- The AI Timeline
- Posts
- How A Vision Transformer Just Broke The ARC-AGI Benchmark
How A Vision Transformer Just Broke The ARC-AGI Benchmark
Plus more on Seer, Virtual Width Networks, SAM 3, and Evolution Strategies at the Hyperscale
by cloud
November 27, 2025
In partnership with
Nov 15th ~ Nov 25th
#83 Latest AI Research Explained Simply
🗞️ Industry News in 1 Line
♥ 1.4k INTELLECT-3: Prime Intellect Scaled RL to a 100B+ MoE model on their own end-to-end stack, achieving SoTA for its size.
♥ 2.9k Black Forest Labs announces FLUX.2, their latest open weights image generation model.
♥ 11k DeepSeek announces DeepSeekMath-V2, the first open source model to reach gold on IMO, also ranking first on ProofBench-Basic, and second on ProofBench-Adv, right behind Gemini-3 Pro
Save 55% on job-ready AI skills

Udacity empowers professionals to build in-demand skills through rigorous, project-based Nanodegree programs created with industry experts.
Our newest launch—the Generative AI Nanodegree program—teaches the full GenAI stack: LLM fine-tuning, prompt engineering, production RAG, multimodal workflows, and real observability. You’ll build production-ready, governed AI systems, not just demos. Enroll today.
For a limited time, our Black Friday sale is live, making this the ideal moment to invest in your growth. Learners use Udacity to accelerate promotions, transition careers, and stand out in a rapidly changing market. Get started today.
Virtual Width Networks
ByteDance Seed
♥ 196 Transformer Architecture
What if we could get the benefits of a much wider AI model without the usual computational explosion? Standard Transformers face a quadratic cost increase when expanding their hidden size, which makes wider models expensive. Virtual Width Networks offer a clever way around this by decoupling the embedding width from the backbone’s hidden dimension, letting the model use richer representations while keeping computation nearly the same.
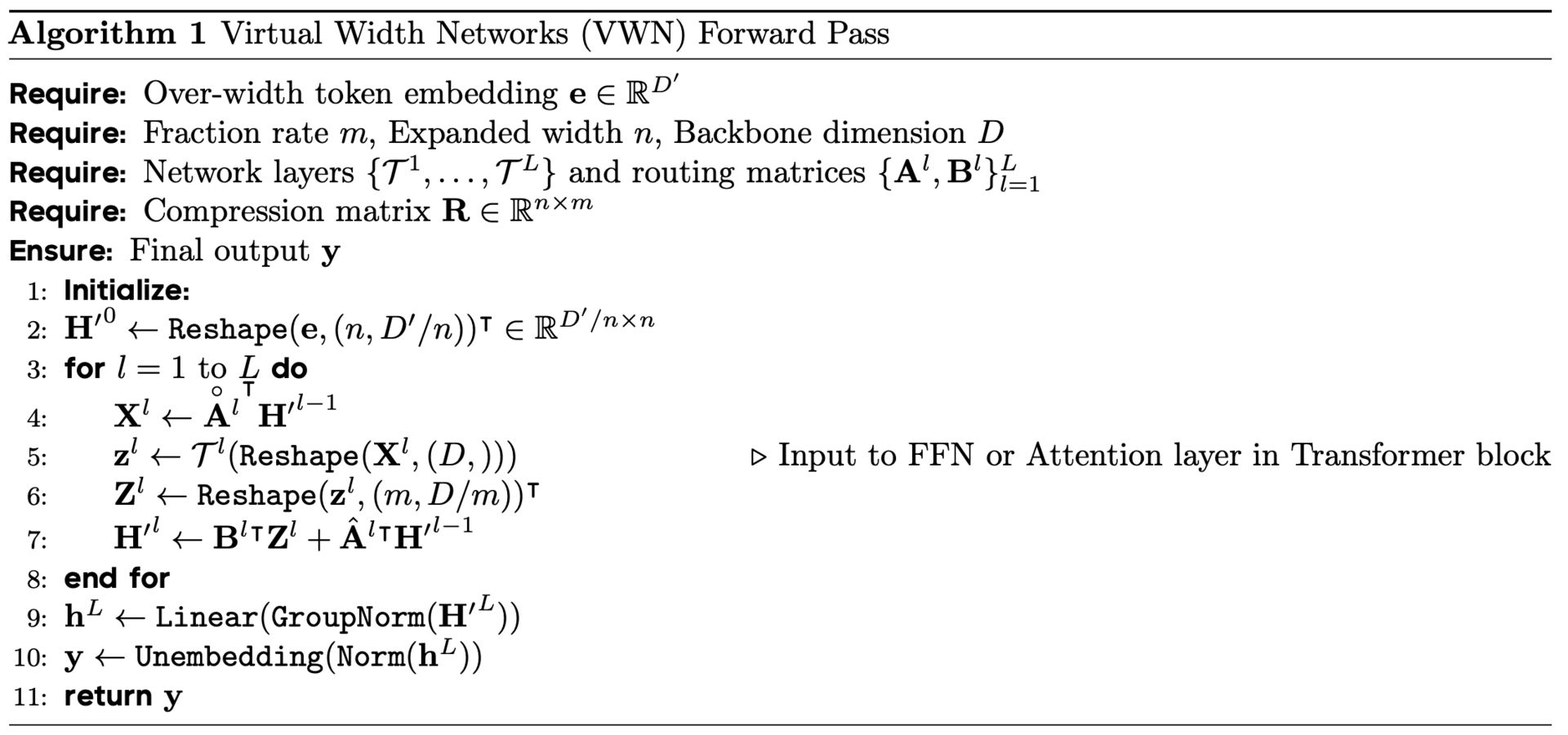
Standard Transformer vs. Virtual Width Network (VWN).
