- The AI Timeline
- Posts
- June 2025 Research Trend Report
June 2025 Research Trend Report
Premium Insights: A recap of popular AI research papers and research trends in June 2025
by cloud
July 07, 2025
Table of Contents
In June, we saw approx. 7% decrease in research publications compared to May 2025, which is a surprise given that at the same time last year we saw a 33% increase in research volume from May to June. On the other hand, compared to the same month last year, there is still a 169% increase in research papers published in June.
In the May 2025 research report, we talked a lot about our understanding of RL and this month we are seeing more research papers improving the existing RL frameworks like RLVR (RL with Verifiable Rewards) In early June.
Other than this central theme, we will also examine other developments in scaling, multimodal integration, computational efficiency, and architectural improvements.
Improving Reasoning with RL
The most popular area of research this month was the application of RL to enhance the reasoning abilities of LLMs.
But this time, it involves dissecting the entire thought process, rewarding exploration, penalizing flawed logic, and optimizing the very path a model takes to reach a solution. This effort is branched into several key areas:
Understanding the core mechanics of RL in this context
Developing new algorithms and frameworks
Improving the crucial components of reward modeling to provide feedback a lot more precisely.

One of the major ways to precisely provide feedback with reward models is through measuring entropy. The key insight came from the paper Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning. This paper found that the vast majority of tokens in a chain-of-thought are not critical for learning. Instead, a small minority of "high-entropy" or "forking" tokens, where the model faces a genuine decision point in its reasoning path, are the primary drivers of improvement.
By concentrating RL policy updates exclusively on these important tokens, the authors achieved performance comparable to or even better than full-gradient updates, which suggests a much more computationally efficient path toward enhancing reasoning.
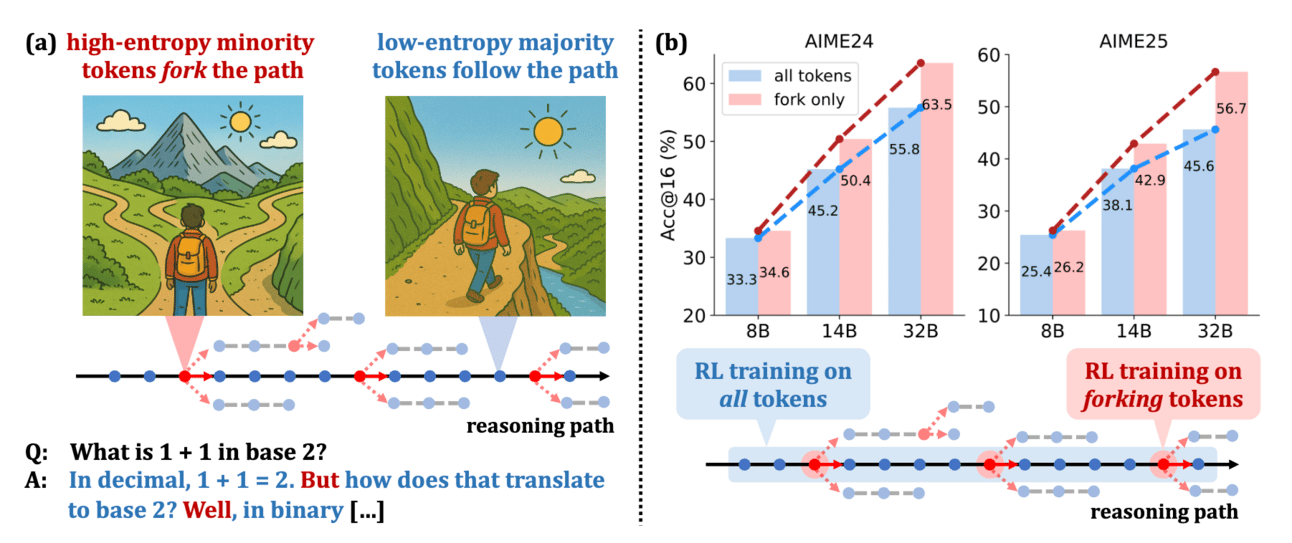
In CoTs, only a minority of tokens exhibit high entropy and act as "forks" in reasoning paths, while majority tokens are low-entropy.
Reply