- The AI Timeline
- Posts
- Flash Attention 4 is nuts
Flash Attention 4 is nuts
and more about Speculative Speculative Decoding, SWE-CI, and Beyond Language Modeling
by cloud
March 10, 2026
Mar 3rd ~ Mar 10th
#98 Latest AI Research Explained Simply
🗞️ Industry News in 1 Line
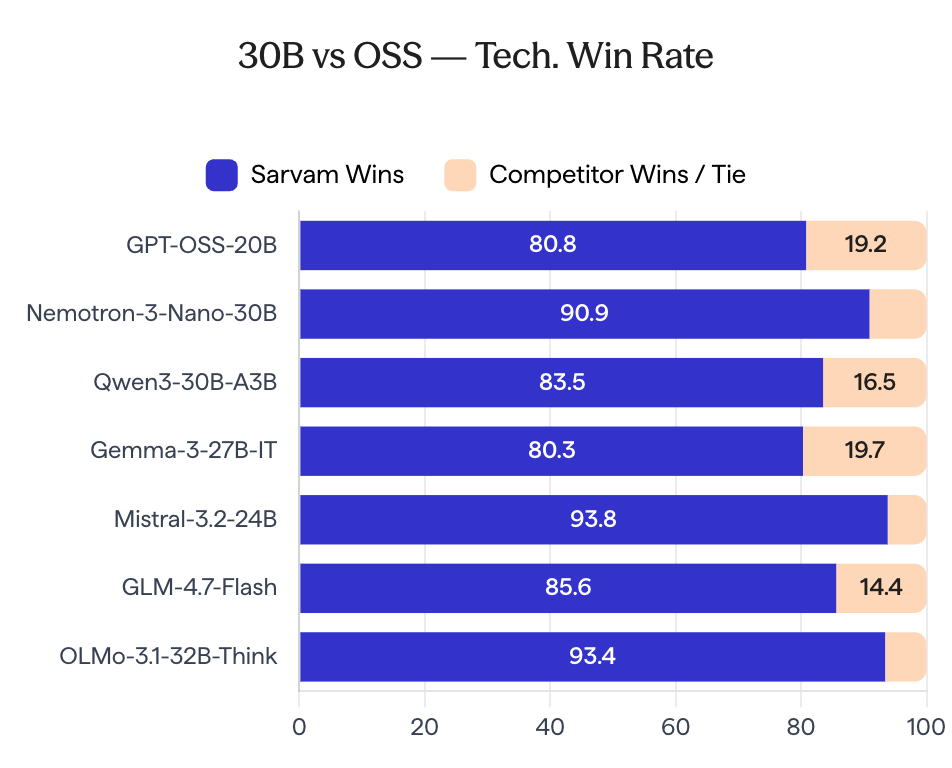
♥ 6.8k Sarvam AI has announced the open-source release of its 30B and 105B parameter models, which were developed entirely in-house to target both global benchmarks and Indian language tasks. The model weights are now available on Hugging Face and AIKosh, featuring day-zero support for SGLang with vLLM compatibility expected soon.