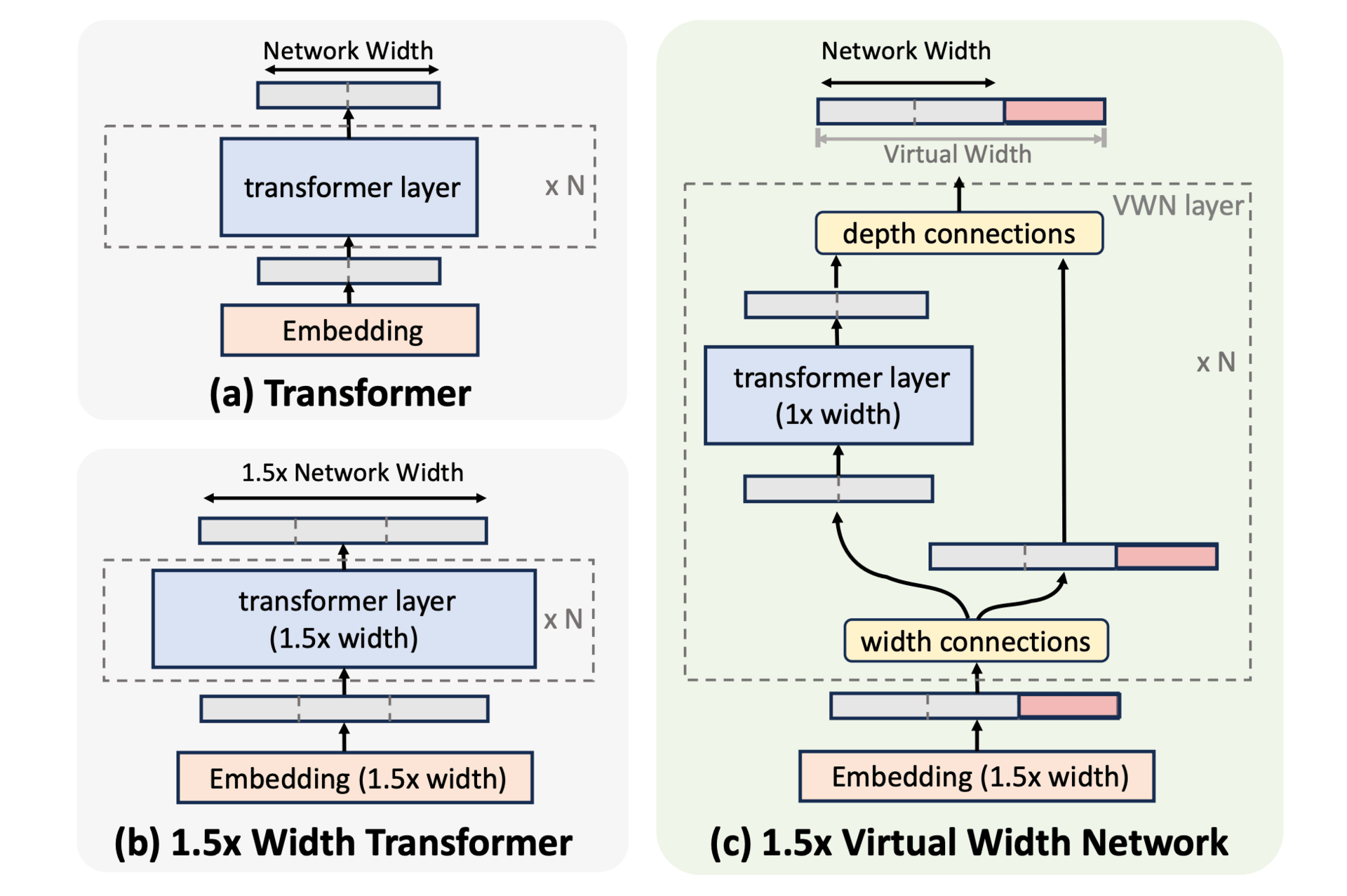
Inside VWN, the process starts with an over-width embedding that packs more information per token. As these widened representations move through the network, Generalized Hyper-Connections act like lightweight adapters. They compress the wide embeddings down to the backbone’s size for each attention and feed-forward operation, then expand the results back to the over-width size before passing them to the next layer. This mechanism allows the model to maintain a high-capacity embedding space without inflating the core computational load.
