- The AI Timeline
- Posts
- Last Week's Trending Papers 📈
Oct 13th ~ Oct 19th
#78 Latest AI Research Explained Simply
🗞️ Industry News in 1 Line
♥ 7.2k Anthropic has released Claude Haiku 4.5, a new small AI model that matches the coding performance of the previous state-of-the-art Sonnet 4 model but at a fraction of the cost and more than double the speed. It is available as a drop-in replacement on the Claude API and major cloud platforms like Amazon Bedrock and Google Cloud.

♥ 1.5k NVIDIA CEO Jensen Huang has personally delivered a new DGX Spark AI supercomputer to Elon Musk at SpaceX's Starbase rocket factory. The DGX Spark is a desktop-sized computer that can perform one petaFLOP of AI operations at FP4 precision, delivering five times the performance of its predecessor for creators, researchers, and developers. View early reviews of DGX Spark AI or buy it today at $4K.
♥ 11k Anthropic has launched "Skills" for its Claude AI, a new feature that allows the model to instantly load specialized knowledge on-demand. These Skills are simple folders containing instructions and resources that are loaded using "progressive disclosure" (a technique that prevents context window overload by only pulling in information as needed). This architecture empowers anyone to customize the AI for specific tasks without complex programming. Read the Anthropic cookbook to get started with skills.

♥ 1.4k ManusAI has launched an upgraded no-code platform that generates, builds, and deploys full-stack websites and AI-native applications from a single prompt. The new version cuts development tasks from fifteen minutes down to approximately four. Users can now embed sophisticated AI features directly into their sites, including brand-specific chatbots, image recognition cameras, and dynamic content generators.

Support My Newsletter