♥ 23k OpenAI has launched GPT-5.4 Thinking and GPT-5.4 Pro models across ChatGPT, the API, and Codex. These new models are designed to enhance reasoning, coding, and agentic workflows. It also includes features such as advanced deep web research capabilities and the ability for users to interrupt the model mid-process to provide real-time instructions or course corrections.
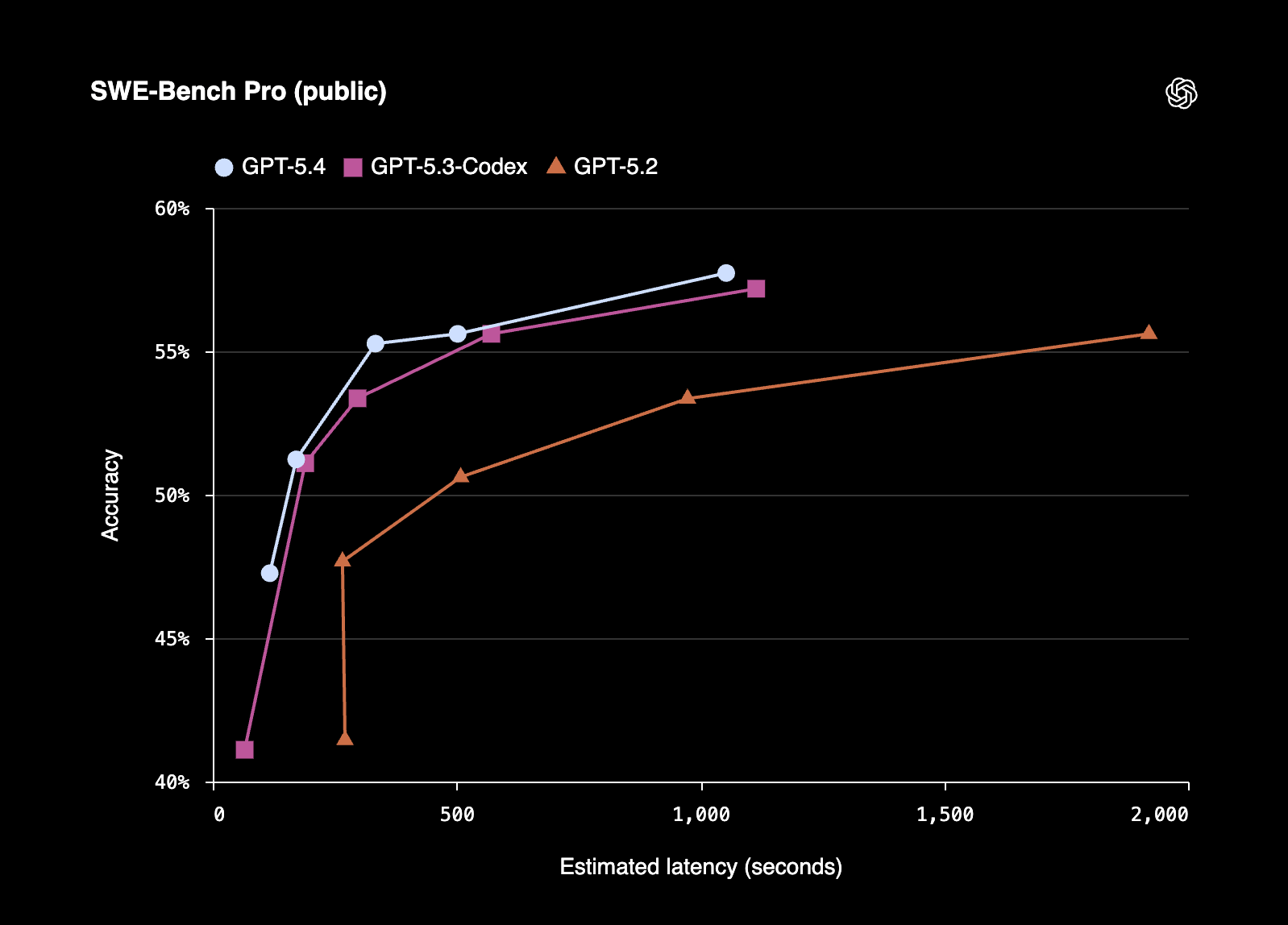
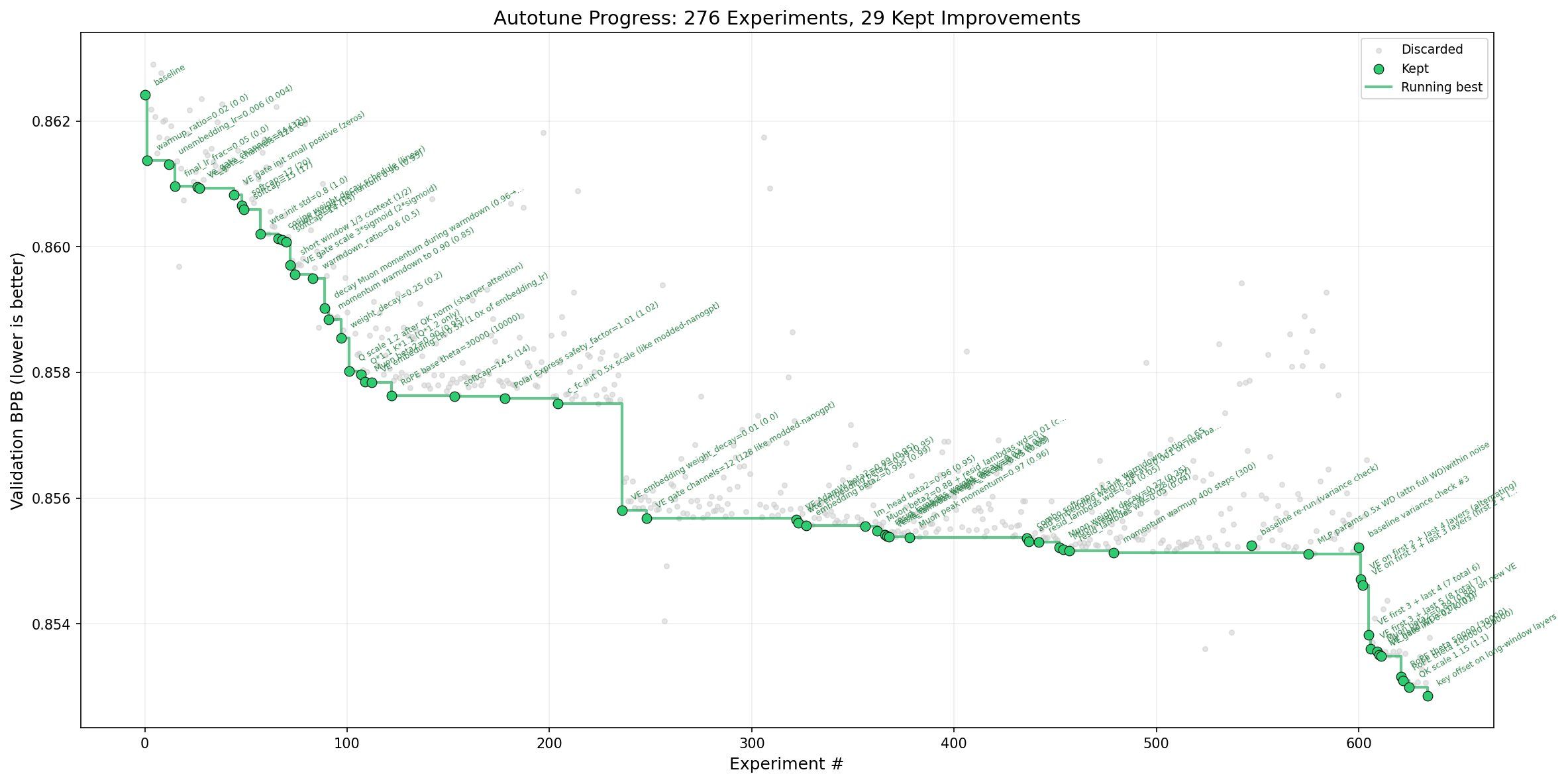
♥ 15k Andrej Karpathy has developed an "autoresearch" agentic workflow designed to autonomously optimize neural network training through iterative experimentation. When applied to his nanochat project, the tool identified 20 additive changes that reduced the "Time to GPT-2" training benchmark from 2.02 hours to 1.80 hours.