Overview of Virtual Width Networks (VWN).
To make the most of this expanded space, VWN is paired with multi-token prediction, where the model learns to predict several future tokens at once. This denser supervision helps the model utilize the extra representational freedom effectively. In large-scale tests, an 8× virtual width expansion reached the baseline’s next-token loss using 2.5× fewer tokens and its next-2-token loss with 3.5× fewer tokens, with the efficiency gap growing over time.
SAM 3: Segment Anything with Concepts
Carion et al. [Meta Superintelligence Labs]
♥ 424 Segmentation
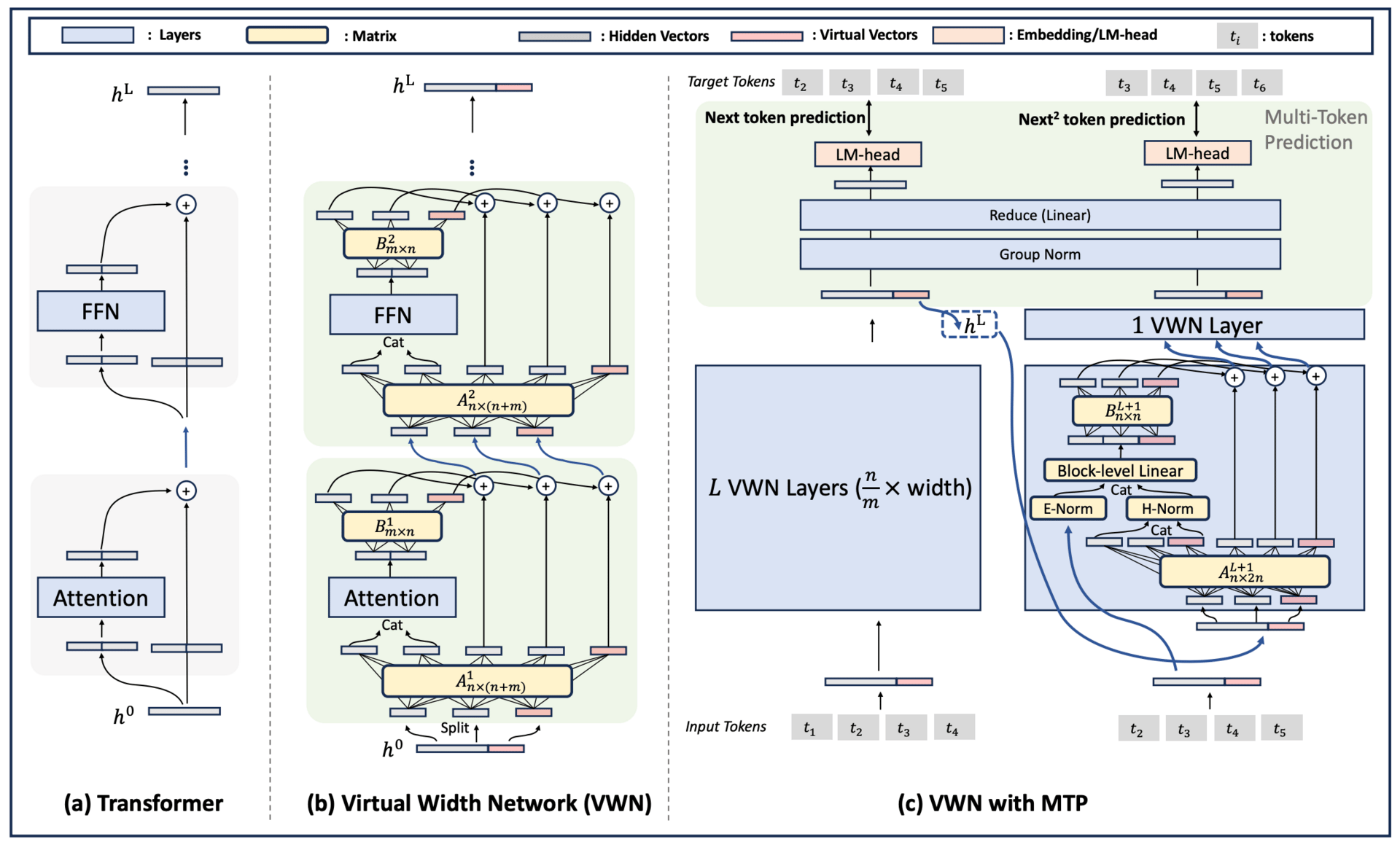
Segment Anything Model 3 (SAM 3) helps computers detect, segment, and track every instance of an object in images and videos using simple prompts like a noun phrase or example image. Earlier models could only segment one object per prompt, but SAM 3 can find all matching objects at once, which makes it much more useful for real-world tasks.
SAM 3 works by combining a detector and a tracker that share the same vision backbone. The detector identifies objects based on your prompt, using a special "presence token" that first decides if the concept is in the image at all. This separation helps the model focus better on where objects are located. The tracker then follows these objects across video frames, using memory to keep their identities consistent even when they move or get temporarily hidden.

