- The AI Timeline
- Posts
- Has GPT-5 Achieved Spatial Intelligence?
Has GPT-5 Achieved Spatial Intelligence?
Plus more about Reinforcement Learning with Rubric Anchors and DuPO: Enabling Reliable LLM Self-Verification via Dual Preference Optimization
Naman & by cloud
August 26, 2025
Aug 18th ~ Aug 25th
#70 Latest AI Research Explained Simply
🗞️ Industry News in 1 Line
♥ 3.2k DeepSeek has introduced DeepSeek-V3.1, which is a hybrid inference model that features "Think" and "Non-Think" modes to enhance agent capabilities and processing efficiency. This update also includes API changes with distinct thinking/non-thinking modes, 128K context support, and open-source weights for the V3.1 Base model. You can also download the DeepSeek-V3.1 model weights locally and see how it performs.

♥ 1.8k Microsoft has launched VibeVoice-1.5B, which is an open-source text-to-speech model for generating expressive, long-form, multi-speaker conversational audio such as podcasts. This framework uses continuous speech tokenizers and a next-token diffusion framework with an LLM to produce high-fidelity audio up to 90 minutes long with up to four distinct speakers. You can download the model weights to explore its capabilities, or check out the demo page to hear it yourself!

♥ 921 Vercel has launched AI Elements, an open-source library of customizable React components designed to simplify the creation of AI interfaces with the Vercel AI SDK. This allows developers to build AI applications more efficiently with granular control over UI. If you are creating an AI application and struggling to build your AI interface, you should give it a try!

♥ 713 Qoder is a new agentic coding platform that offers autonomous agents that learn from codebases and documentation to plan and edit projects based on user prompts. It also has a "Quest Mode" for delegating tasks, intelligent codebase search, and advanced repository insight. Currently, it is in the preview mode, which means you can download Qoder for free and use its agentic coding capabilities for real software development.

Support My Newsletter
As I aim to keep this newsletter free forever, your support means a lot. If you like reading The AI Timeline, consider forwarding it to another research enthusiast. It helps us keep this up for free!
Has GPT-5 Achieved Spatial Intelligence? An Empirical Study
Cai et al. [SenseTime Research, Nanyang Technological University]
♥ 485 Spatial Intelligence
Introduction to Spatial Intelligence in AI
Spatial understanding is a fundamental part of human intelligence that allows us to interact with the physical world. However, even advanced multi-modal models often struggle with tasks that involve reasoning about space, such as estimating distances, imagining 3D shapes from 2D views, or interpreting how objects relate to each other. This paper examines how well today’s top AI models perform on a range of spatial tasks.
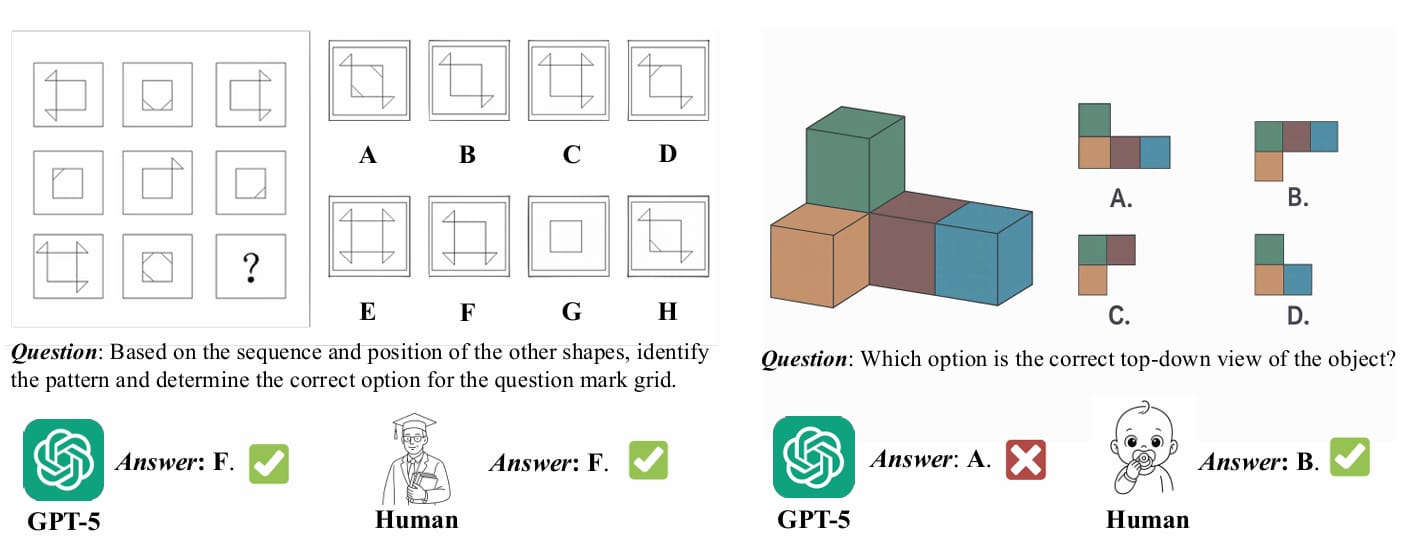
GPT-5 excels at solving complex problems (left) that are considered challenging for humans, but it still struggles with the basic spatial intelligence tasks (right).