Intuitive AI Academy - NEW MoE Chapter!
My latest project: Intuitive AI Academy has the perfect starting point for you! We focus on building your intuition to understand LLMs, from transformer components, to post-training logic. All in one place.
We just added a new chapter on MoE, that goes through the history, the key techniques, and the current state of MoE that frontier model uses. With over 10,000 words written!
We currently have a early bird offer, where you would get 40% off yearly plan for our early users.
Use code: TIMELINE
Speculative Speculative Decoding
Kumar et al. [Stanford University, Princeton University, Together AI]
♥ 22k Decoding
The primary hurdle in making LLMs feel instantaneous is a phenomenon known as the sequential bottleneck. Standard AI models generate text one word, or "token", at a time, which fails to fully use the massive parallel computing power of modern hardware. Researchers previously introduced "speculative decoding", a method where a small, fast model drafts a few guesses for a larger model to verify. The drafting model has to wait for the larger model to finish checking its work before it can start guessing the next set of words. This creates a persistent lag that limits how fast even the most advanced systems can communicate.

Ordinary speculative decoding (SD) requires the verifier to wait idly for the draft to speculate.
To eliminate this idle time, researchers have developed Speculative Speculative Decoding (SSD) via an optimized algorithm called Saguaro. The biggest change is decoupling the "guesser" from the "checker" entirely. While the large target model is busy verifying a current batch of text, Saguaro’s draft model looks ahead and predicts several possible outcomes of that verification. It prepares a menu of "potential futures." If the larger model confirms one of these predicted outcomes, the system can immediately provide the next set of words without any drafting delay. This parallel approach effectively hides the time spent guessing, transforming a sequential process into a streamlined, continuous flow.

By using a clever "geometric fan-out" strategy, Saguaro focuses its computational effort on the most likely verification results, ensuring the "speculation cache" is highly accurate even at higher creative temperatures. This method is entirely lossless, meaning it achieves the exact same high-quality output as the original model but at much higher speeds.
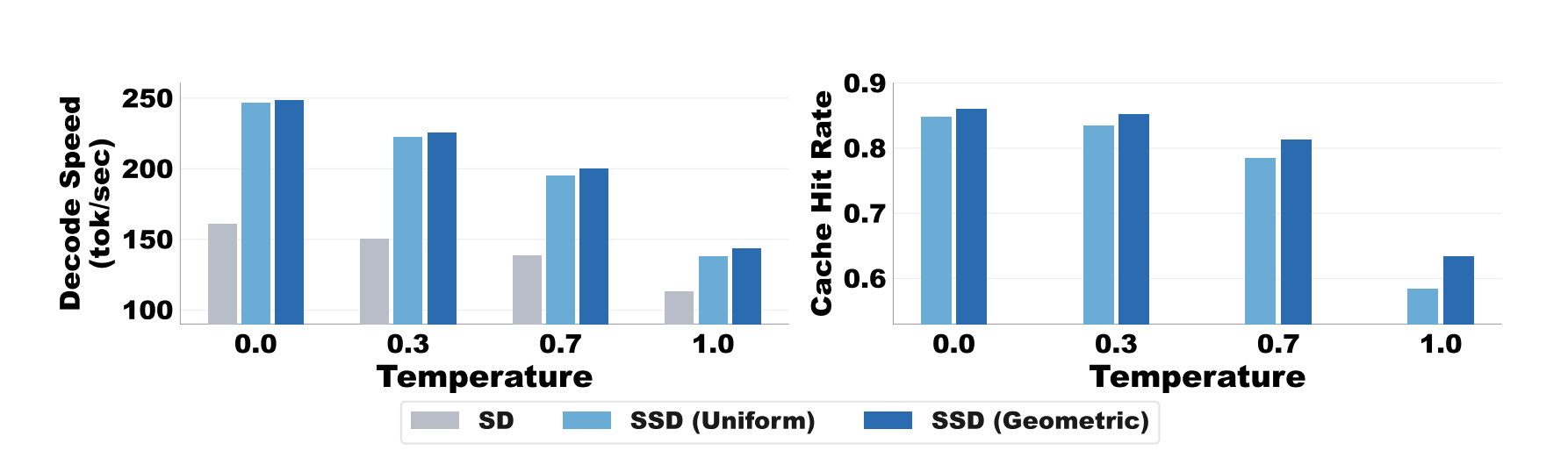
Advantage of geometric fan out strategy increases at higher temperatures, improving both speculation cache hit rate (right) and thus end-to-end speed (left).
Initial results show that Saguaro can deliver text up to five times faster than traditional generation methods and twice as fast as previous state-of-the-art speculative techniques.