In tests, SAM 3 doubled the accuracy of earlier systems and set new standards on the Segment Anything with Concepts benchmark. It runs quickly, processing an image with over 100 objects in just 30 milliseconds.
Evolution Strategies at the Hyperscale
Sarkar et al. [FLAIR - University of Oxford, WhiRL - University of Oxford, MILA– Québec AI Institute, NVIDIA AI Technology Center, CIFAR AI Chair]
♥ 430 LLM Scaling
Training massive neural networks with billions of parameters is a major challenge, especially when using evolution strategies (ES) for optimization without backpropagation. While ES methods excel at handling non-differentiable or noisy goals and scale well through parallelization, the standard approach becomes too slow and memory-heavy for large models. This happens because generating and processing full-sized matrix perturbations across many workers demands immense computational resources.
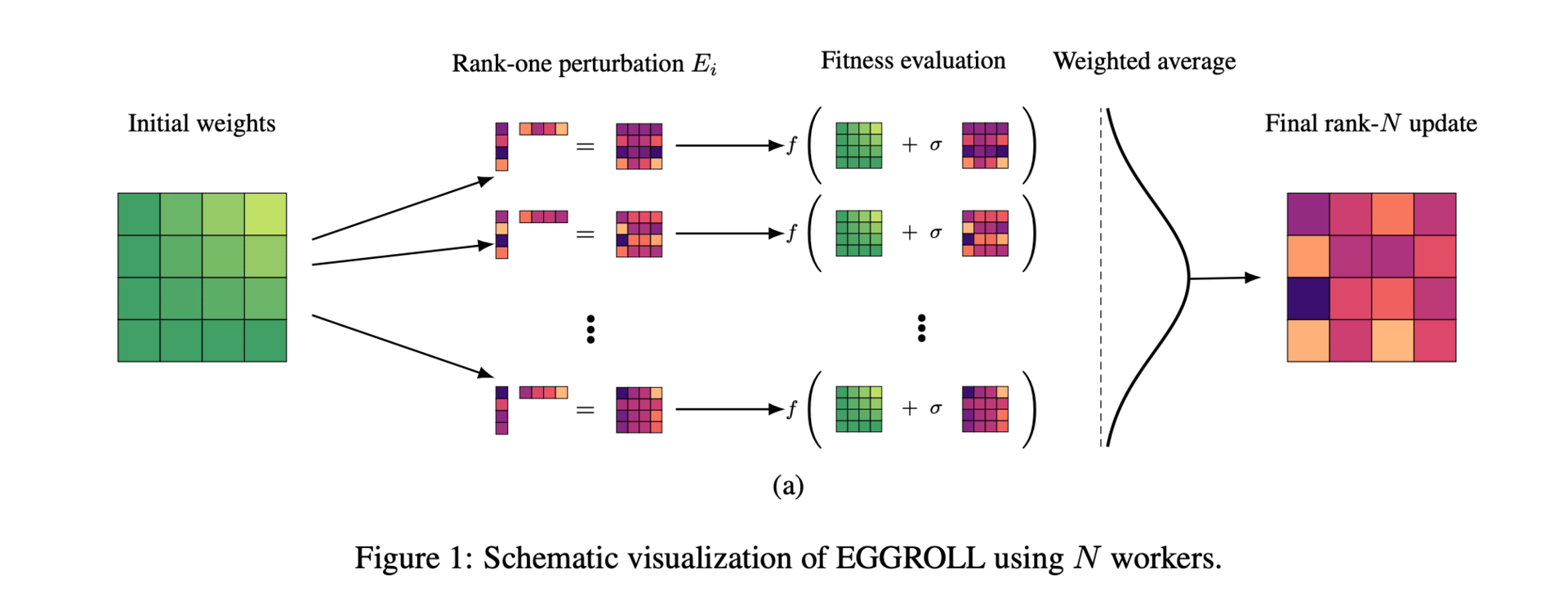
