- The AI Timeline
- Posts
- Dynamic Chunking, Small Batch Size Training, and more...
Dynamic Chunking, Small Batch Size Training, and more...
Dive into the latest AI research and industry news, featuring Pollen Robotics' Reachy Mini, Grok 4's launch, and groundbreaking developments in open-source robotics and AI technologies.
by cloud
July 16, 2025
July 7th ~ July 13th
#64 Latest AI Research Explained Simply
🗞️ Industry News in 1 Line
♥ 5.2k The Pollen Robotics team at Hugging Face has introduced Reachy Mini, an open-source desktop robot designed for creative coding, AI experimentation, and human-robot interaction.
The robot encourages community engagement by supporting Python programming, multimodal sensing, and integration with Hugging Face models, making it accessible for developers, educators, and enthusiasts worldwide.

♥ 30k Elon Musk had a pretty busy week as xAI has launched Grok 4, a new iteration of its chatbot, just days after the tool sparked controversy with offensive messages. Elon also announced a $200 million U.S. Department of Defense contract to provide AI services through its Grok model for Government program, as part of a broader federal initiative to accelerate national security AI adoption.
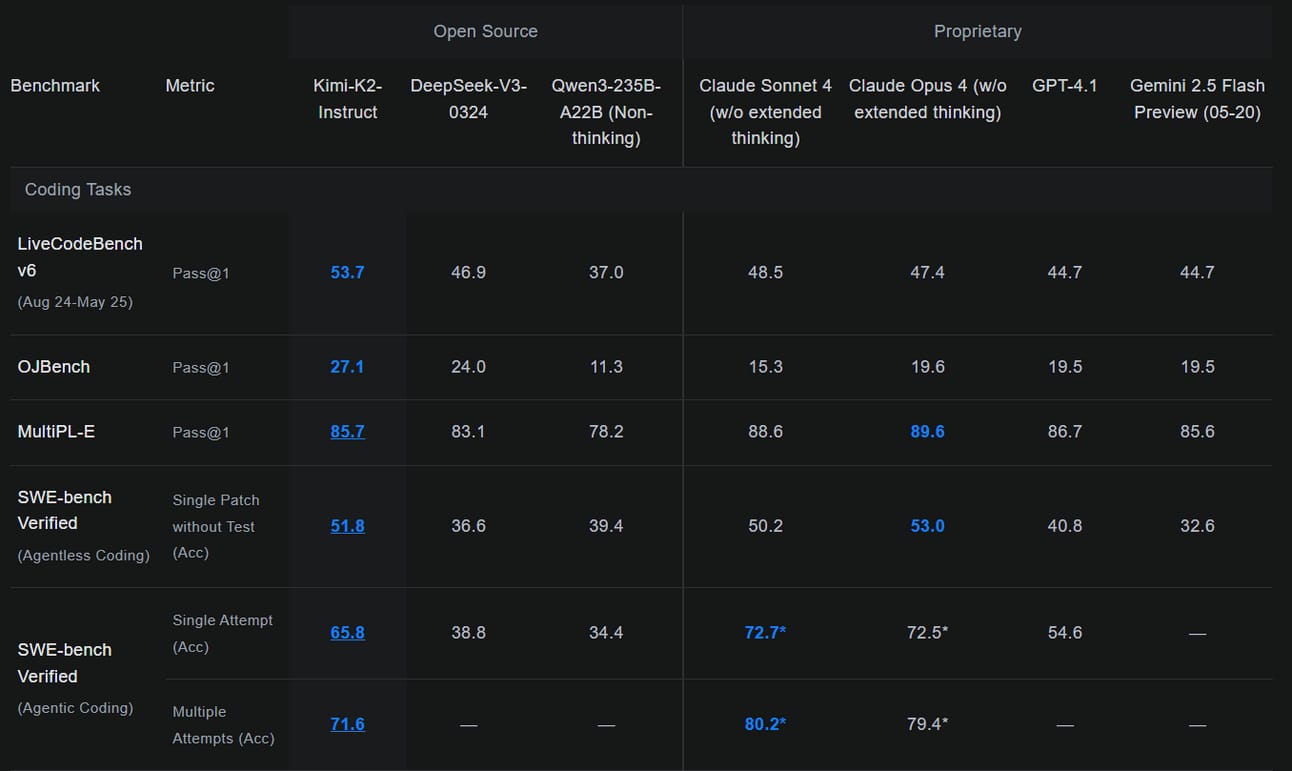
♥ 6.5k Kimi K2 is a new Mixture-of-Experts model with 32 billion active parameters and 1 trillion total parameters. Is has state-of-the-art capabilities in knowledge, math, and code with reflex-grade agentic performance.
Developers and researchers can now access Kimi-K2 via API or download Kimi-K2-Instruct weights from HuggingFace.
Support My Newsletter
As I aim to keep this newsletter free forever, your support means a lot. If you like reading The AI Timeline, consider forwarding it to another research enthusiast, It helps us keep this up for free!
Dynamic Chunking for End-to-End Hierarchical Sequence Modeling
Hwang et al. [Carnegie Mellon University, Cartesia AI]
♥ 1.1k LLM Chunking
Introduction to End-to-End Sequence Modeling Without Tokenization
Language models rely on tokenization, which is a handcrafted preprocessing step that converts raw text into predefined chunks. This tokenization step creates barriers for true end-to-end learning as it limits character-level understanding and struggles with languages lacking clear segmentation cues.
This paper introduces the H-Net architecture which addresses this issue by introducing dynamic chunking, a method that learns to segment raw data (like bytes) into meaningful units during training. This replaces the traditional tokenization-LM-detokenization pipeline with a single hierarchical model, enabling more robust and efficient learning directly from unprocessed inputs.
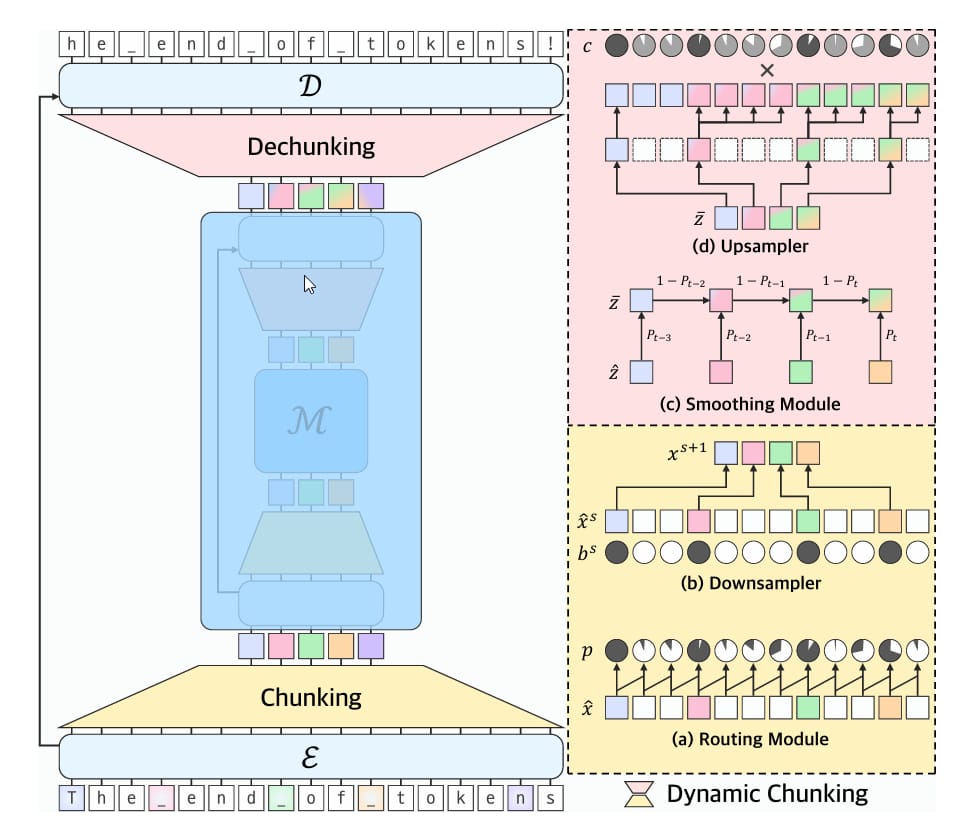
Architectural overview of H-Net with a two-stage hierarchical design (𝑆=2)
Inner Workings of H-Net
H-Net processes data through a U-Net-like hierarchy with three core components. First, a lightweight encoder network handles fine-grained details from raw inputs. Second, a main network operates on compressed representations, resembling tokens but learned dynamically. Third, a decoder network reconstructs the original sequence resolution. The key innovation is the dynamic chunking mechanism between these stages.