How to Evaluate the Spatial Intelligence of LLMs
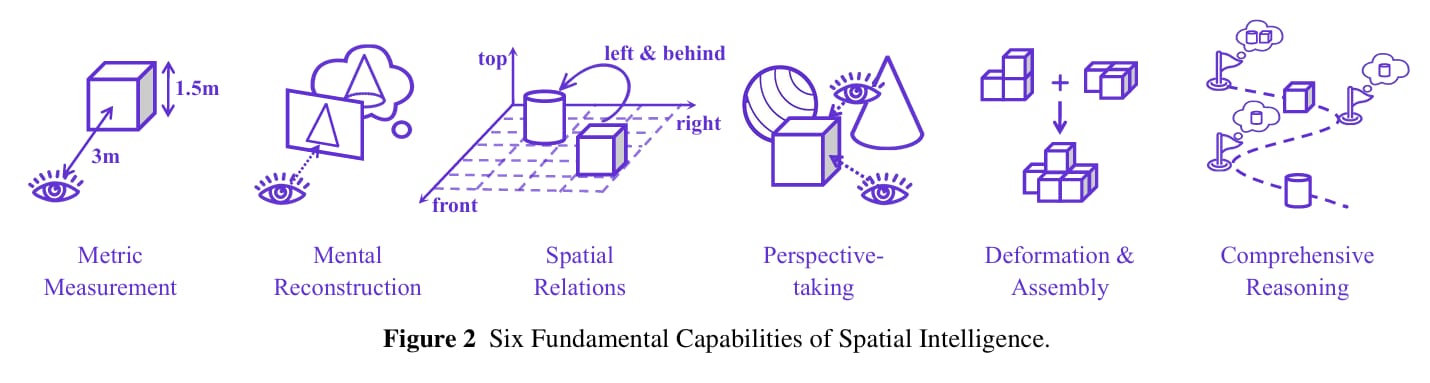
This paper introduces a unified framework to evaluate spatial intelligence by breaking it down into six core capabilities. These include
Metric Measurement, which involves estimating real-world sizes from images
Mental Reconstruction, where the model must imagine a full 3D object from limited views
Spatial Relations focuses on understanding how objects are positioned relative to each other.
Perspective-taking, Deformation & Assembly, and Comprehensive Reasoning, which combine multiple skills for more complex tasks like navigation or puzzle solving.
To test these capabilities, the researchers used eight recently developed benchmarks, such as VSI-Bench, SITE, and SpatialViz, which together include over 30,000 images and 24,000 question-answer pairs. Each benchmark focuses on different aspects of spatial reasoning, and the team standardized evaluation methods to ensure fair comparisons.
Evaluation and Results of Spatial Intelligence Performance
The results show that GPT-5 sets a new standard in spatial intelligence by outperforming other leading models, such as Gemini-2.5-pro and open-source alternatives. It achieved near-human performance in certain areas, such as Metric Measurement and Spatial Relations, with scores like 36.27 on VSI-Bench and 78.37 on CoreCognition.
However, it still lagged significantly behind humans in more challenging tasks like Mental Reconstruction and Perspective-taking, scoring only 15.96 on SpatialViz compared to the human benchmark of 76.59.