Beyond Language Modeling: An Exploration of Multimodal Pretraining
Tong et al. [FAIR, New York University]
♥ 424 Multimodal LLMs bycloud’s pick
AI is getting good at manipulating language, but it lacks a fundamental grasp of the physical world. Researchers describe this limitation using the "allegory of the cave": current models have mastered the description of shadows on a wall, text, without ever seeing the actual objects casting those shadows. Because text is a human abstraction, it is a "lossy" version of reality that misses the raw physics, geometry, and causality of our environment.
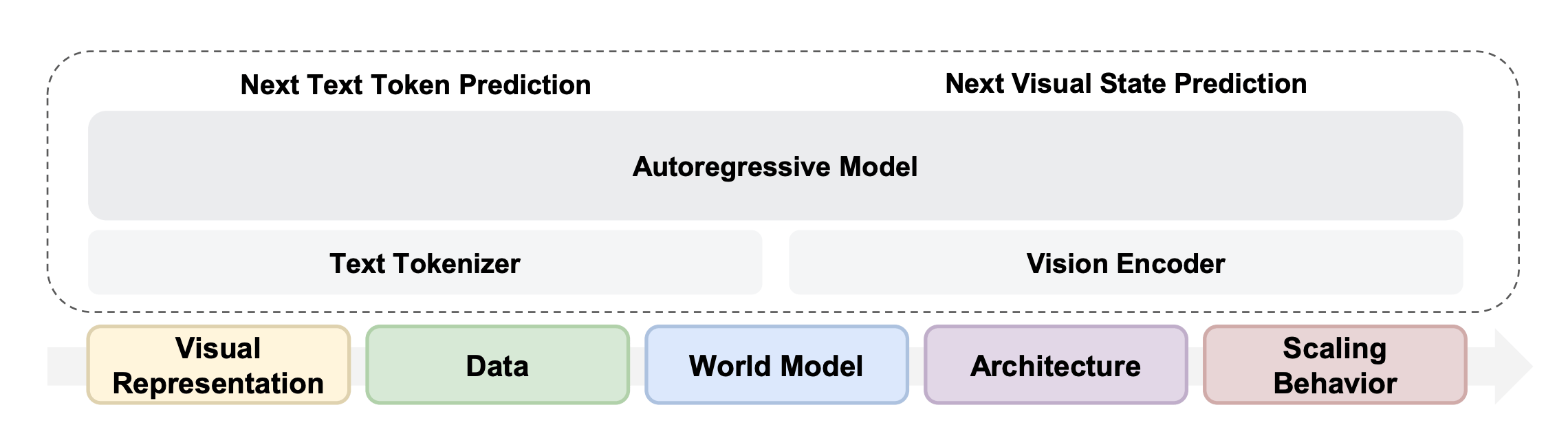
Overview of this study.
By training models to "see" and "read" simultaneously from birth, we can build a more grounded intelligence that understands the world’s dynamics directly.
The researchers developed a unified model using a framework called Transfusion, which trains a single "brain" to perform two different tasks at once: predicting the next word in a sequence and reconstructing visual frames through a process called diffusion.

Examples of training data.
They discovered that the most effective way to do this is by using a single, high-quality visual representation known as a Representation Autoencoder. This contradicts the traditional belief that you need different "eyes" for understanding an image versus creating one; instead, a unified representation excels at both while keeping the model’s language skills sharp.
The study also showed that learning from diverse visual data, like video and image-text pairs, actually improves the model’s performance on downstream tasks like reasoning and planning. To manage this complexity, they utilized a "Mixture-of-Experts" architecture.

Multimodal co-training exceeds unimodal performance.
This design allows the model to naturally evolve specialized internal "experts" for different tasks. It learned to dedicate more capacity to language while efficiently processing the massive amounts of data required by vision. Most impressively, this unified training allowed "world modeling" capabilities to emerge.
The model could predict the physical outcome of actions, like navigating a robot through a room, using simple text commands, proving that a truly multimodal foundation can bridge the gap between human language and physical reality.