A routing module predicts boundaries between adjacent elements using cosine similarity: when consecutive vectors differ significantly (e.g., at word breaks), it flags a boundary. This replaces fixed heuristics with context-aware decisions. A downsampler then compresses sequences by retaining only boundary-marked vectors, shortening the sequence for efficient processing in the main network.
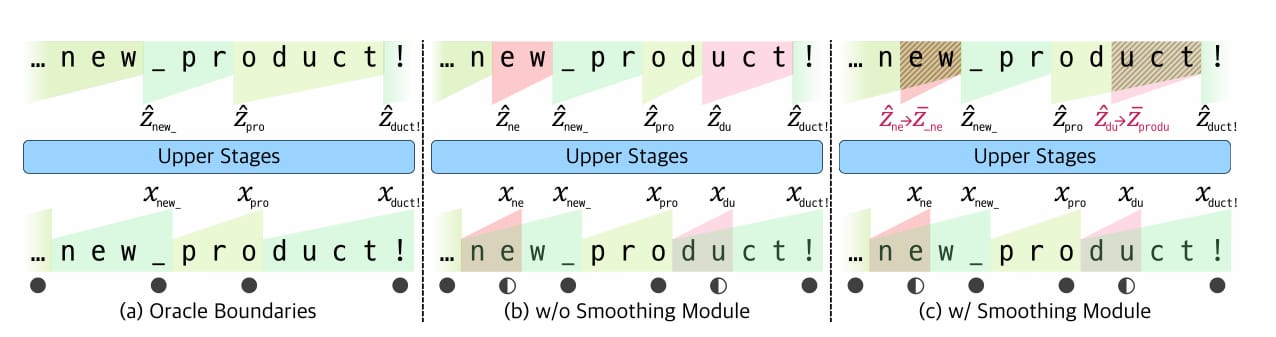
Comparison of decompression strategies on the example sequence
To overcome training instability from discrete boundary decisions, a smoothing module interpolates uncertain chunks using weighted combinations of neighboring vectors. This maintains gradient flow during backpropagation. Additionally, a ratio loss function ensures balanced compression, preventing trivial solutions like retaining all inputs or over-compressing.
Evaluation and Impact of H-Net
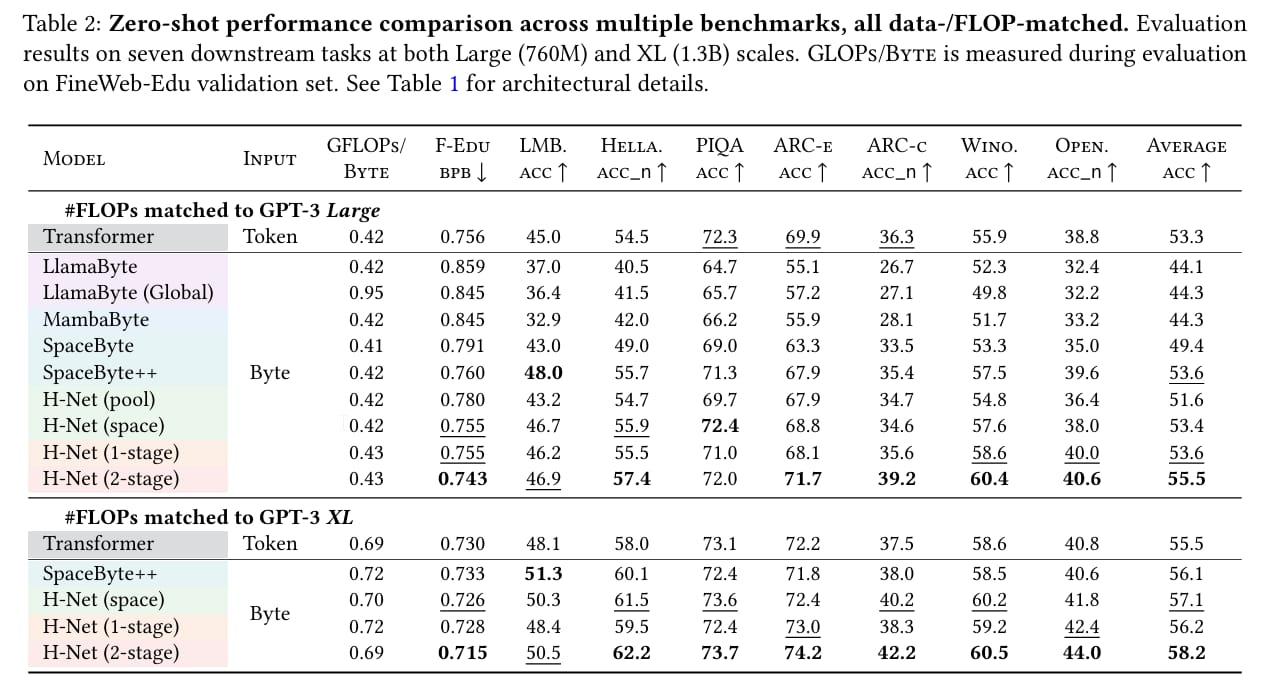
H-Net outperforms token-based models across multiple benchmarks when matched for compute. On English text, a single-stage byte-level H-Net surpasses BPE-tokenized Transformers in perplexity and downstream tasks. With two hierarchical stages, it matches the performance of Transformers twice its size after just 30B training bytes.
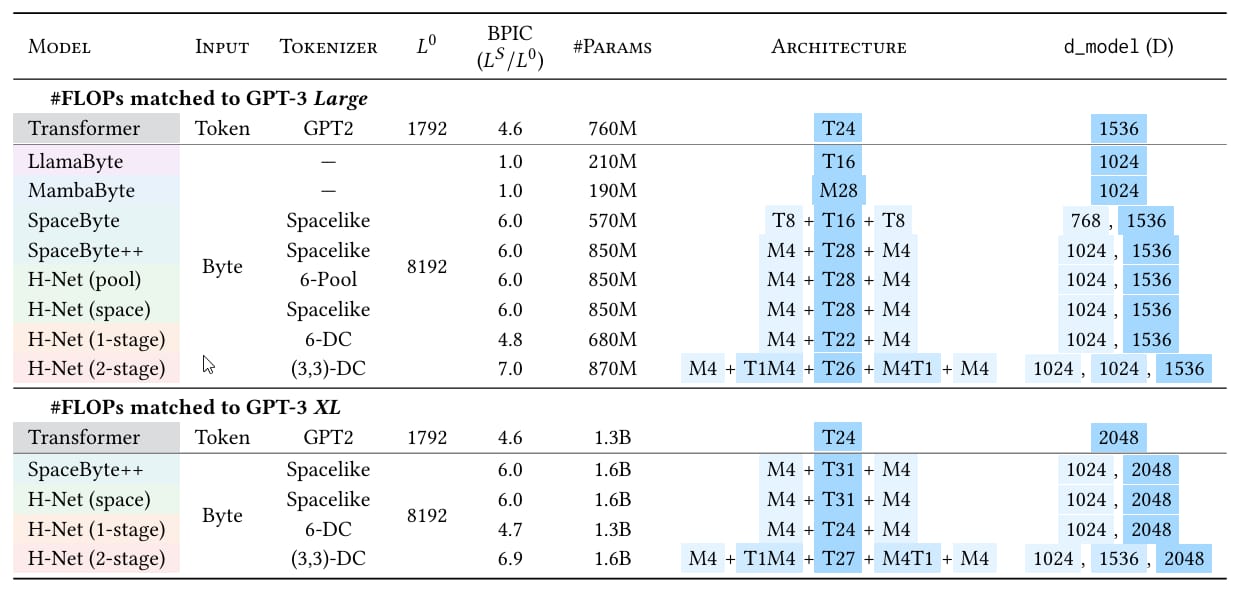
Architectures for main language models, all data-/FLOP-matched.
