- The AI Timeline
- Posts
- Embarrassingly Simple Self-Distillation Technique
Embarrassingly Simple Self-Distillation Technique
plus more on Path-Constrained MoE, HISA, and Screening is not enough
by cloud
April 07, 2026
Apr 1st ~ Apr 7th
#102 Latest AI Research Explained Simply
🗞️ Industry News in 1 Line
♥ 2k Arcee.ai has introduced Trinity-Large-Thinking, a new open-weights language model designed specifically for complex agent workflows and long-horizon tool use. This model offers improved multi-turn coherence, stable instruction following, and the efficiency required for production-scale deployments. Try the model out for yourself via API on OpenRouter or explore it on Hugging Face.

♥ 7.2k Google has introduced Gemma 4, a new family of open models released under the permissive Apache 2.0 license. The lineup features four distinct sizes tailored for various deployment needs, including a 31B dense model for raw performance, a 26B Mixture-of-Experts (MoE) variant for low latency, and efficient 2B and 4B options optimized for edge devices. You can download the model weights and start fine-tuning for specific tasks today by checking it out on Hugging Face or Ollama.

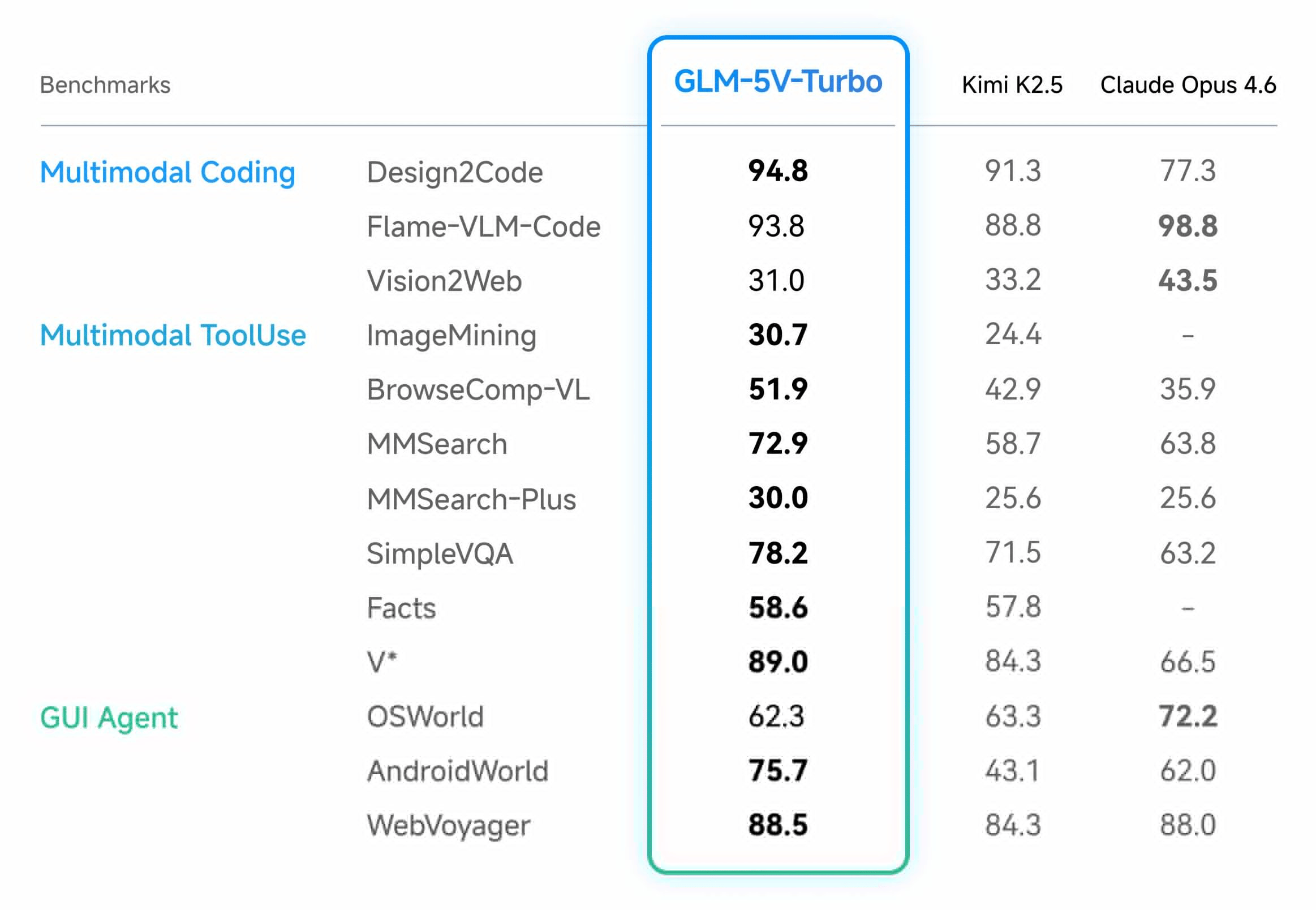
♥ 5.8k Z.ai has launched GLM-5V-Turbo, a native vision coding model capable of translating multimodal inputs (such as design drafts, videos, and UI screenshots) directly into executable code. Backed by a new CogViT visual encoder and collaborative reinforcement learning across over 30 task types.
♥ 4.6k Alibaba's Qwen team has introduced Qwen3.5-Omni, a new family of native multimodal models designed to seamlessly process and integrate text, image, audio, and video inputs. It is available in Plus, Flash, and Light variants, the models feature massive context capacities capable of handling up to 10 hours of audio, along with advanced real-time capabilities like emotion-controlled voice interaction and "Audio-Visual Vibe Coding." You can explore the real-time voice demo on Hugging Face or access the models via the Alibaba Cloud API.