EGGROLL addresses this by employing a low-rank learning technique. It creates two smaller random matrices, A and B, and uses their product to form a low-rank perturbation instead of a full-rank one. This change significantly reduces memory needs and speeds up calculations during forward passes, as the system works with much smaller matrices. Even with a large population of workers, the combined updates remain effective, allowing the method to maintain high performance while cutting down on overhead.
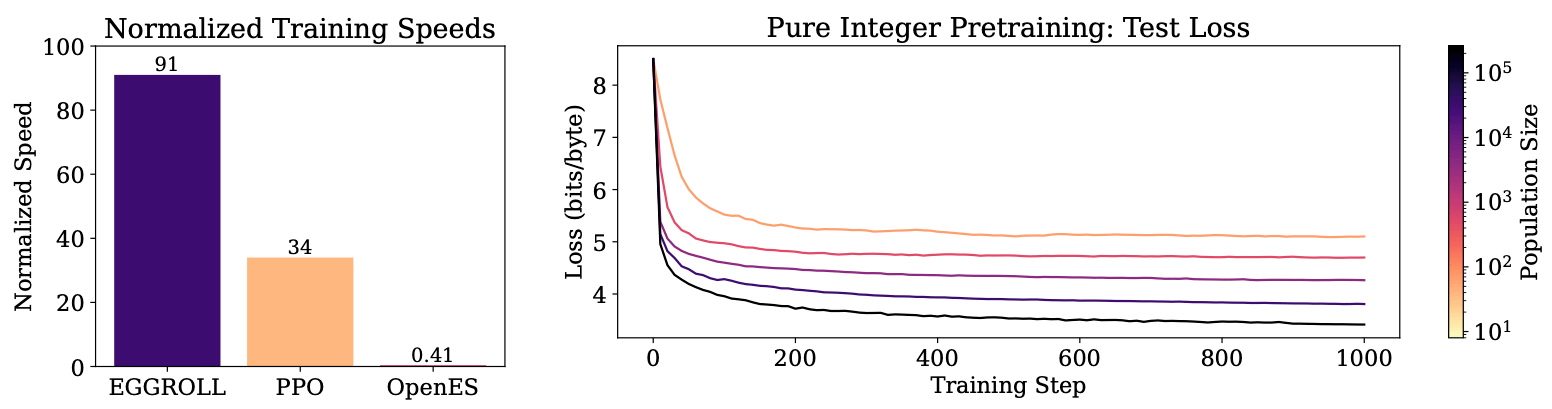
Experimental results show that EGGROLL boosts training throughput by a hundred times for billion-parameter models at large population sizes, nearly matching the efficiency of batch inference. This advance makes evolution strategies far more practical for modern AI systems and makes it a feasible alternative where backpropagation isn't feasible.
Seer: Online Context Learning for Fast Synchronous LLM Reinforcement Learning
Qin et al. [Moonshot AI, Tsinghua University]
♥ 694 RL
Reinforcement learning is important for training large language models, but the rollout phase often slows everything down due to uneven workloads and inefficient resource use. Seer tackles this by noticing that responses from the same prompt tend to have similar lengths and patterns, allowing it to balance the load dynamically and speed up the process.