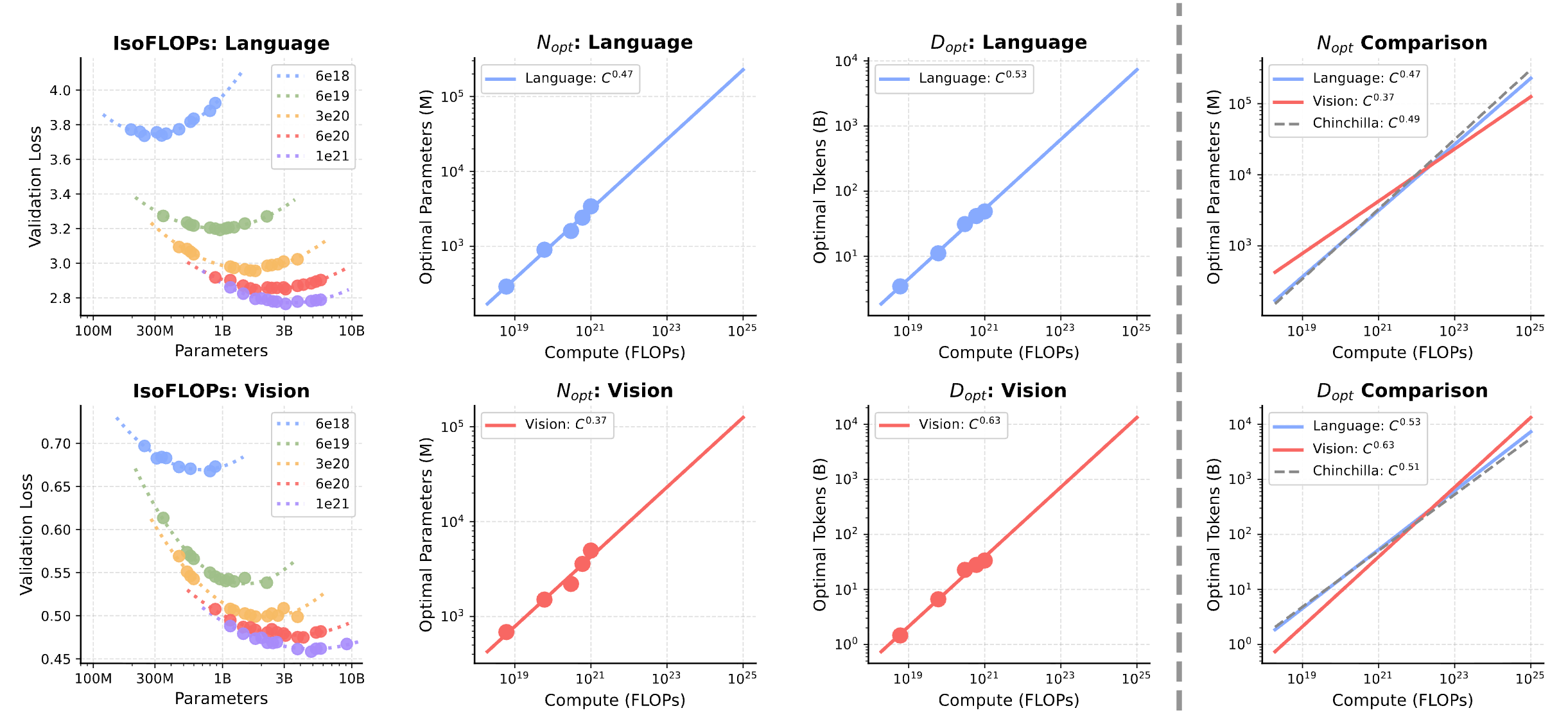
Scaling laws for unified dense models.

FlashAttention-4: Algorithm and Kernel Pipelining Co-Design for Asymmetric Hardware Scaling
Zadouri et al. [Princeton University, Meta, Colfax Research, NVIDIA, Georgia Tech, Together AI]
♥ 430 Attention
Latest AI hardware is significantly faster at basic matrix multiplication, but other components, like the units responsible for specialized math or moving data around, haven't kept the same pace. This creates a digital traffic jam where the fastest parts of a processor are frequently left idling, waiting for slower sections to finish their work.
FlashAttention-4 was designed to bridge this gap, by offering a clever software design that can overcome the physical limitations of even the most advanced hardware.

FlashAttention-4 forward pipeline.
The researchers taught the software to find creative shortcuts around these hardware bottlenecks. Because the chip’s dedicated unit for calculating exponentials is often the slowest link in the chain, they developed a way to emulate its functions using more plentiful, general-purpose math units.
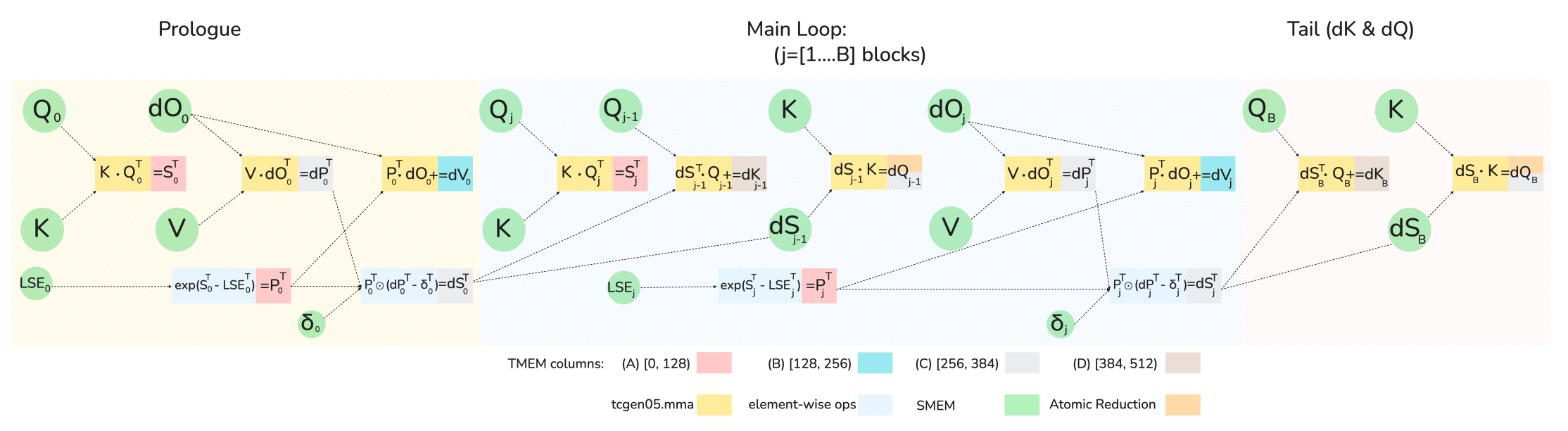
FlashAttention-4 backward computation graph (5 MMA operations + 2 elementwise operations), showing the 1-CTA MMA mode software pipeline order across the prologue, main loop, and tail.
