data-Constrained Settings
Prabhudesai et al. [Carnegie Mellon University]
♥ 977 DiffusionLM
Introduction to Data-Constrained Language Modeling
In the age of AI, data is often referred to as “New Oil” and rightfully so. Training large language models frequently hits a roadblock as high-quality data is becoming scarce. While computing resources grow steadily, datasets like those from healthcare or robotics remain limited. This creates a challenge for standard autoregressive (AR) models, which predict text left-to-right.
They struggle when trained repeatedly on small datasets, saturating quickly after a few epochs. However, new research reveals that masked diffusion models, which corrupt and reconstruct text in random orders, excel where data is sparse but compute is abundant. Let’s explore why.
Inner Workings of Masked Diffusion
Unlike AR models that follow a fixed left-to-right sequence, masked diffusion treats text generation like solving a jigsaw puzzle. For each training example, it:
Randomly masks tokens (e.g., replacing words with
[MASK]),Trains the model to reconstruct the original text from these masked versions.
This process exposes the model to countless prediction tasks. Imagine predicting the word “apple” in the sentence “An ___ a day keeps the doctor away” versus “An ___ fell from the tree.” The context changes dynamically. This randomness acts as implicit data augmentation, letting the model learn robust patterns from repeated data.

Meanwhile, AR models see only one task: predicting the next word in a rigid sequence. Their fixed approach limits their ability to extract new insights from recycled data. Diffusion’s flexibility, enabled by bidirectional attention (seeing all unmasked tokens), allows deeper learning over hundreds of epochs without overfitting.
Evaluation and Scaling Insights
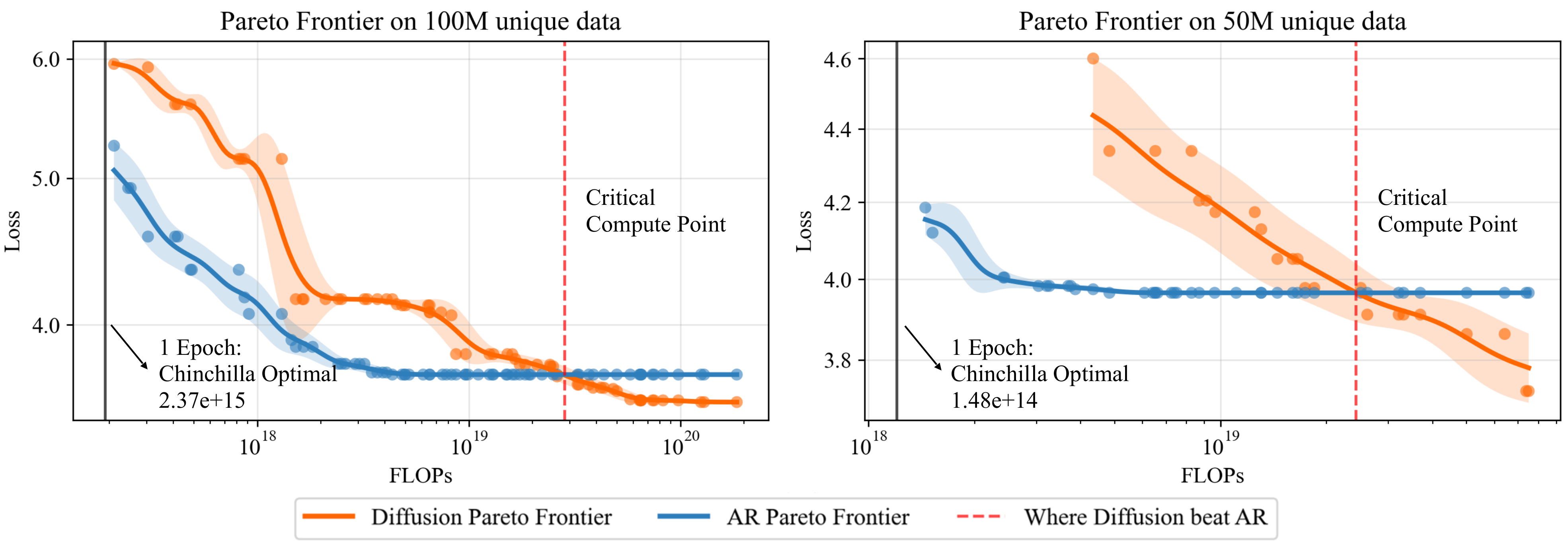
In tests with datasets as small as 25M–100M unique tokens, diffusion models surpassed AR models once compute exceeded a critical threshold. Key findings:
Efficiency: AR models peaked at ~50 epochs before overfitting, while diffusion models improved consistently for 500+ epochs.
Scaling Law: The compute needed for diffusion to outperform AR follows a power law:
C ∝ U²·¹⁷⁴(where U = unique tokens). For example, with 100M tokens, diffusion wins after ~1.5e²⁰ FLOPs.Downstream Gains: On benchmarks like SciQ and Lambada, diffusion achieved up to 10% higher accuracy than AR models when both reused limited data.