As I aim to keep this newsletter free forever, your support means a lot. If you like reading The AI Timeline, consider forwarding it to another research enthusiast. It helps us keep this up for free!
Recursive Language Models
Zhang and Khattab [MIT CSAIL]
♥ 22k Image Generation
Recursive Language Models (RLMs) offer a fresh way to handle extremely long inputs by allowing language models to break down tasks and call themselves or other models as needed. This approach helps overcome "context rot," where model performance drops as the context grows too large.
RLMs work by wrapping a language model in a system that can manage and explore the input context step by step. The root model starts with just the query and interacts with an environment where the full context is stored as a variable. It never sees the entire context all at once, which keeps its own input window clear. The model can write and run code to examine parts of the context, search for patterns, or summarize sections. When it needs deeper analysis, it can launch recursive calls to itself or a smaller model, passing along specific portions of the context to work on.
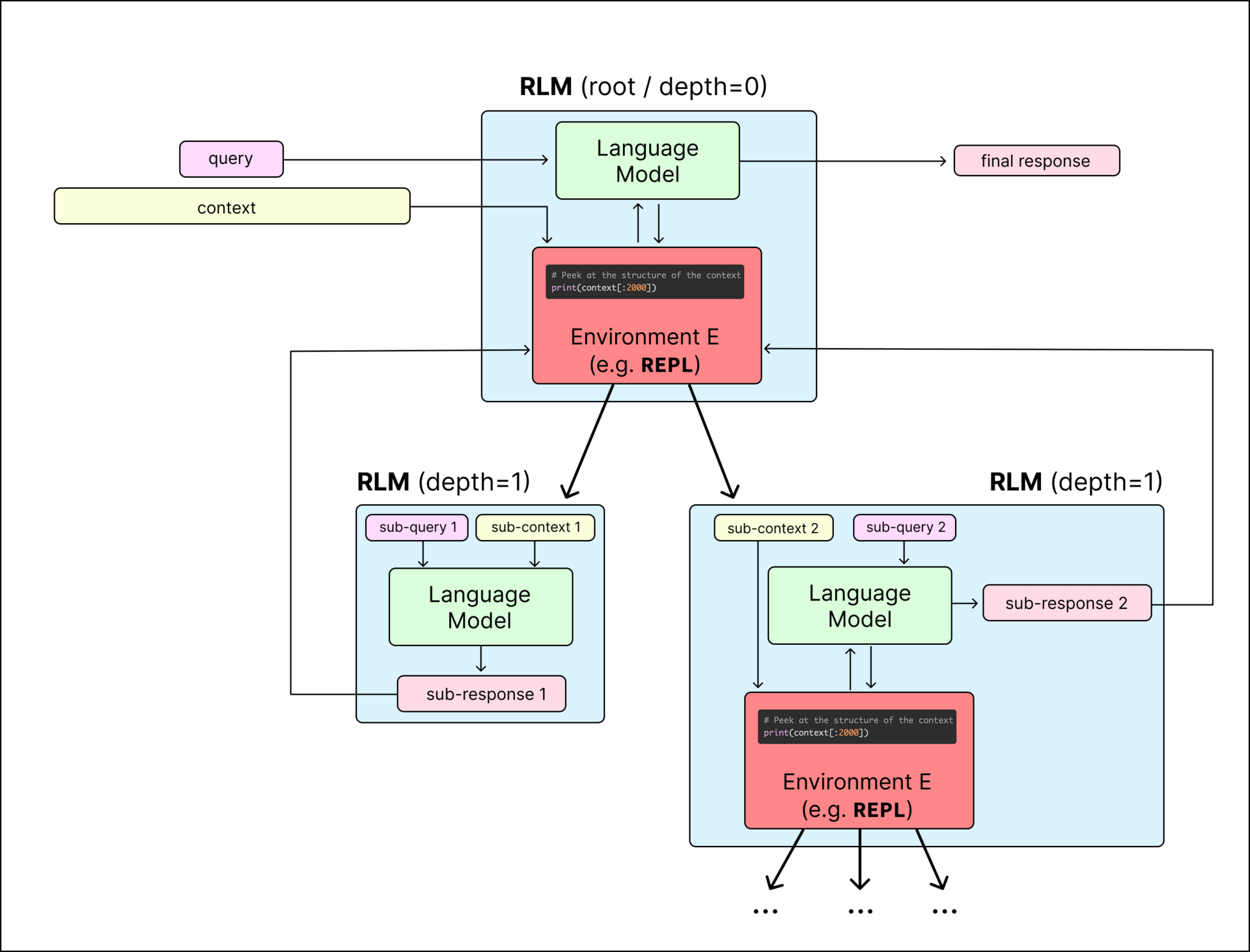
An example of a recursive language model (RLM) call, which acts as a mapping from text → text, but is more flexible than a standard language model call and can scale to near-infinite context lengths.
This setup lets the model adaptively handle huge amounts of information. For example, it might start by scanning the first few lines, then use regular expressions to find relevant entries, or split the context into chunks and assign each to a recursive call. The model builds up its answer gradually, using the notebook environment to store intermediate results. When ready, it outputs a final response either directly or by referencing a variable from the notebook. This flexible, program-like interaction allows RLMs to scale to near-infinite context lengths without overloading any single model call.