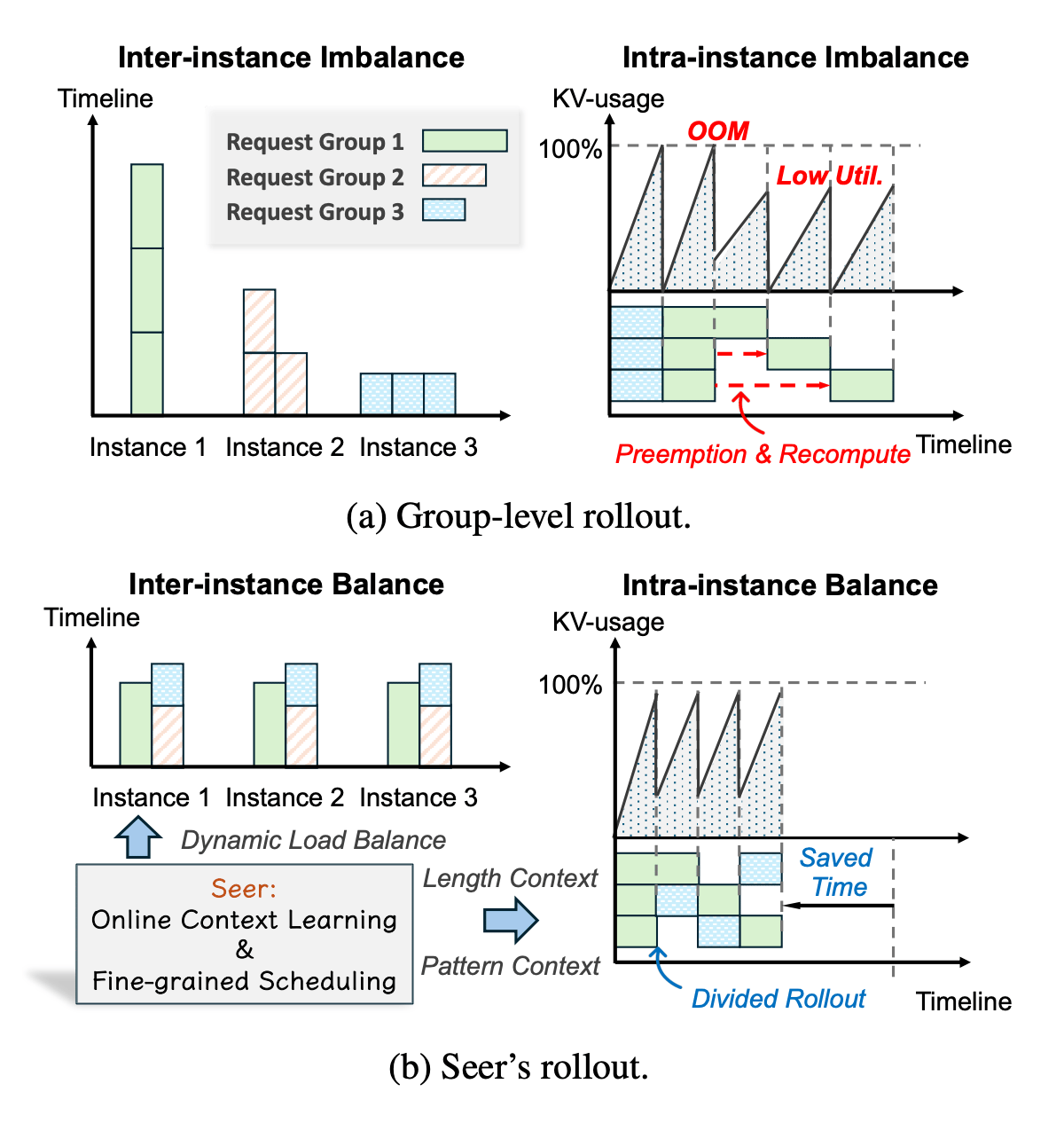
Challenges and Seer’s solution for long-generation rollout.
Seer splits request groups into smaller chunks and schedules them across instances to prevent memory issues and keep GPUs busy. It also uses an early "speculative request" to estimate how long each group will take, helping it prioritize longer tasks and maintain high batch density. Additionally, by building a shared draft token tree from similar responses, Seer enables faster speculative decoding without the overhead of traditional methods.