The model shows significant gains on noisy text benchmarks and languages with weak tokenization heuristics. For Chinese and code, it improves accuracy by 6.4 points on XWinograd-zh; for DNA sequences, it achieves nearly 4× better data efficiency. Learned boundaries align with linguistic units (e.g., morphemes), validating its ability to discover structure without supervision.
Energy-Based Transformers are Scalable Learners and Thinkers
Gladstone et al. [UVA, UIUC, AmazonGenAI, StanfordUniversity, Harvard University]
♥ 3.9k Transformers
Introduction to Energy-Based Transformers
Current AI models excel at quick, intuitive tasks but struggle with complex problems requiring deeper reasoning. This gap is known as System 2 Thinking. Currently, the AI researchers often rely on specific domains like math or coding, which need extra supervision, or can't adapt computation dynamically.
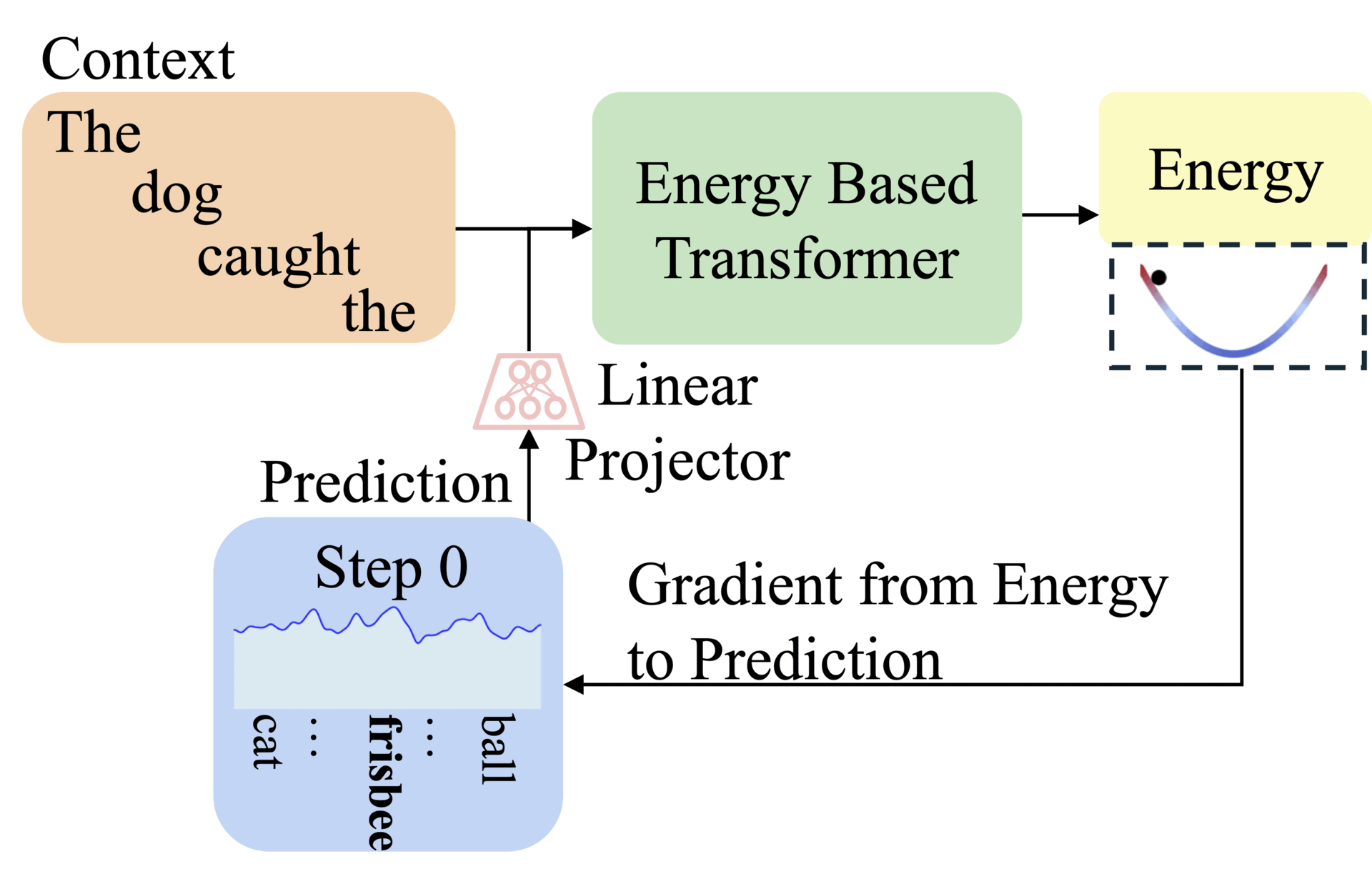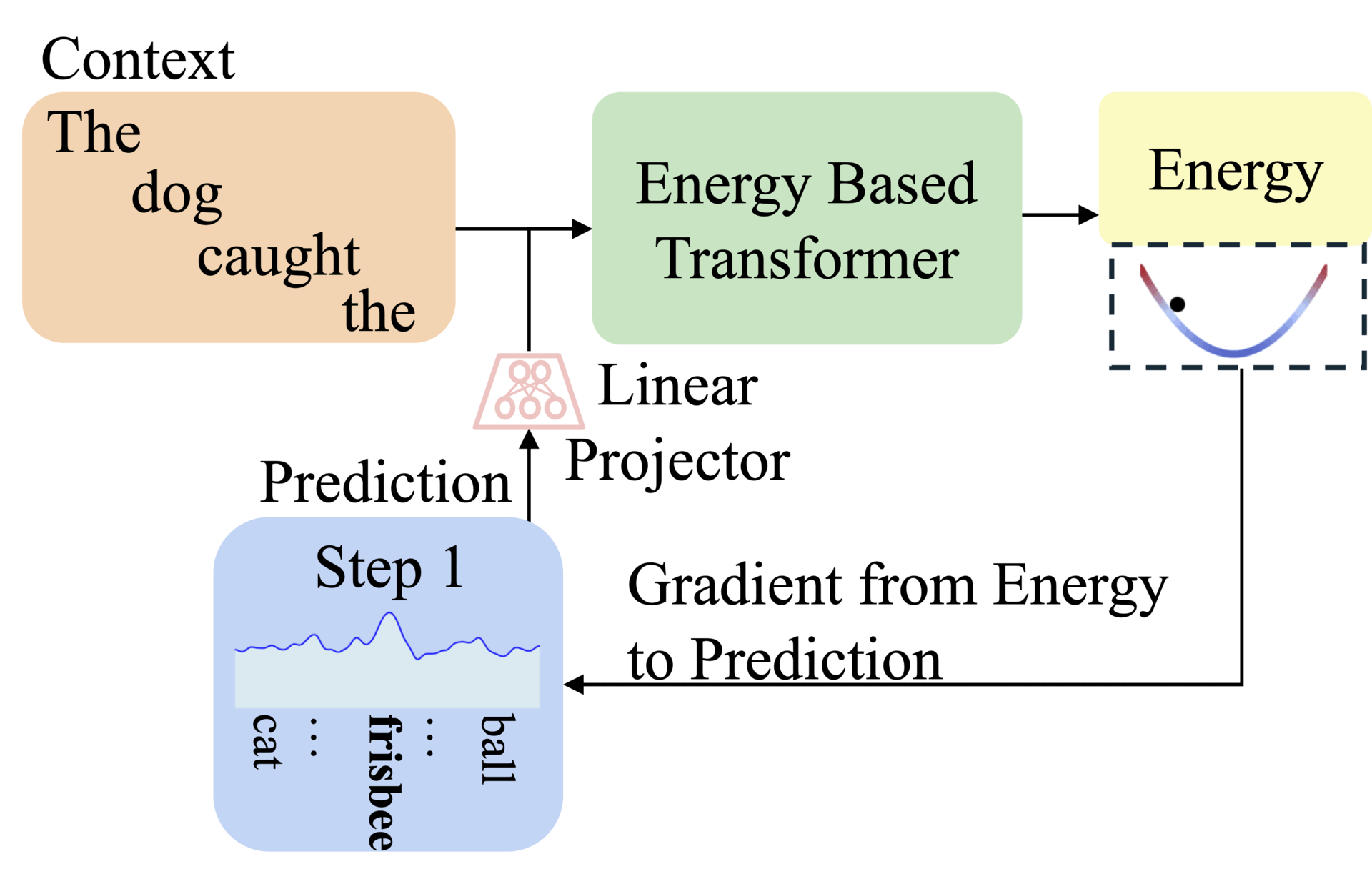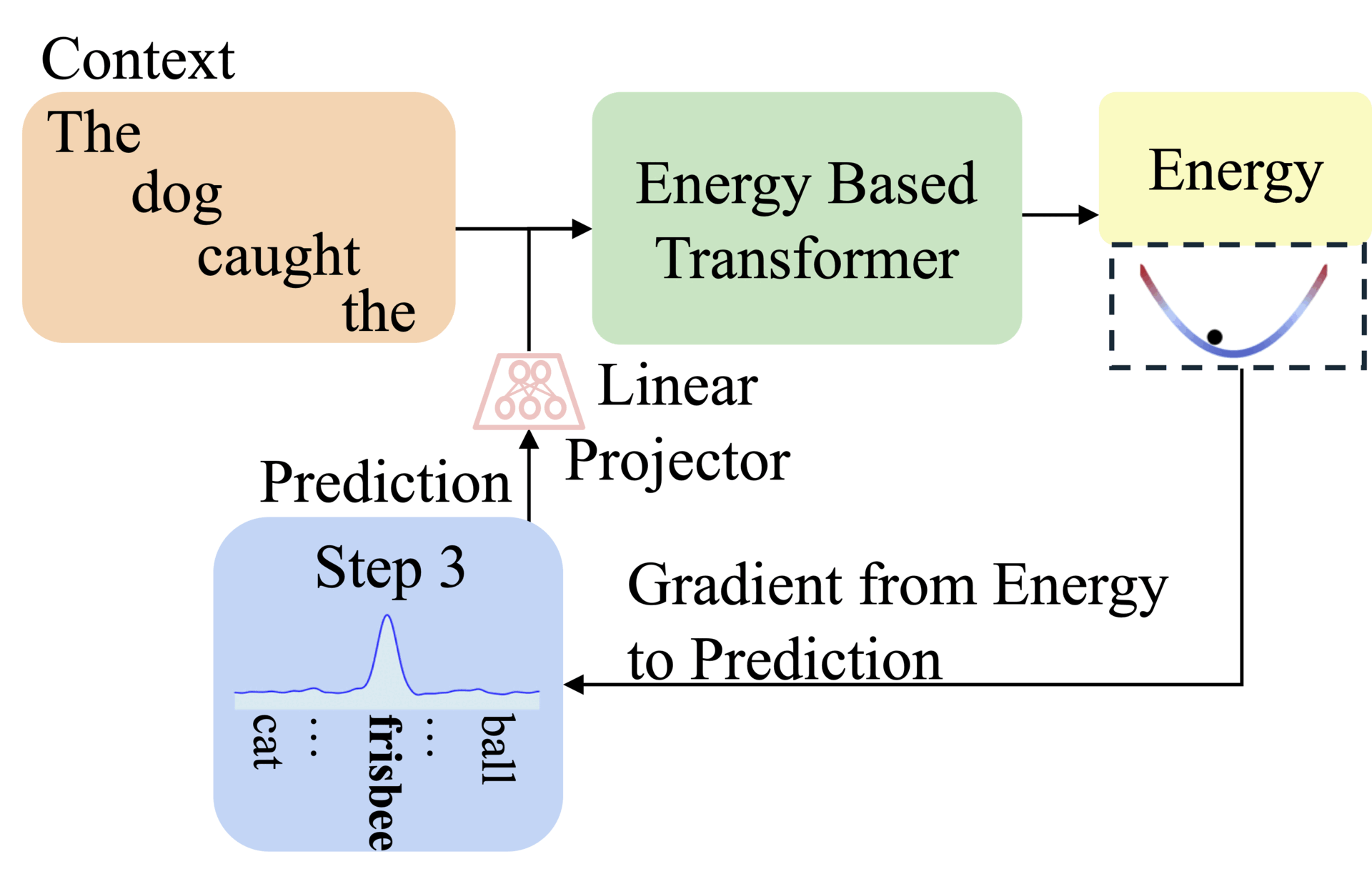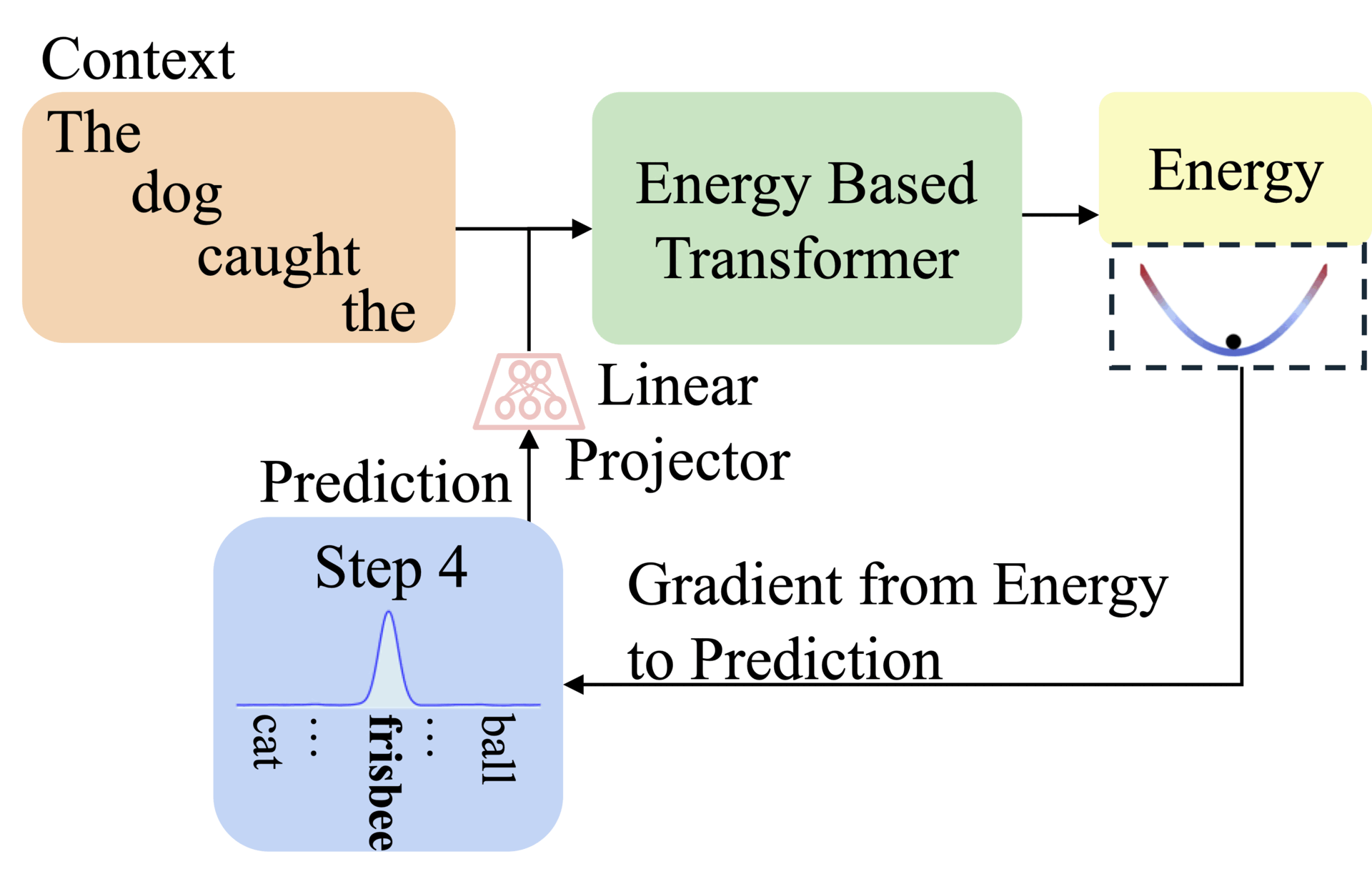
This paper introduces energy-Based Transformers (EBTs) to tackle this by learning entirely from unsupervised data. Instead of generating answers directly, EBTs train a verifier that scores input-prediction compatibility. Predictions start random and refine iteratively via energy minimization, which enables flexible thinking across text, images, and other modalities.
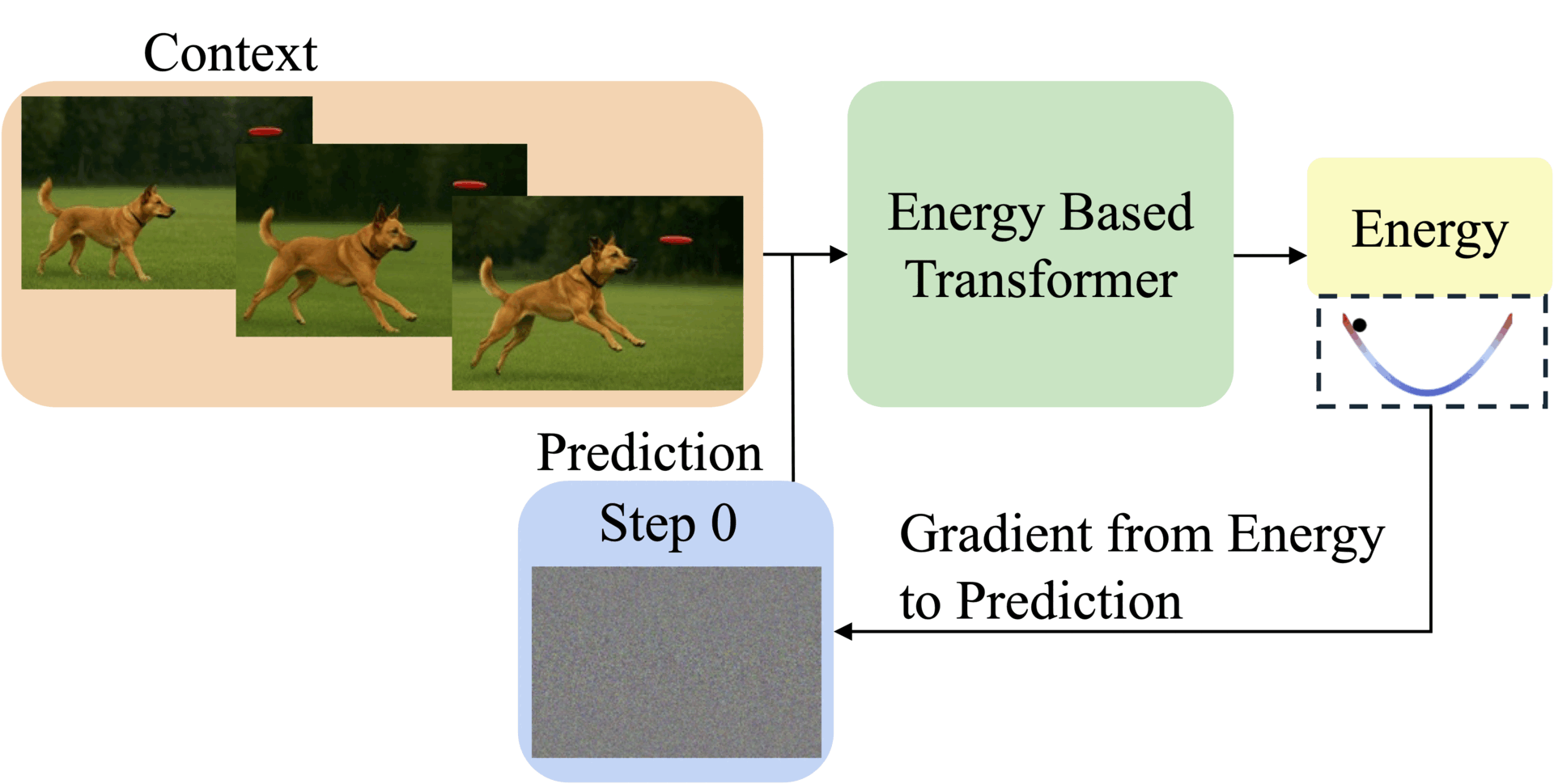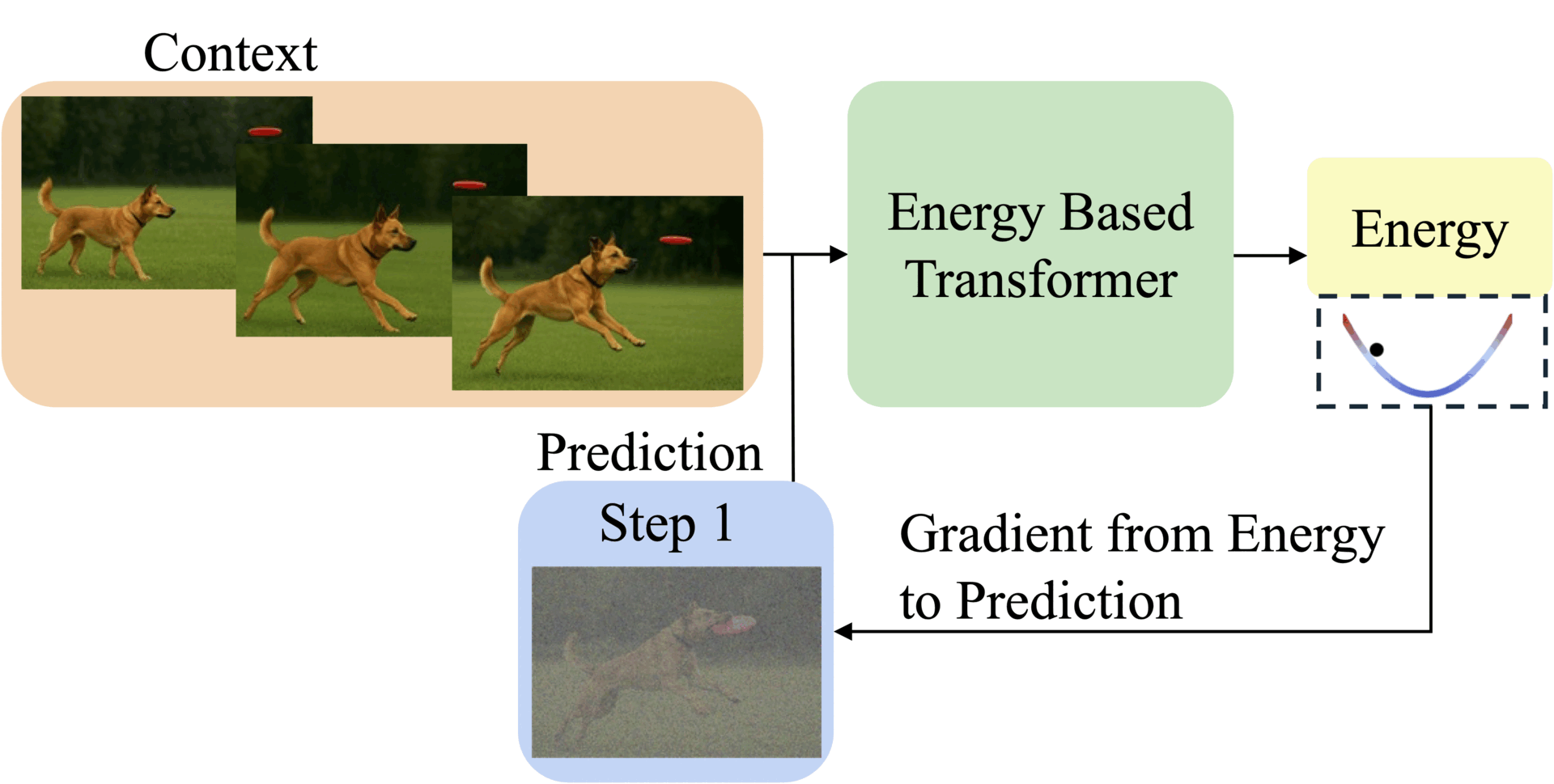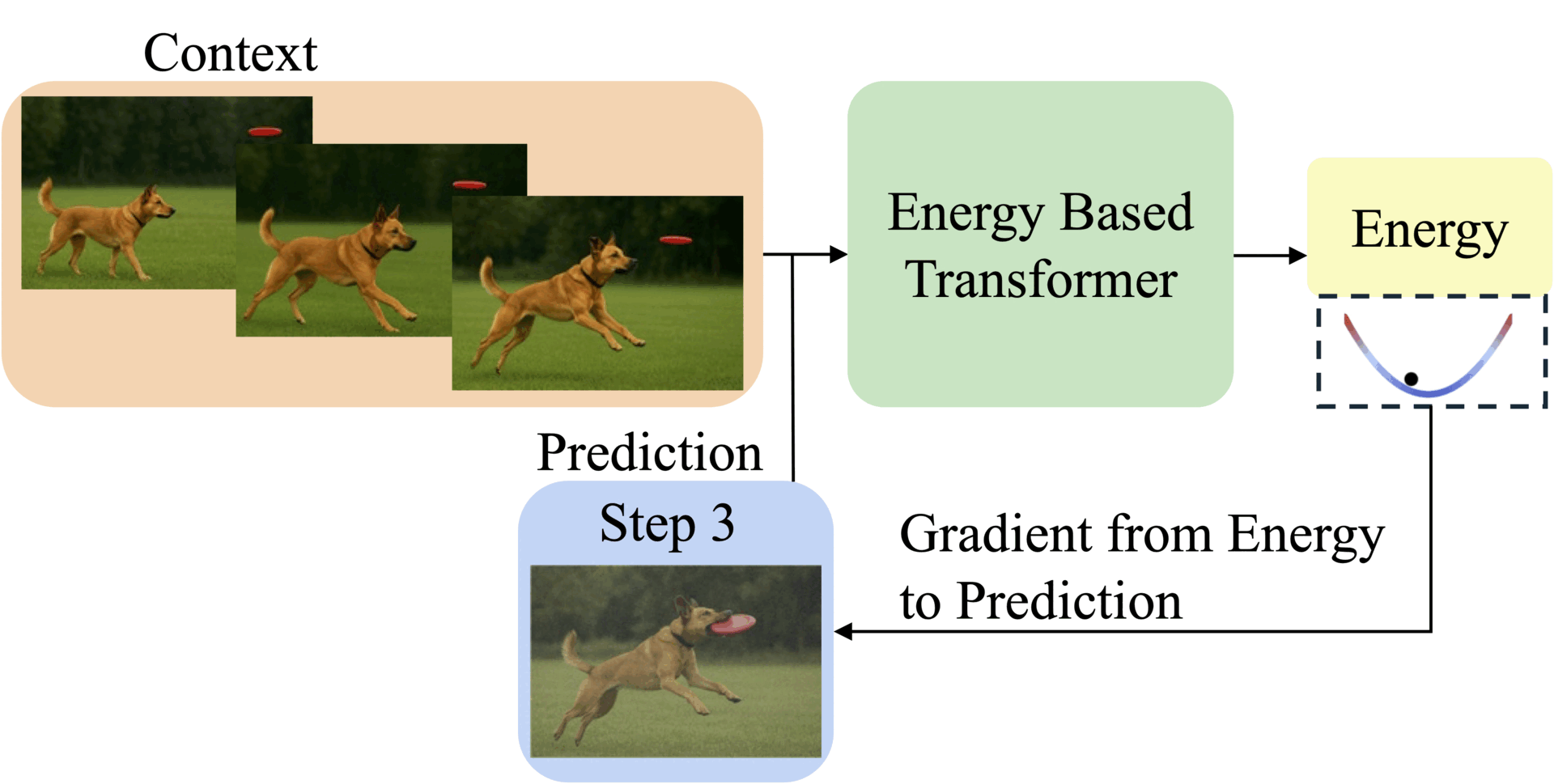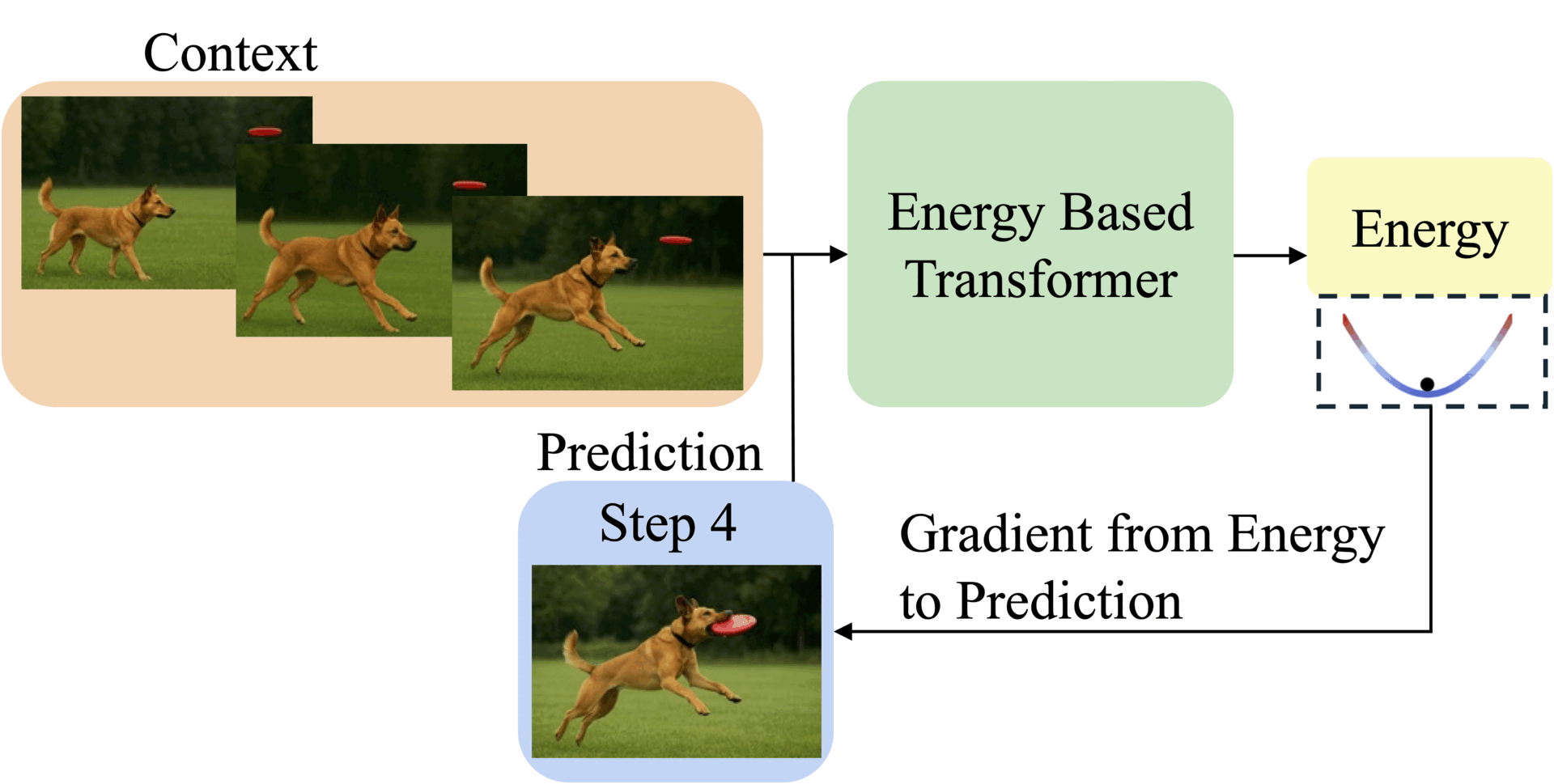
Thinking Processes visualized as energy minimization for autoregressive EBTs.
Inner working of Energy-Based Transformers