In tests, RLMs showed strong results on challenging long-context tasks. On the OOLONG benchmark, an RLM using GPT-5-mini more than doubled the performance of GPT-5 itself, while keeping costs comparable. Even as context length increased to around 263,000 tokens, the RLM maintained a significant lead. On the BrowseComp-Plus benchmark, which involves searching through thousands of documents, the RLM achieved perfect accuracy with 1,000 documents in context.
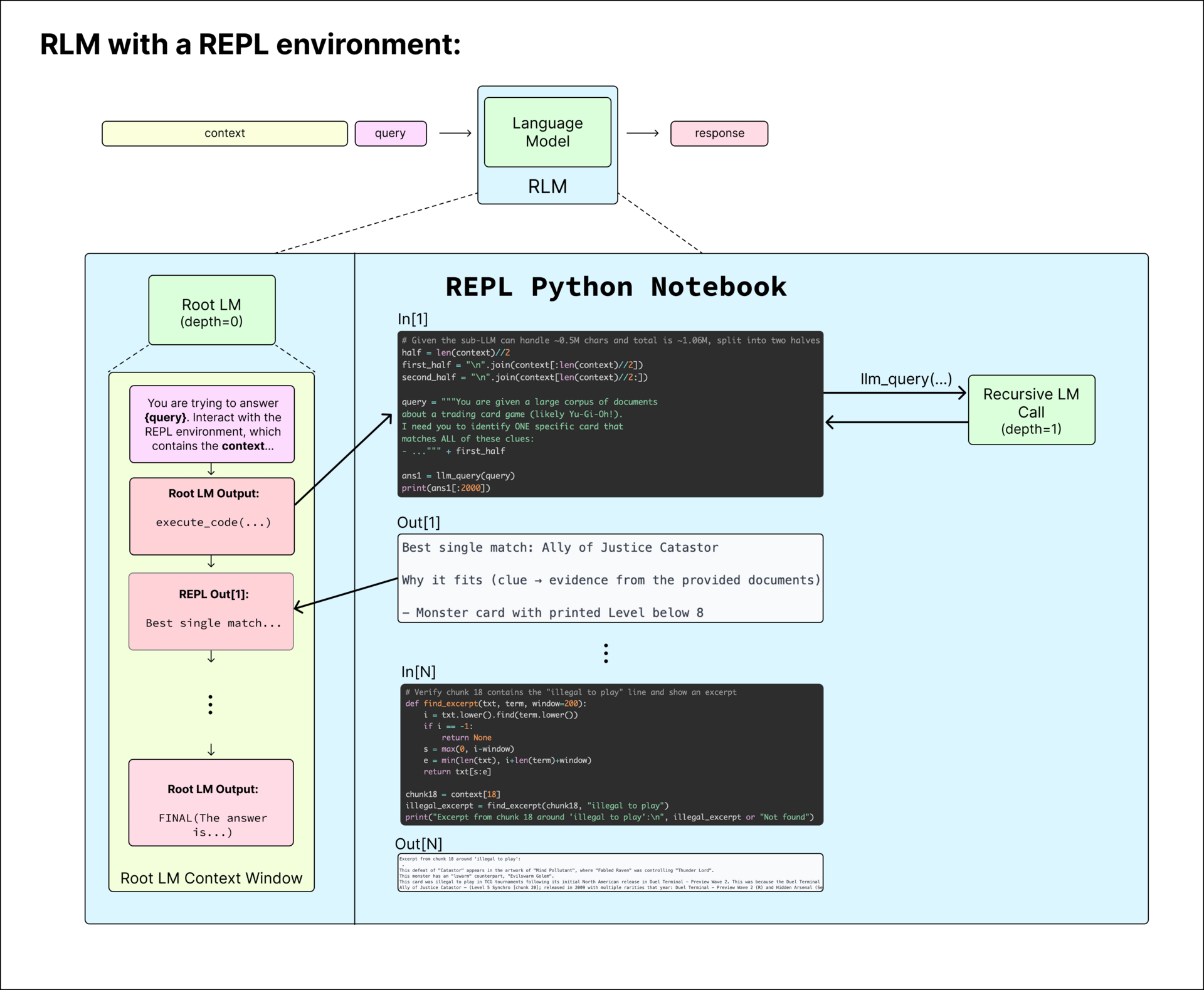
The RLM framework provides the root LM with the ability to analyze the context in a Python notebook environment and launch recursive LM calls (depth=1) over any string stored in a variable.
Diffusion Transformers with Representation Autoencoders
Zheng et al. [New York University]
♥ 424 VAE bycloud’s pick
Latent generative modeling relies on autoencoders to compress images for diffusion, but the standard VAE approach has seen little improvement. This paper introduces a new method called Representation Autoencoders (RAEs) that replaces VAEs with pretrained encoders like DINO and offers richer latent spaces and better performance for diffusion transformers.
RAEs use a frozen pretrained encoder, such as DINOv2, to convert images into high-dimensional tokens. These tokens capture both fine details and semantic information. A separate decoder, trained with reconstruction losses, maps these tokens back to images, which results in sharper outputs than VAEs without heavy compression.
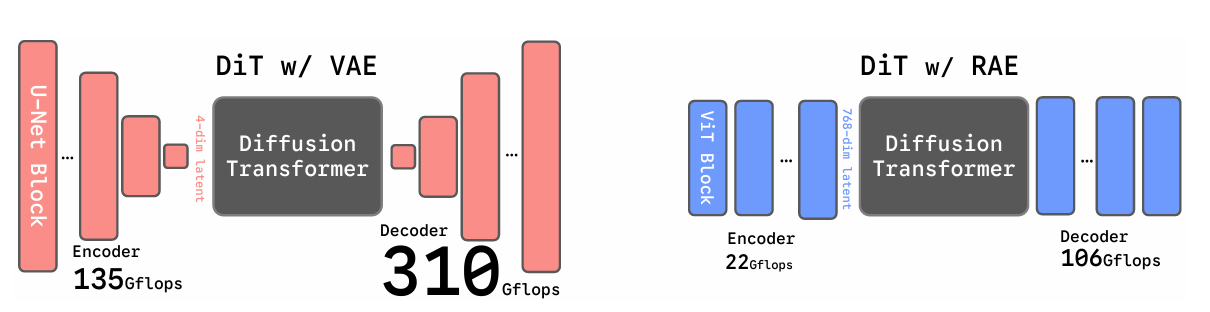
Comparison of SD-VAE and RAE
Diffusion transformers need adjustments to handle these high-dimensional tokens. The model's width must be at least as large as the token dimension to learn the noise patterns during training properly. A dimension-aware noise schedule shift is applied, adjusting the timing of noise addition based on the token size to maintain training stability.