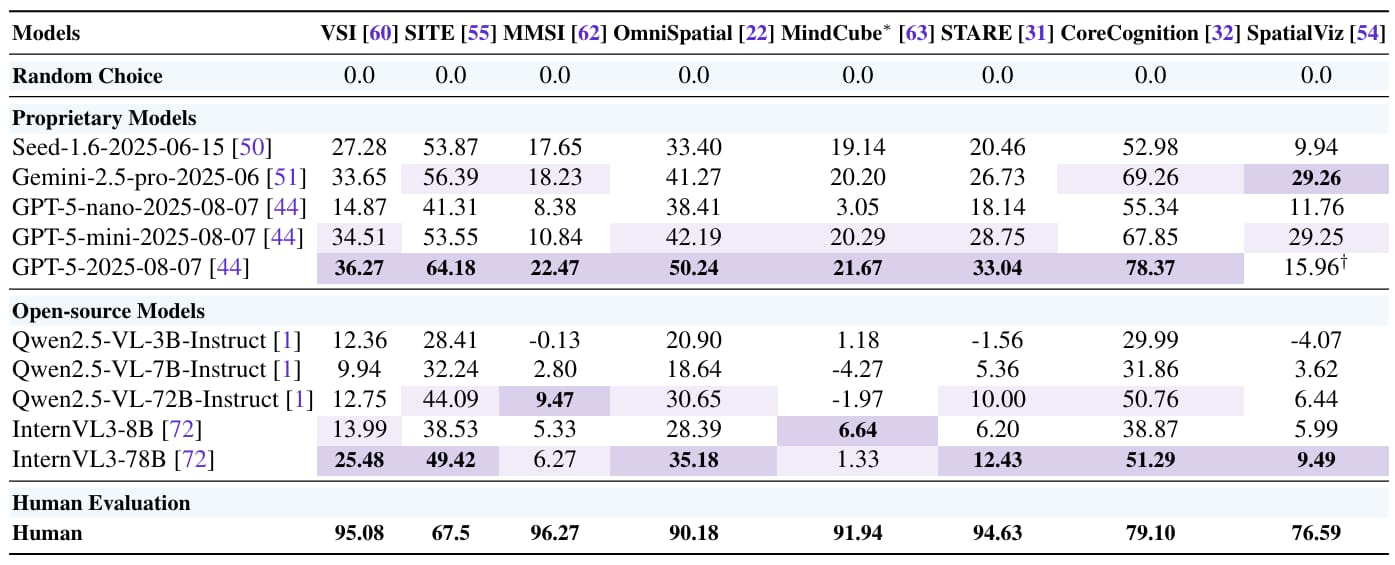
Evaluation using Chance-Adjusted Accuracy (CAA) for consistency across benchmarks and elimination of random bias.
DuPO: Enabling Reliable LLM Self-Verification via Dual Preference Optimization
She et al. [ByteDance Seed, Nanjing University]
♥ 22k Verifiable Rewards
Introduction to DuPO
Training large language models often depends on getting feedback from humans or verifiable answers, which can be expensive and hard to scale. DuPO offers a way to generate feedback automatically by using a clever form of self-supervision based on task duality. Instead of relying on external labels, it uses the model’s own capabilities to create rewards, which makes optimization more scalable and general.
Inner workings of DuPO
DuPO works by breaking down any task input into two parts: a known component and an unknown component. For example, in a math problem like “A box has 3 red and 5 blue balls; what’s the total?”, the known part could be the number of red balls (3), and the unknown part could be the number of blue balls (5).
The model produces an output, say, the total count of 8, and then a dual task tries to reconstruct the unknown part (blue balls) using that output and the known information. If the dual task successfully infers there were 5 blue balls, that serves as a self-supervised reward signal to improve the original task.
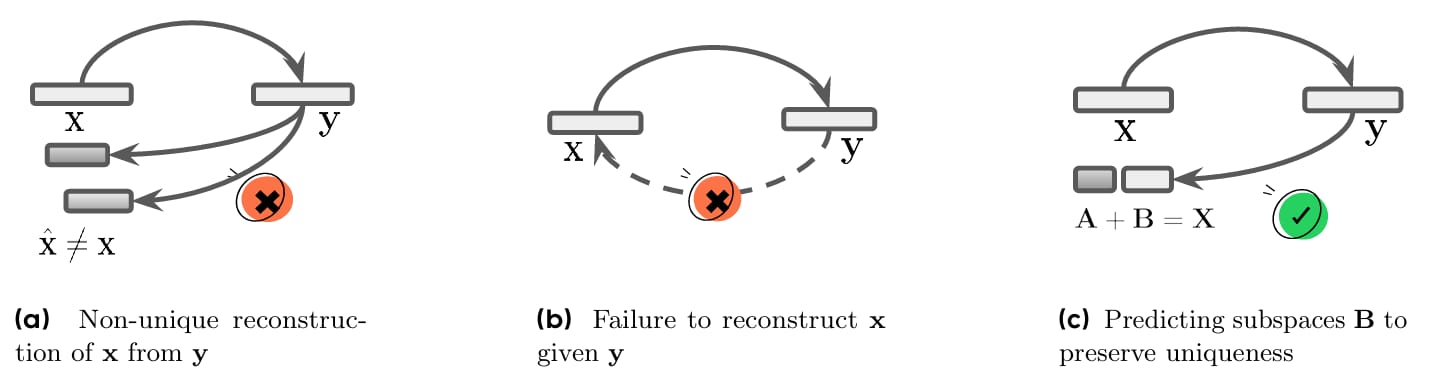
Challenges in Dual Learning and Solutions via Relaxed Duality Constraints.