EBTs assign an energy value to input-prediction pairs, where lower energy means higher compatibility. During training, they start with random predictions and iteratively adjust them using gradient descent to minimize energy. This process mimics human deliberation: harder problems require more refinement steps (dynamic compute), while the energy score itself signals prediction confidence (uncertainty modeling) and correctness (verification). Three regularization techniques ensure stable learning: a replay buffer stores past optimization paths, Langevin dynamics add noise to explore solutions, and randomized step sizes prevent overfitting.
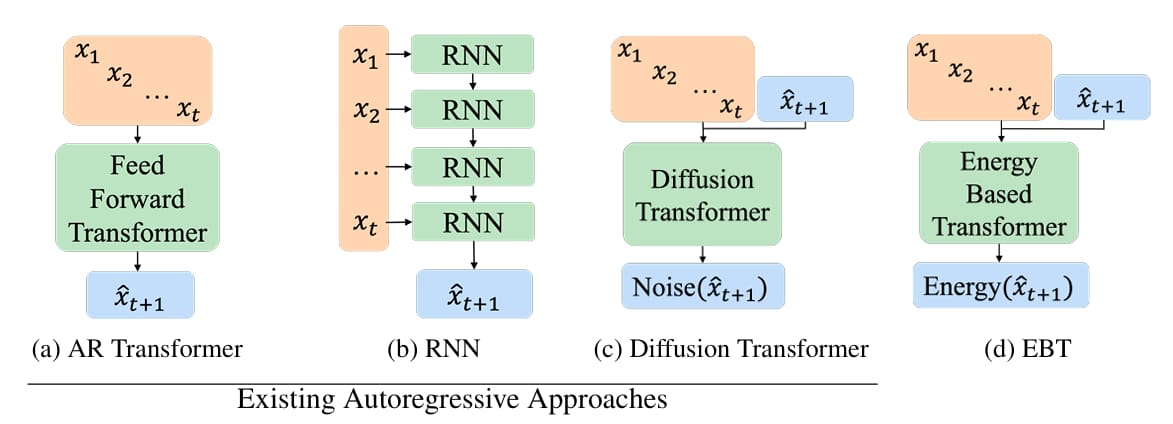
Autoregressive Architecture Comparison.
Unlike autoregressive models that fix computation per token, EBTs adjust effort per prediction. For example, predicting common words like "the" converges quickly, while niche