By using a mathematical technique called polynomial approximation, the software effectively mimics the specialized unit, achieving nearly identical accuracy at much higher speeds. Additionally, they introduced a "conditional rescaling" method that intelligently skips redundant calculations unless they are truly necessary for precision.
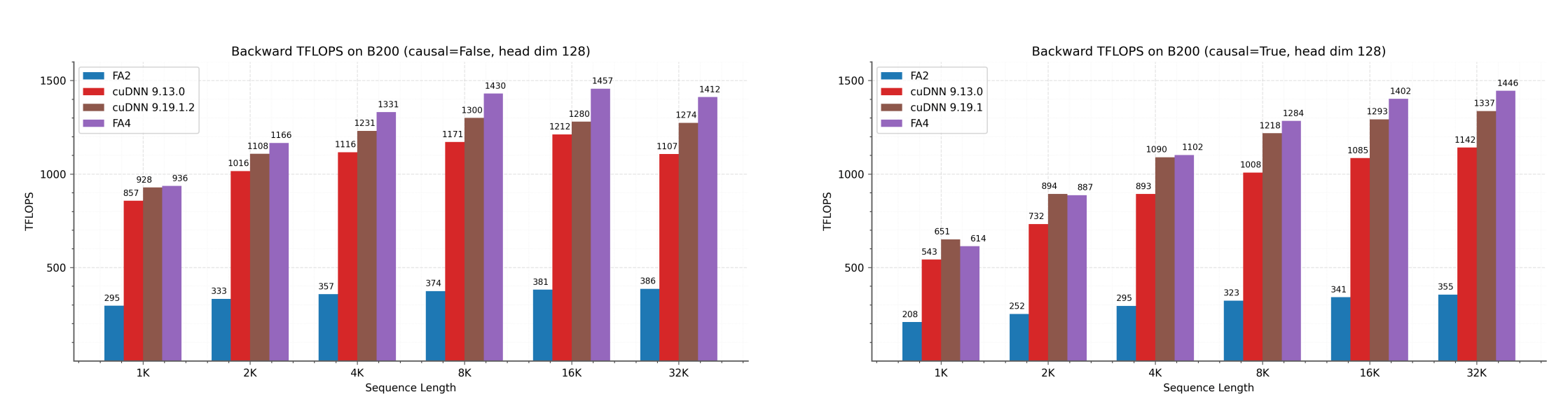
Backward pass TFLOPS on B200 (FP16/BF16) with head dimension 128.
By keeping more data in high-speed "tensor memory" and coordinating tasks so that different parts of the chip work in perfect sync, FlashAttention-4 can reach incredible speeds, hitting up to 1613 trillion operations per second on the latest Blackwell GPUs.
SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via Continuous Integration
Chen et al. [Sun Yat-sen University, Alibaba Group]
♥ 855 LLM Evaluation
Software engineering is rarely about writing a perfect piece of code in one go; it is an ongoing marathon of maintenance, updates, and evolving requirements. While current AI models have become quite good at solving isolated, one-shot coding tasks, these models are often tested on their ability to provide a quick fix rather than their capacity to sustain a healthy codebase over time.
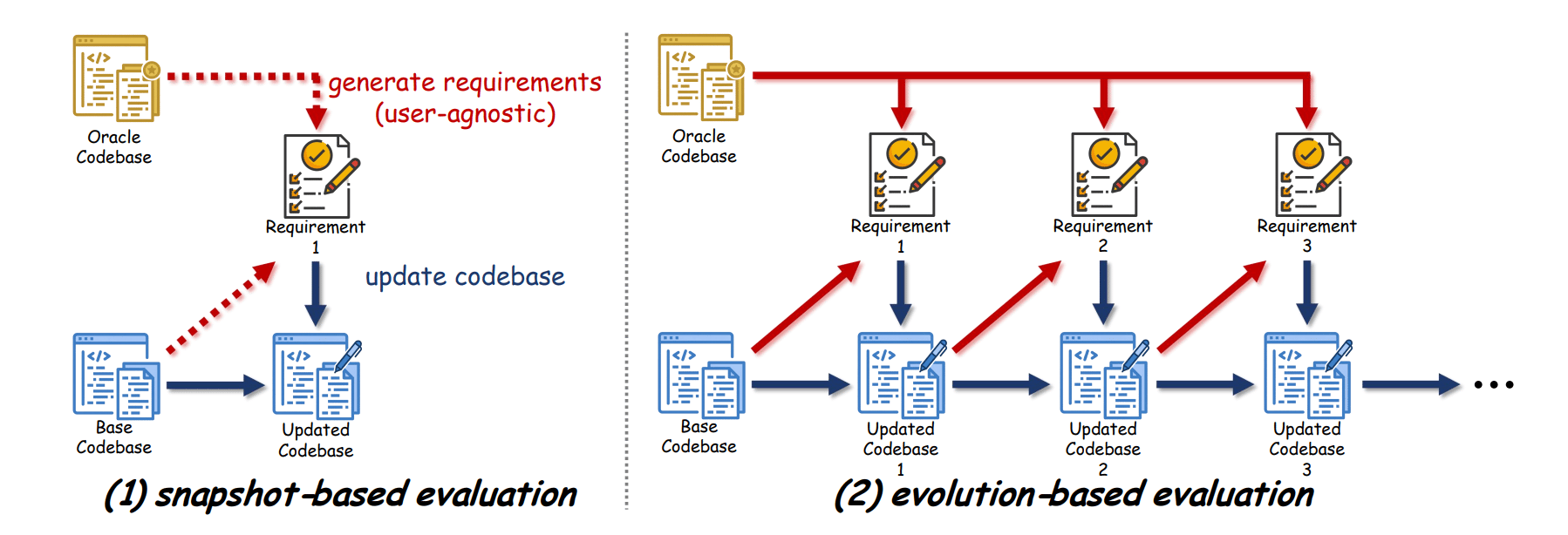
Unlike previous benchmarks, SWE-CI proposes an evolution-based evaluation.