This approach is more flexible than older dual-learning methods, which required tasks to be fully reversible, like translation and back-translation. Many real-world tasks, such as solving math problems or creative writing, aren’t easily invertible. By focusing only on reconstructing the unknown part, DuPO avoids that limitation. It also reduces noise from performance gaps between the main task and the dual task, since the dual task is simpler and more constrained.
A single language model handles both the main and dual tasks, which simplifies the process. The reward from the dual reconstruction guides the model in improving its responses without any external feedback. This creates a cycle where better primal outputs lead to more accurate reconstructions, which in turn produce better rewards for training.
Evaluation and performance of DuPO
DuPO was tested on multilingual translation and mathematical reasoning with several strong base models. In translation benchmarks, it improved a 7B parameter model by an average of 2.13 COMET points across 756 language directions, which makes it competitive with much larger state-of-the-art systems.
In math reasoning, it boosted accuracy by an average of 6.4 points on challenging benchmarks like AMC and AIME, even helping a 4B model outperform some ultra-large models. Additionally, DuPO can be used for inference-time reranking without extra training, improving results by up to 9.3 points simply by selecting the best output based on dual-task consistency.
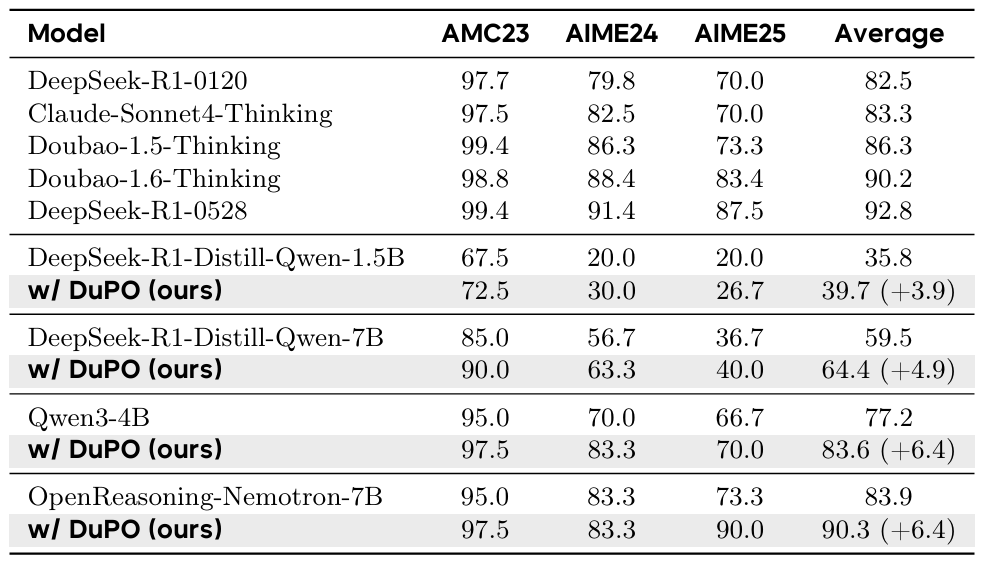
Mathematical Reasoning Performances (%) on Representative Benchmarks.
The method’s success depends on carefully choosing which part of the input is treated as unknown. Ablation studies showed that performance dropped significantly without this selection.
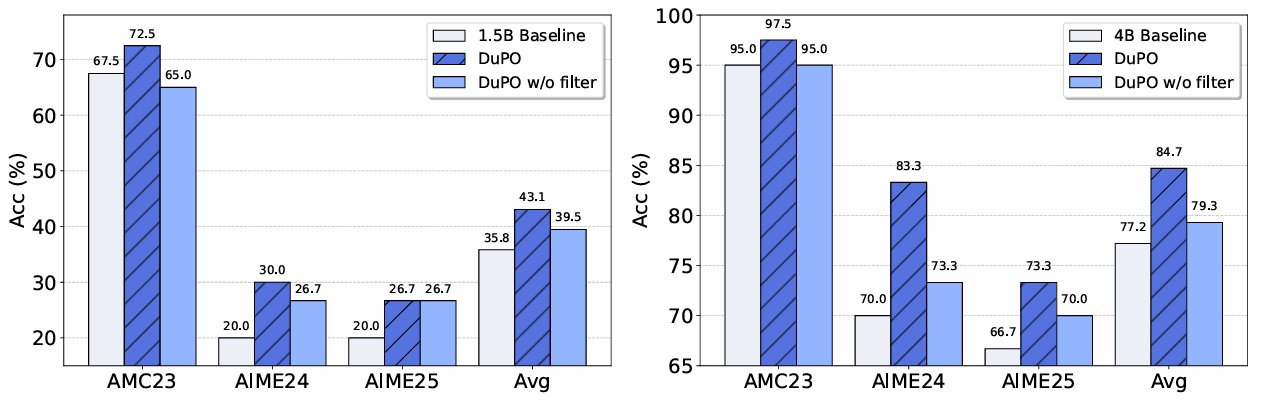
Performance Ablation of DeepSeek-R1-Distill-Qwen-1.5B/Qwen3-4B on Mathematical Reasoning.