terms like "fox" need more steps. The architecture uses transformer blocks for parallel processing, with decoder-only (for text) and bidirectional variants (for images). Crucially, EBTs unify verification and generation in one model, avoiding adversarial training.
Evaluation and results of Energy-Based Transformers
EBTs outperform traditional transformers and diffusion models across key benchmarks. During pretraining, they scale 35% faster in data efficiency, batch size, and model depth. In language tasks, extra computation ("thinking longer") improved perplexity by 29% more than transformers, while self-verification (choosing the best prediction) boosted gains by 10–14%. For image denoising, EBTs surpassed diffusion transformers using 99% fewer forward passes. Most importantly, performance improvements were largest on out-of-distribution data, which highlights better generalization.

It performs well on many benchmarks but it has a few limitations including training instability from high-dimensional energy landscapes. However, using regularization techniques can mitigate this to some extent.
Small Batch Size Training for Language Models: When Vanilla SGD Works, and Why Gradient Accumulation Is Wasteful
Marek et al. [New York University, Columbia University]
♥ 730 LLM Training bycloud’s pick
Introduction to Small Batch Training for Language Models
Language model training often relies on large batch sizes for stability, and researchers frequently use techniques like gradient accumulation to simulate even larger batches. This approach requires complex optimizers like Adam and consumes significant memory. But what if we could achieve better results with tiny batches, even as small as one example at a time?