Results for the best auto-regressive and diffusion models trained in different data-constrained settings.
This signals a paradigm shift: for data-scarce domains (e.g., specialized medical text), diffusion could become the go-to approach. Future work may explore hybrid AR-diffusion architectures to balance compute and data efficiency. As datasets plateau, innovations like this will be vital to keep pushing AI forward.
AlphaGo Moment for Model Architecture Discovery
Liu et al. [Shanghai Jiao Tong University, SII, Taptap, GAIR]
♥ 2.9K LLM Training

Introduction to ASI-ARCH
AI capabilities are advancing rapidly, and many human researchers can’t keep up. This creates a bottleneck: while AI systems grow exponentially stronger, research progress remains limited by human cognitive capacity. The paper introduces ASI-ARCH, the first artificial superintelligence system for AI research.
It tackles neural architecture discovery, a field where breakthroughs like Transformers historically required years of human effort. ASI-ARCH overcomes this by enabling AI to autonomously generate, test, and refine novel architectures without human-defined constraints, shifting from optimization to true innovation.

Inner workings of ASI-ARCH
ASI-ARCH operates through a closed-loop system with three specialized agents. First, the Researcher proposes new architectures. It selects parent designs from top-performing historical candidates and modifies them using insights from a dynamic knowledge base. This includes both human literature summaries and the system’s own experimental data.
Most importantly, the Researcher also implements code directly, avoiding gaps between design and execution. Before proceeding, a novelty check ensures ideas are original, while sanity tests prevent flawed implementations like quadratic complexity.

ASI-Arch autonomous research framework demonstrating AI’s capability to conduct end-to-end scientific discovery, from hypothesis generation to empirical validation.
Next, the Engineer trains and evaluates proposals. Unlike traditional methods that discard failing code, ASI-ARCH self-debugs: if training crashes, error logs are fed back to the Engineer for iterative fixes. A real-time monitor halts inefficient runs, like models taking 3× longer than peers. After training, an LLM-as-judge scores architectures qualitatively, weighing novelty, complexity, and efficiency alongside quantitative metrics like loss reduction.
Finally, the Analyst distills insights. It compares each architecture’s performance against its “parent” and “siblings” in an evolutionary tree, mimicking scientific ablation studies. These insights feed back into the Researcher’s knowledge base. To manage computational costs, ASI-ARCH uses a two-stage strategy: lightweight exploration (20M parameters) identifies promising candidates, followed by rigorous verification at full scale (340M+ parameters).
Evaluation and results of ASI-ARCH
In testing, ASI-ARCH ran 1,773 autonomous experiments over 20,000 GPU hours. It discovered 106 state-of-the-art linear attention architectures, surpassing human-designed baselines like DeltaNet and Mamba2. Key results showed consistent improvements: on language tasks like WikiText perplexity and commonsense reasoning (BoolQ, ARC), ASI-ARCH’s top models achieved up to a 48.51 average score versus 47.84 for the best baseline. Notably, five standout architectures, including PathGateFusionNet and ContentSharpRouter, demonstrated unique innovations like hierarchical routing and parallel sigmoid gates.