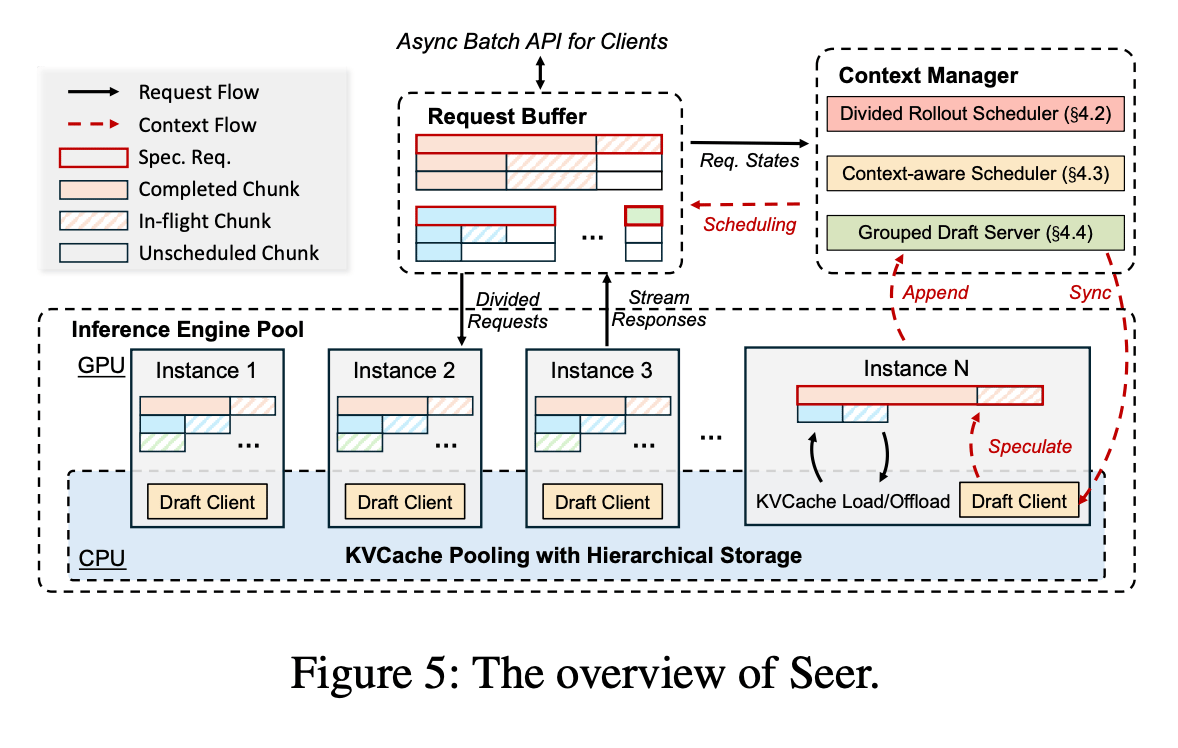
In tests, Seer boosted rollout throughput by 74% to 97% and cut long-tail latency by 75% to 93%, making synchronous RL training much more efficient. This approach could significantly reduce training times for reasoning models, though it’s primarily designed for synchronous settings where strict policy alignment is needed.
ARC Is a Vision Problem!
Hu et al. [MIT]
♥ 868 Vision LLM bycloud’s pick
ARC has long challenged AI systems with its puzzle-like visual tasks, but most approaches treat it as a language problem. VARC rethinks this by viewing ARC as an image-to-image translation task.