Reinforcement Learning with Rubric Anchors
Chu et al. [HKU, UC Berkeley, Google DeepMind, NYU]
♥ 424 Reinforcement Learning bycloud’s pick
Introduction to Rubric-Based Reinforcement Learning
RLVR has proven effective for training LLMs in domains like code generation or math, where correctness can be automatically checked, but this strict requirement limits its use in open-ended, subjective tasks like creative writing or emotional conversation. This paper introduces a method to extend RLVR into these less structured areas by using rubrics: structured, interpretable scoring criteria that allow models to learn from nuanced feedback even when there’s no single right answer.
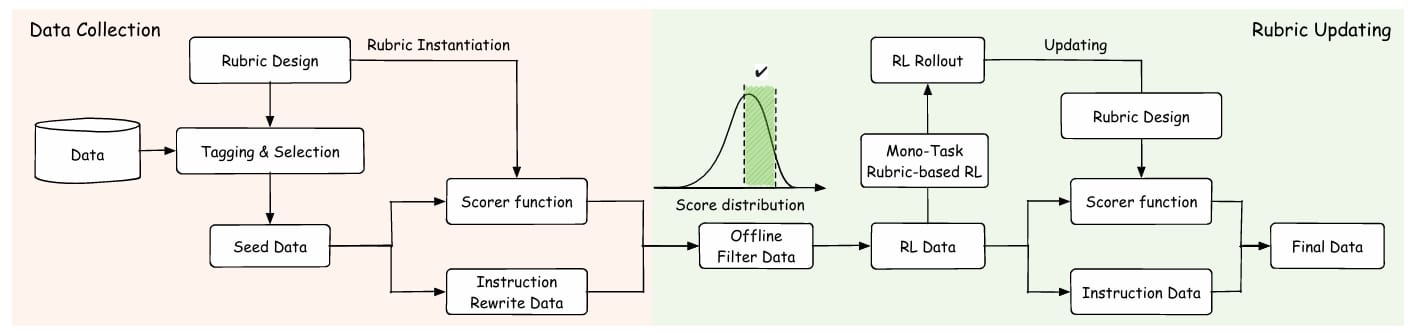
An overview of this rubric system.
Using Rubric-Based System to Evaluate LLMs
The main idea is to replace binary reward signals with detailed rubrics that break down response quality into multiple measurable dimensions, such as emotional expressiveness, narrative authenticity, or instruction adherence. Each rubric consists of several criteria, each with its own scoring tiers and relative importance. This allows the model to receive fine-grained feedback during training. This approach moves beyond simple right-or-wrong evaluation and helps the model learn subtler aspects of high-quality responses.

Soft Rubric (Part 1 of 2)
To implement this, the authors built a large-scale rubric bank with over 10,000 individual rubrics, created through a mix of human design, LLM generation, and collaborative human–model effort. These rubrics are integrated into a two-stage reinforcement learning process.
The first stage focuses on building a solid foundation in reliable instruction-following and constraint satisfaction using verifiable rewards.
The second stage introduces more open-ended and creative tasks, using instance-specific rubrics to encourage adaptability, emotional depth, and stylistic variation.
Soft Rubric (Part 2 of 2)
Evaluation and Performance of Rubric-Based Training
The rubric-trained model (Rubicon-preview) is based on Qwen-30B-A3B and shows strong gains across open-ended benchmarks. It achieves an average improvement of +5.2% on tasks like creative writing, emotional intelligence, and human-like response generation, and even outperforms the much larger 671B-parameter DeepSeek-V3 model by +2.4%.

Results on general and reasoning capabilities.
The training process is also highly token-efficient, as the researchers achieved these results with only around 5,000 training samples.
Reply