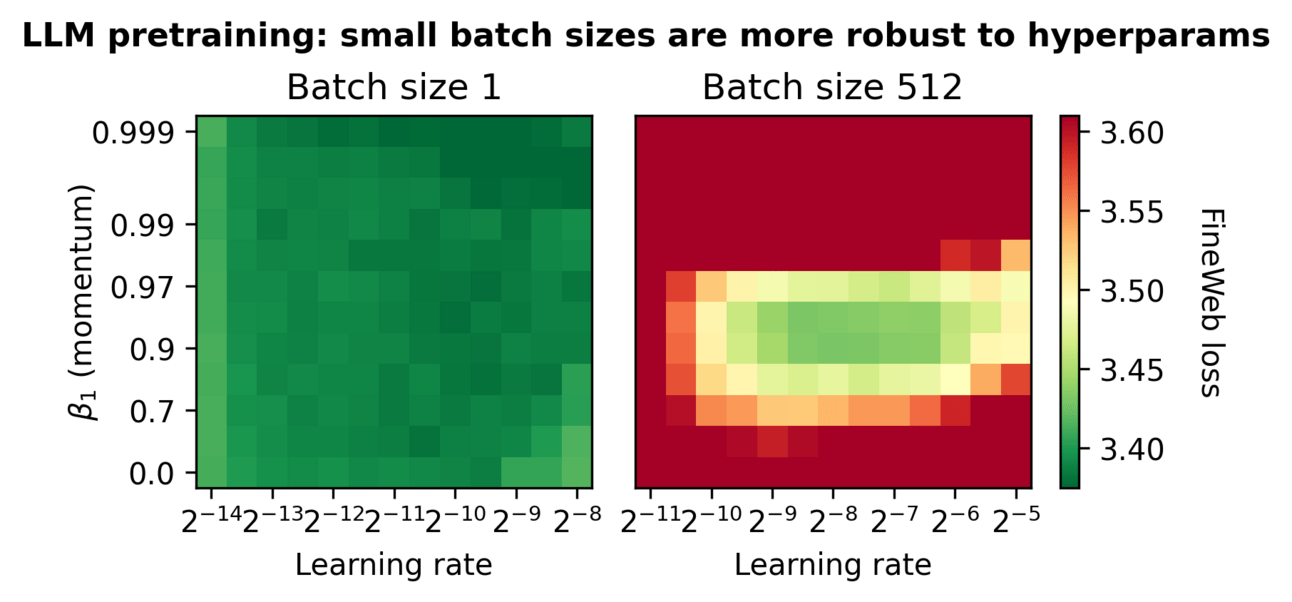
The researchers of this paper have overturned this conventional wisdom, by showing that small batches not only train stably but also outperform larger batches in robustness and efficiency when hyperparameters are scaled correctly.
Inner Workings of Small Batch Optimization
Small batch sizes work surprisingly well because they avoid the pitfalls of large-step updates. When using large batches, optimizers must predict loss surfaces far from current parameters, requiring complex tuning. Smaller batches take gentler steps, which reduces the need for momentum or adaptive methods.
For Adam optimizers, the biggest innovation was scaling the second-moment decay rate (β₂) based on token exposure. Instead of fixing β₂ across batch sizes, the paper proposes preserving its "half-life", the number of tokens needed to halve a gradient’s influence. This means adjusting β₂ as batch size changes: for example, when reducing batch size from 512 to 1, β₂ must increase dramatically (e.g., from 0.95 to 0.9999) to maintain consistent averaging timescales.
Small batches also simplify optimizer choices. Without large, erratic steps, basic stochastic gradient descent (SGD), with no momentum or weight decay, becomes competitive. This eliminates optimizer state memory overhead. Similarly, Adafactor, which compresses second-moment estimates, performs well in this regime. The reduced hyperparameter sensitivity means less tuning: small batches tolerate wider learning-rate ranges and decay-rate variations, making training more accessible.
Results and Practical Guidance
The researchers performed their experiments across models from 30 million to 1.3 billion parameters to confirm small batches match or exceed large-batch performance. For instance:
Robustness: Batch size 1 maintained near-optimal loss across broad hyperparameter ranges, while larger batches degraded sharply with minor misspecifications.
Performance: On GPT-3 (1.3B), SGD at batch size 1 matched AdamW’s results at batch size 512. Adam with scaled β₂ even outperformed the baseline.
Memory Efficiency: Tiny batches enabled training 13B-parameter models on consumer GPUs using stateless SGD or Adafactor, avoiding gradient accumulation.
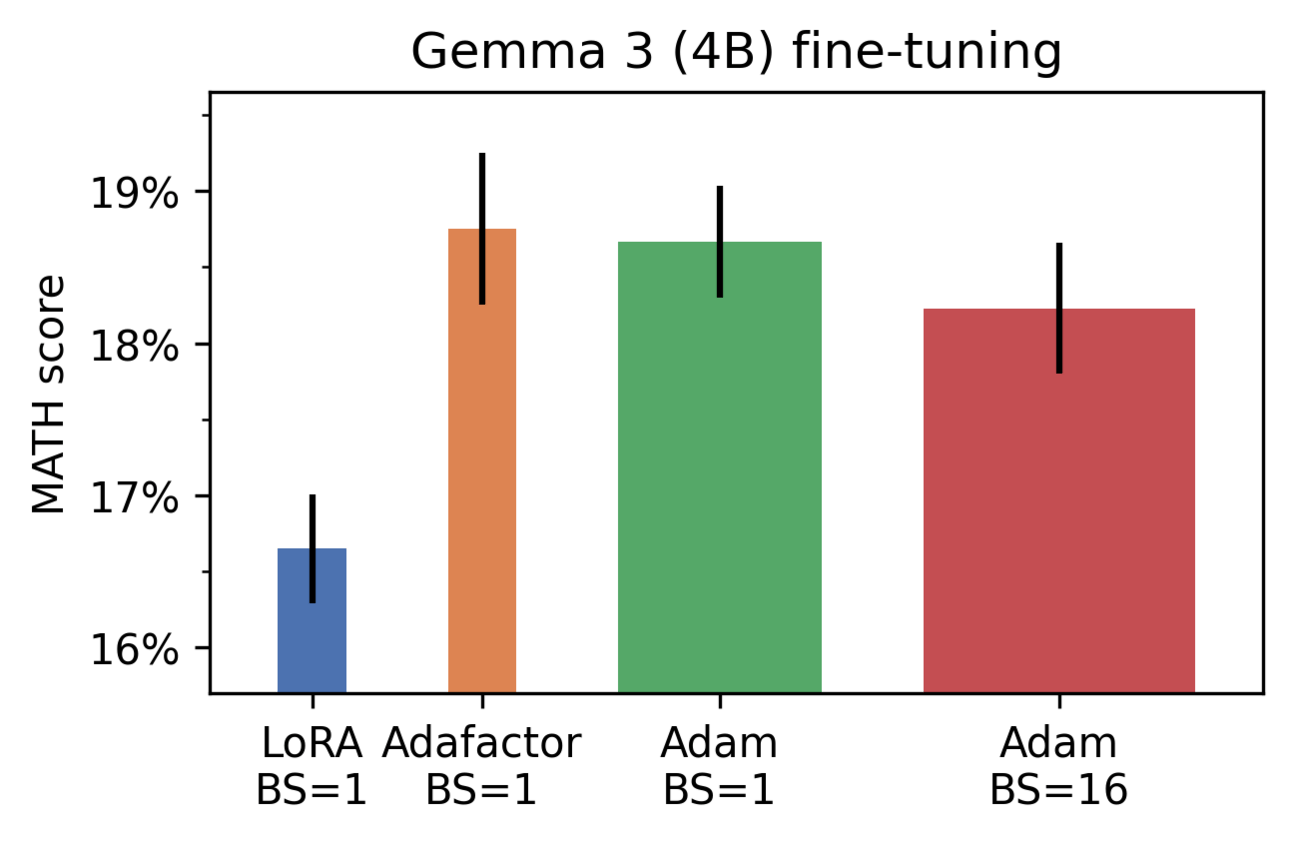
These results led the researchers to draw the following conclusions:
Batch Size: Use the smallest size that maximizes hardware throughput (typically hundreds of tokens per device).
Optimizers: Prefer SGD or Adafactor for memory-constrained settings; scale β₂ to preserve token half-life if using Adam.
Avoid Gradient Accumulation: It wastes memory without benefits unless bandwidth-bound across devices.
🚨This week's top AI/ML research papers:
- Energy-Based Transformers are Scalable Learners and Thinkers
- Dynamic Chunking for End-to-End Hierarchical Sequence Modeling
- Pre-Trained Policy Discriminators are General Reward Models
- First Return, Entropy-Eliciting Explore
-— The AI Timeline (@TheAITimeline)
10:13 AM • Jul 13, 2025
Reply