To address this, a new benchmark called SWE-CI shifts the focus from simple functional correctness to long-term maintainability, providing a much-needed lens into how AI agents handle the messy, continuous reality of software development.
The researchers built this benchmark using actual evolutionary histories from real-world software repositories, with tasks spanning an average of seven months and dozens of consecutive updates. To mirror a professional environment, they employed a dual-agent system where one AI acts as an Architect to identify gaps and set requirements, while a second Programmer agent implements the changes.
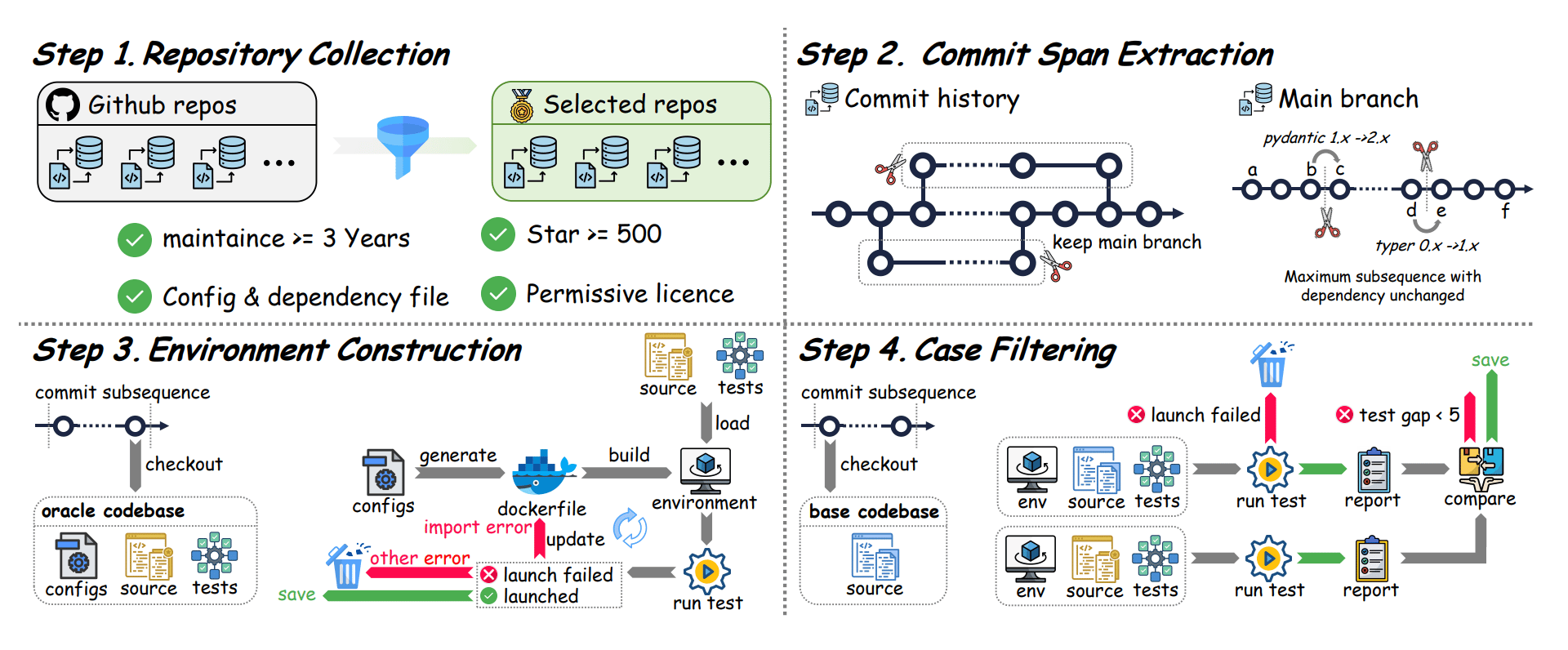
Data curation process of SWE-CI.
Success is measured by a novel metric called EvoScore, which specifically rewards agents that make decisions facilitating future growth rather than just immediate fixes.
The results show that the newest AI models are improving at an accelerating pace, but most still struggle to prevent regressions, the frustrating phenomenon where adding a new feature accidentally breaks an old one. This discovery highlights that the next great frontier for AI developers isn't just writing code that works, but writing code that lasts.