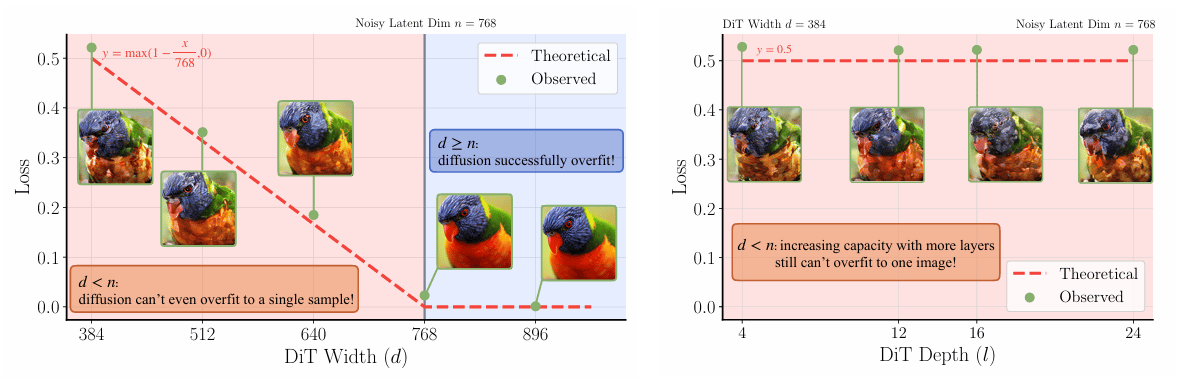
Changing model depth has marginal effect on overfitting results
While RAEs excel in quality and efficiency, they require careful tuning of model width and noise schedules, which may add complexity. The decoder's noise augmentation slightly reduces reconstruction fidelity, though it benefits generation overall.
Not All Bits Are Equal: Scale-Dependent Memory Optimization Strategies for Reasoning Models
Kim et al. [KRAFTON, University of Wisconsin–Madison, UC Berkeley, Microsoft Research]
♥ 430 LLM Scaling Law
When we deploy LLMs for reasoning tasks, it is important to manage memory, especially since the key-value (KV) cache can consume more space than the model weights themselves. This research explores how to best allocate limited memory between model parameters and generation length to maximize accuracy.
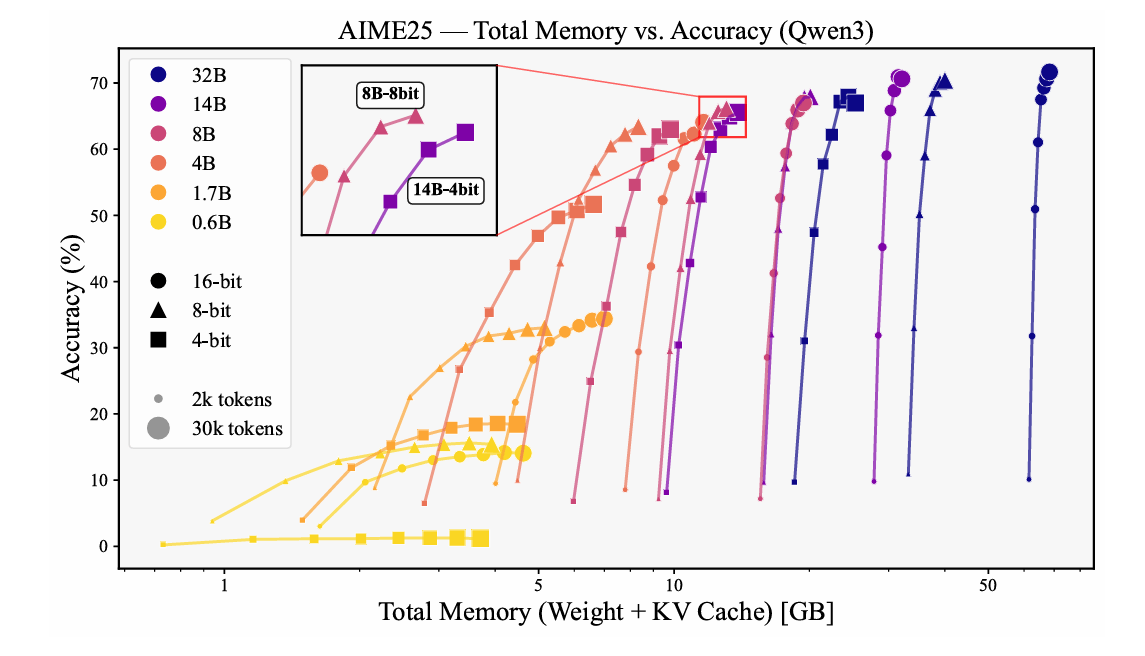
This study finds that smaller models, with effective sizes below an 8-bit 4B parameter model, achieve better performance by dedicating more memory to higher-precision weights rather than extending the generation length. This is because their limited capacity benefits more from precise computations than from additional tokens.