Performance indicators showing steady improvement in benchmark scores and consistent reduction in loss values, with composite fitness scores demonstrating rapid initial improvement followed by gradual plateau.
A key finding was the scaling law for scientific discovery: the number of breakthroughs grew linearly with compute (Fig. 1). This transforms research from a human-limited to computation-scalable process. Analysis revealed that top architectures relied heavily on empirical insights from past experiments (44.8% of design choices) rather than just prior literature. However, limitations exist. The system favored established components like gating mechanisms, and its fitness function’s sigmoid transform capped score gains from large improvements.
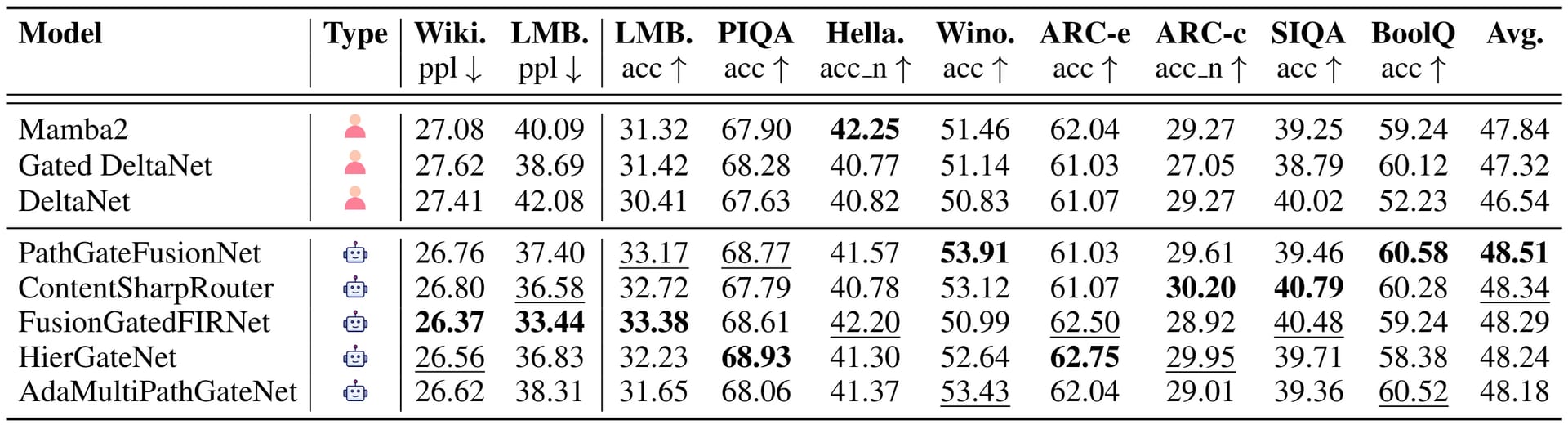
Performance comparison of 5 selected novel linear attention architectures discovered by ASI-Arch.
ASI-ARCH demonstrates that AI can autonomously drive architectural innovation, with emergent principles, like AlphaGo’s “Move 37”, surpassing human intuition. They also open-sourced all code and architectures, with the team invites broader exploration.
Current Critics on Claims of "Artificial Superintelligence"
SJTU researchers claim this as "Artificial Superintelligence" for neural architecture search, but critics on alphaXiv are pushing back due to the following reasons:
Potential AI-generated sections detected throughout the paper
Methodological contradiction: critiques benchmarks while using them
"Buzzword maxxing" with inflated terminology
Community calls the work’s title "shameless" and inconsistent
🚨This week's top AI/ML research papers:
- GSPO
- Diffusion Beats Autoregressive in Data-Constrained Settings
- Gemini 2.5 Pro Capable of Winning Gold at IMO 2025
- Rubrics as Rewards
- Deep Researcher with Test-Time Diffusion
- Learning without training
- Stabilizing Knowledge,— The AI Timeline (@TheAITimeline)
1:16 PM • Jul 27, 2025
Reply