Intuitive AI Academy - NEW MoE Chapter!
My latest project: Intuitive AI Academy has the perfect starting point for you! We focus on building your intuition to understand LLMs, from transformer components, to post-training logic. All in one place.
We just added a new chapter on MoE, that goes through the history, the key techniques, and the current state of MoE that frontier model uses. With over 10,000 words written!
We currently have an early bird offer, where you would get 40% off on the yearly plan for our early users.
Use code: TIMELINE
HISA: Efficient Hierarchical Indexing for Fine-Grained Sparse Attention
Xu et al.
♥ 256 Attention
When we ask an LLM to analyze a massive document, it uses a clever trick called sparse attention, where it only focuses on the most relevant words instead of processing everything equally. The internal tool that selects these important words still has to scan every single word in the document one by one.

Comparison of the DSA token-wise indexer (left) and HISA hierarchical block-level coarse filter followed by token-level refinement (right)
To solve this, researchers developed an elegant workaround called Hierarchical Indexed Sparse Attention. Instead of a flat, word-by-word scan, this new method uses a brilliant two-step strategy. First, it chunks the massive document into larger blocks and looks at a quick summary of each block to instantly filter out the irrelevant sections.

Latency comparison of the indexer kernel between the original DSA
Once the bulk of the text is safely discarded, the system zooms in on the surviving blocks, scanning only those specific words to find the exact information the AI needs. It is much like skimming the chapter titles of a textbook to find the right section before reading the actual sentences.

By rewriting this search path, researchers managed to speed up the scanning process by nearly four times for exceptionally long texts, all while perfectly preserving the model's accuracy.
Embarrassingly Simple Self-Distillation Improves Code Generation
Zhang et al. [Apple]
♥ 1.5k Distillation bycloud’s pick
Teaching an AI to write better code requires expensive human examples, a smarter teacher model, or highly complex reward systems that verify every single line of code. This heavy reliance on outside help has become a massive bottleneck in AI development. Researchers recently asked a fascinating question to address this: could a model pull itself up by its bootstraps, improving its own capabilities using absolutely nothing but its own raw, unverified outputs?
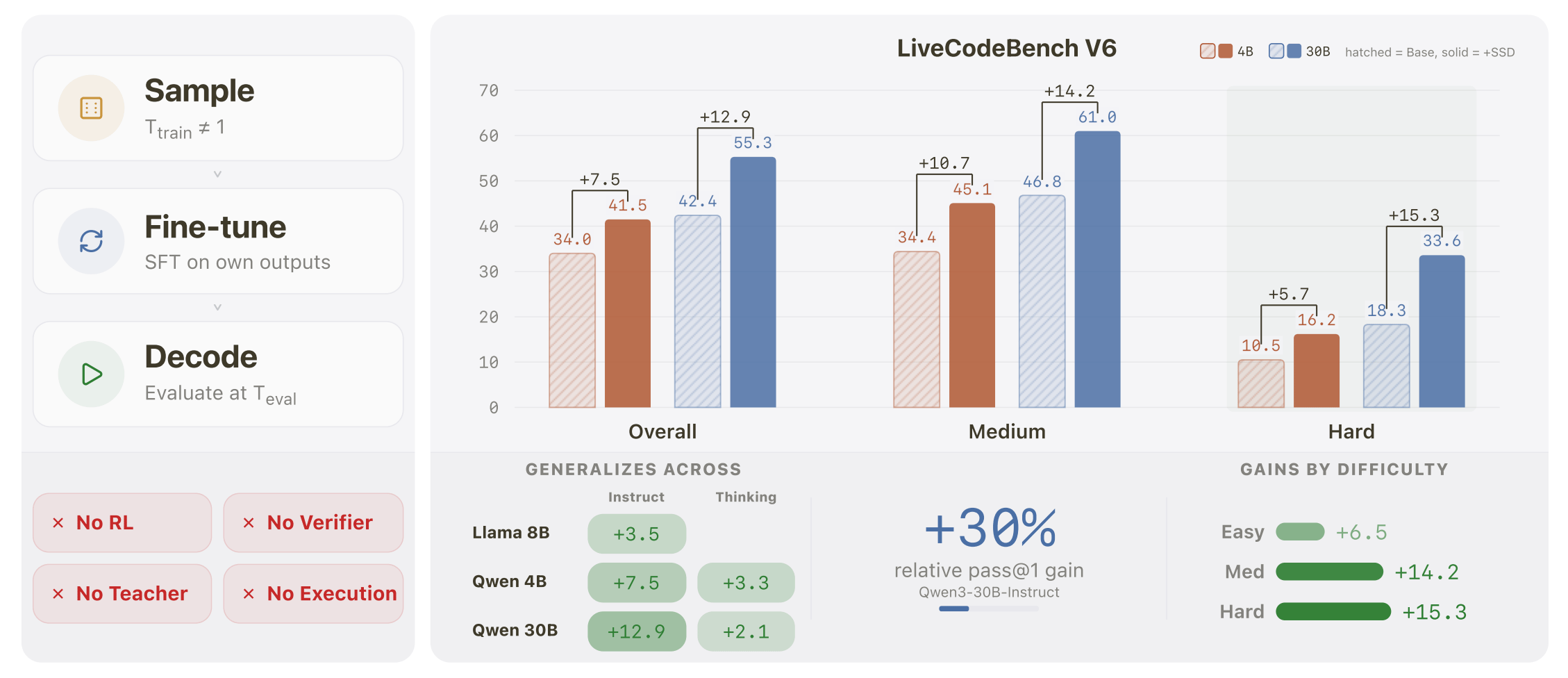
Simple self-distillation (SSD) is embarrassingly simple, yet yields substantial LiveCodeBench v6 gains across five models spanning two families, three scales, with both instruct and thinking variants.
This can be done through a method called simple self-distillation. Researchers asked the AI to generate solutions to coding prompts (without running test cases or checking if the code actually worked) and then retrained the AI on those exact responses. Remarkably, this caused a massive leap in performance across several different models, with the absolute biggest gains seen on the hardest coding challenges. Rather than just memorizing a single dominant way to solve a problem, the AI actually preserved its ability to explore multiple viable solution paths.