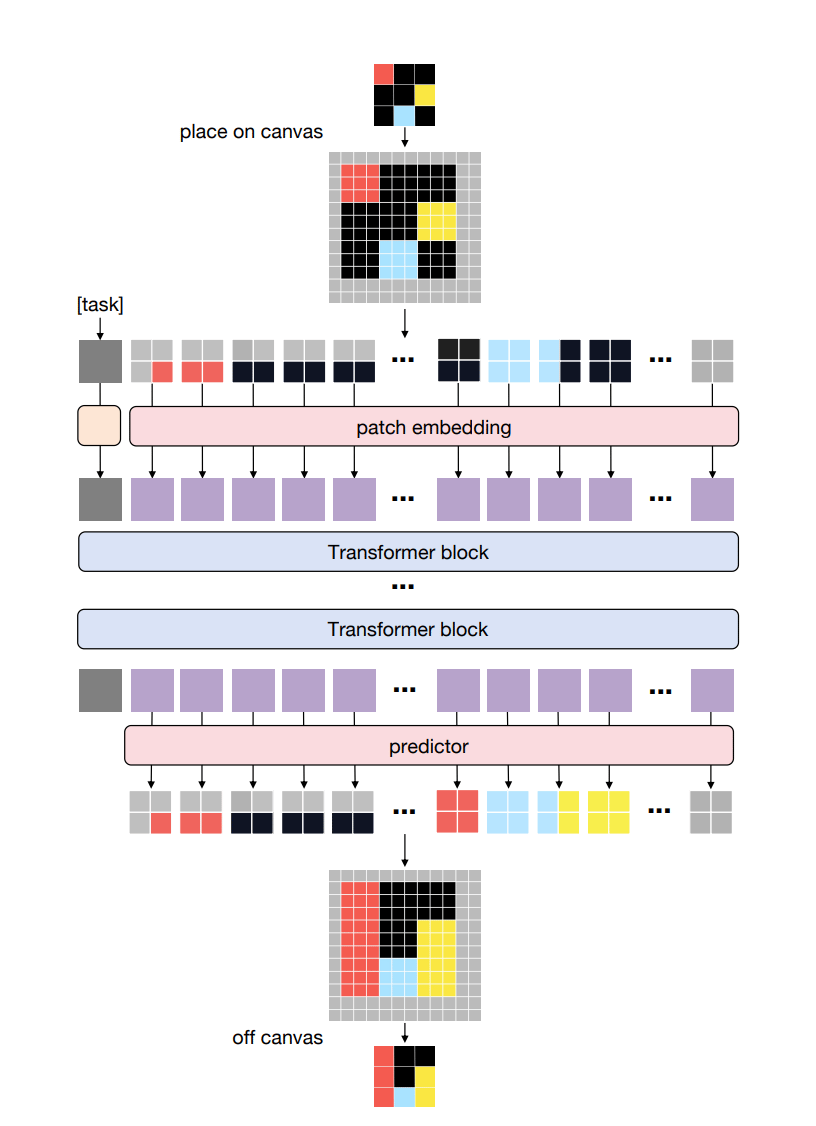
The ViT architecture in VARC
The method represents each task on a "canvas" that acts like a natural image, allowing standard vision models like Vision Transformers to process it. By using patches that group nearby pixels, the model learns spatial relationships and visual patterns rather than memorizing rules. This setup also supports data augmentations like scaling and shifting the input, which help the model generalize to new tasks it hasn’t seen before.
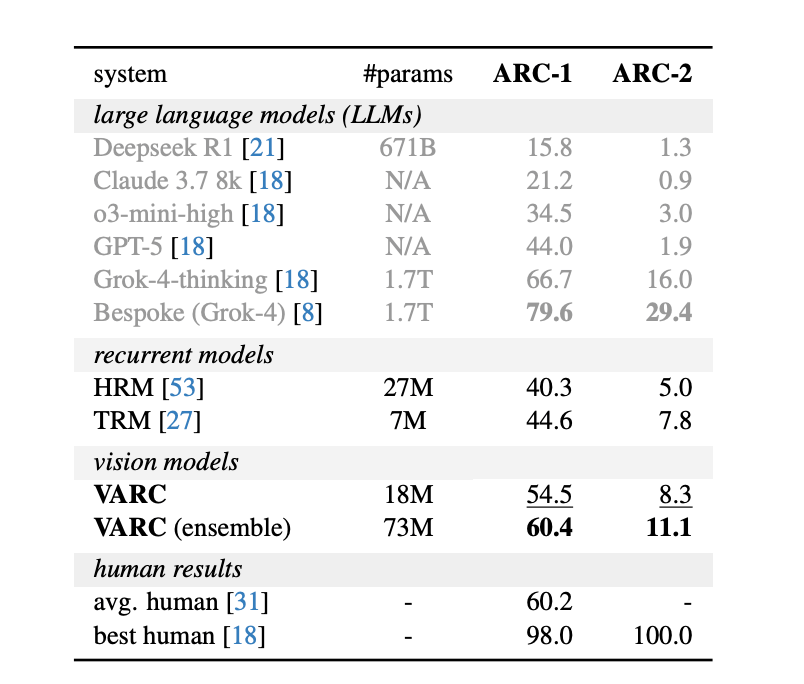
System-level comparisons on the ARC-1 and ARC-2 benchmarks.
In tests, VARC achieved 60.4% accuracy on the ARC-1 benchmark when using an ensemble, matching average human performance. This shows that vision-centric models, trained only on ARC data, can compete with large language models that rely on internet-scale pretraining.
Reply