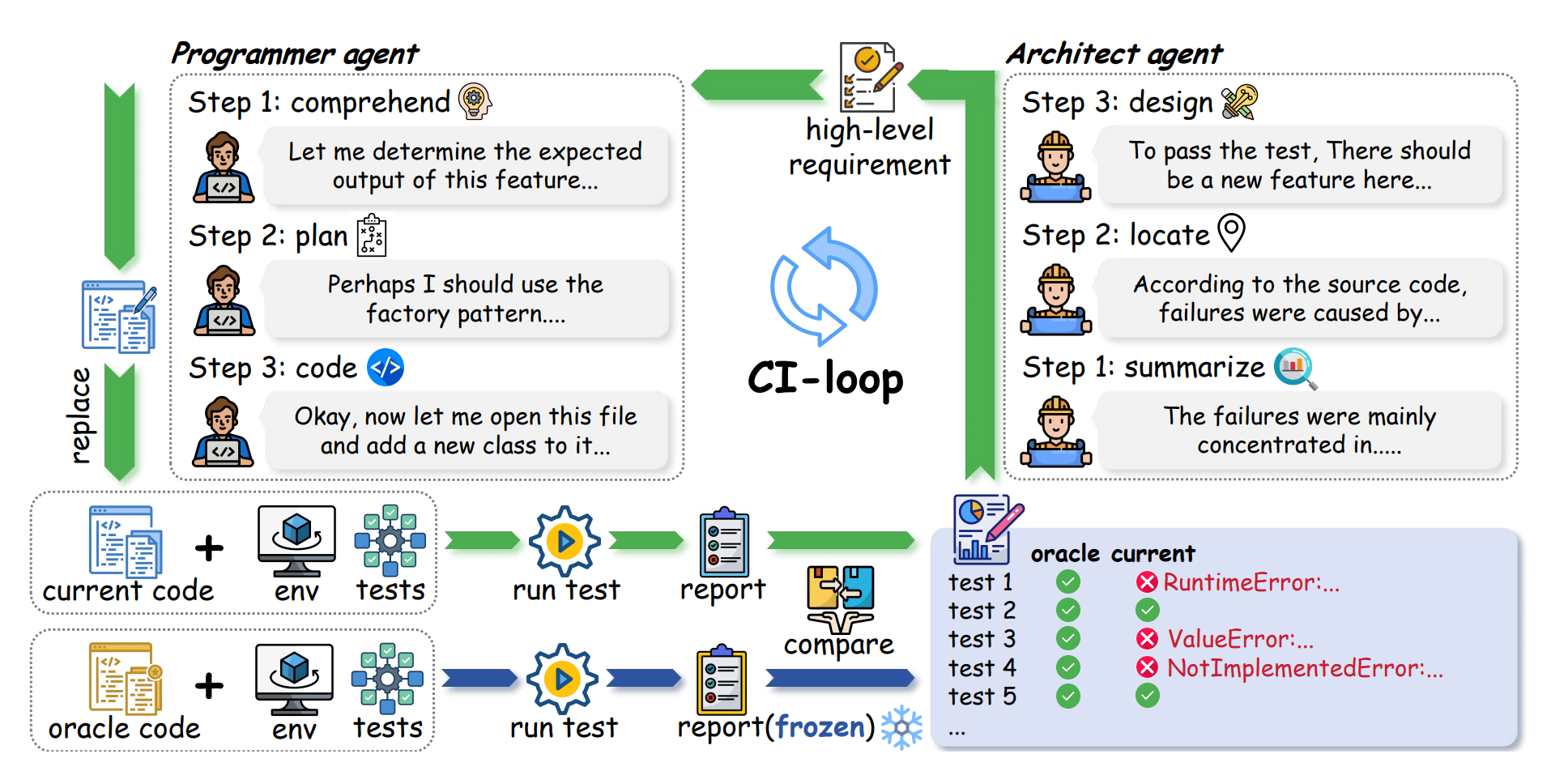
SWE-CI uses an architect-programmer dual-agent workflow to model the continuous integration cycle of professional software teams in the real world.
Real Money, Fake Models: Deceptive Model Claims in Shadow APIs
Zhang et al. [CISPA Helmholtz Center for Information Security]
♥ 805 LLM RL
Access to frontier models is restricted by high costs, complex payment barriers, or geographical limitations. To bridge this gap, many researchers and developers have turned to "shadow APIs", third-party services that promise the same power as official models like GPT-5 or Gemini through unofficial, often cheaper channels. While these services appear to democratize access, they operate in a digital gray market with almost no transparency.
Researchers recently set out to investigate whether these shadow services are truly delivering what they advertise or if they are quietly undermining the integrity of the scientific work built upon them.

Landscape of the shadow APIs.
The investigation revealed a concerning gap between marketing promises and technical reality. By auditing these services through "model fingerprinting", a technique that identifies an AI by analyzing the unique statistical patterns and "signatures" in its responses, researchers discovered that nearly half of the shadow services were not using the models they claimed.
In a classic "bait-and-switch", premium proprietary models were frequently swapped for cheaper, open-source alternatives behind the scenes. This deception led to significant performance collapses; in high-stakes fields like medicine and law, accuracy dropped by nearly half when compared to official versions.

Fingerprinting results via LLMmap matched model and mean cosine distance D with standard.
The researchers found that while these shadow services might handle simple tasks well, they often fail during complex reasoning and display unpredictable safety behaviors. In addition to identifying the mismatch, the study used statistical testing to prove that the outputs from these services were fundamentally different from the official sources.
Reply