SSD improves every evaluated model on LiveCodeBench, with the largest gains on medium and hard problems
To understand why this works, researchers uncovered a fascinating tug-of-war inside the model called the precision-exploration conflict. When writing code, an AI encounters "locks" (moments requiring rigid exactness with zero ambiguity) and "forks", i.e. moments requiring creative exploration to choose a problem-solving approach.

Training and evaluation temperatures compose through a broad effective-temperature band, while truncation raises the achievable pass@1 within that band.
Normally, adjusting an AI's generation settings forces a strict compromise: making it flexible enough to navigate creative forks causes it to make sloppy, distracting errors at the rigid locks.
Path-Constrained Mixture-of-Experts
Gu et al. [Apple, Google]
♥ 356 MoE
In "Mixture-of-Experts" architectures, instead of activating the entire AI for every word, this design acts like a traffic system, routing each piece of information only to specialized mini-programs, or experts. But there is a catch.
Historically, these models make independent routing decisions at every single layer, creating an astronomical number of possible pathways. Because the vast majority of these paths are never explored during training, researchers realized this scattered approach represents a massive inefficiency. They wondered if they could guide information along more intentional, organized routes.

Spectrum of routing constraints in MoE architectures.
When peering inside these systems, researchers discovered something fascinating: language naturally organizes itself. Even without strict guidance, words cluster into a tiny fraction of specific pathways based on their linguistic purpose, with dedicated paths emerging for things like punctuation, names, or action verbs.
To amplify this natural structure, the team introduced a streamlined approach called PathMoE. Instead of letting every layer make its own isolated traffic decisions, PathMoE groups consecutive layers into blocks that share the exact same routing rules. Because neighboring layers process similar information, this gentle constraint guides the data along highly concentrated, specialized routes without restricting the model's overall potential.

Main results on Fineweb-100B with 0.9B total / 0.37B active MoE architecture. Throughput is reported per GPU and memory reports peak active GPU memory.
By simply encouraging these natural pathways, models equipped with PathMoE demonstrated consistent improvements in accuracy and language comprehension. This method naturally keeps the AI's workload perfectly balanced, eliminating the need for the clunky, manual tuning formulas engineers previously relied on.
Screening Is Enough
Nakanishi [RIKEN]
♥ 762 Attention
AI models distribute a fixed budget of attention across every piece of information they read. Because this budget is strictly capped, the system evaluates data relatively, comparing words against one another rather than valuing them on their own merits. As a document grows, this fixed attention dilutes.

A new architecture called Multiscreen introduces a beautifully intuitive solution to this problem through a mechanism researchers call "screening." Instead of forcing words to compete for a slice of a fixed attention pie, screening judges every piece of information entirely independently against a strict, absolute threshold. If a piece of data is useful, it passes the screen; if it is irrelevant, it is completely discarded.

Long-context perplexity comparison between 353M Transformer and 286M Multiscreen models.
By eliminating global competition among data points, the model cleanly filters out the noise and confidently gathers only the information that actually matters, allowing it to adapt its focus without getting overwhelmed by sheer volume.
Researchers found that Multiscreen achieves comparable performance using roughly forty percent fewer parameters than standard models. Even more impressively, a vastly scaled-down version of Multiscreen consistently outperformed much larger standard models in retrieving specific information, all while cutting processing delays by over three times on massive texts.
Reply