In contrast, larger models see greater accuracy gains when memory is allocated to longer generations, as their robust parameter sets can leverage extended reasoning chains. The research also examines KV cache compression techniques like eviction, which selectively retains important tokens, and quantization, which reduces precision. Eviction works well for smaller models by preserving critical information without numerical errors, while quantization becomes competitive for larger models that are more tolerant to precision loss.
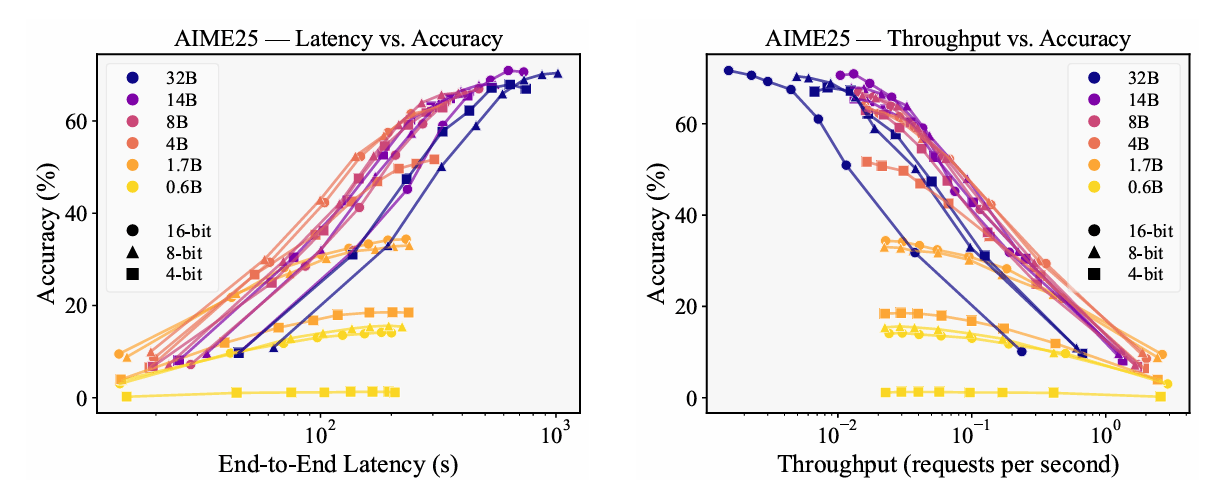
Latency vs. Accuracy trade-offs and Throughput vs. Accuracy trade-offs
Experimental results show that models smaller than 8-bit 4B perform best with weight-focused allocations, while larger models excel with extended generations. For mathematical reasoning, higher weight precision (8-bit or 16-bit) works well, whereas 4-bit suffices for knowledge-intensive tasks.
Reasoning with Sampling: Your Base Model is Smarter Than You Think
Karan and Du [Harvard University]
♥ 855 LLM Sampling
Large language models often improve at reasoning tasks after reinforcement learning training, but a new study asks whether we can achieve similar improvements just by sampling more cleverly from the base model.
This method works by repeatedly resampling parts of a generated text sequence and deciding whether to keep the new version. It selects a random segment in the current output, generates a fresh replacement for that part using the base model, and then compares the overall likelihood of the new sequence to the old one. If the new text is more likely under the model, it is kept; otherwise, the process continues with the original. This iterative refinement allows the sampling process to explore different reasoning paths while favoring those the model finds more plausible.
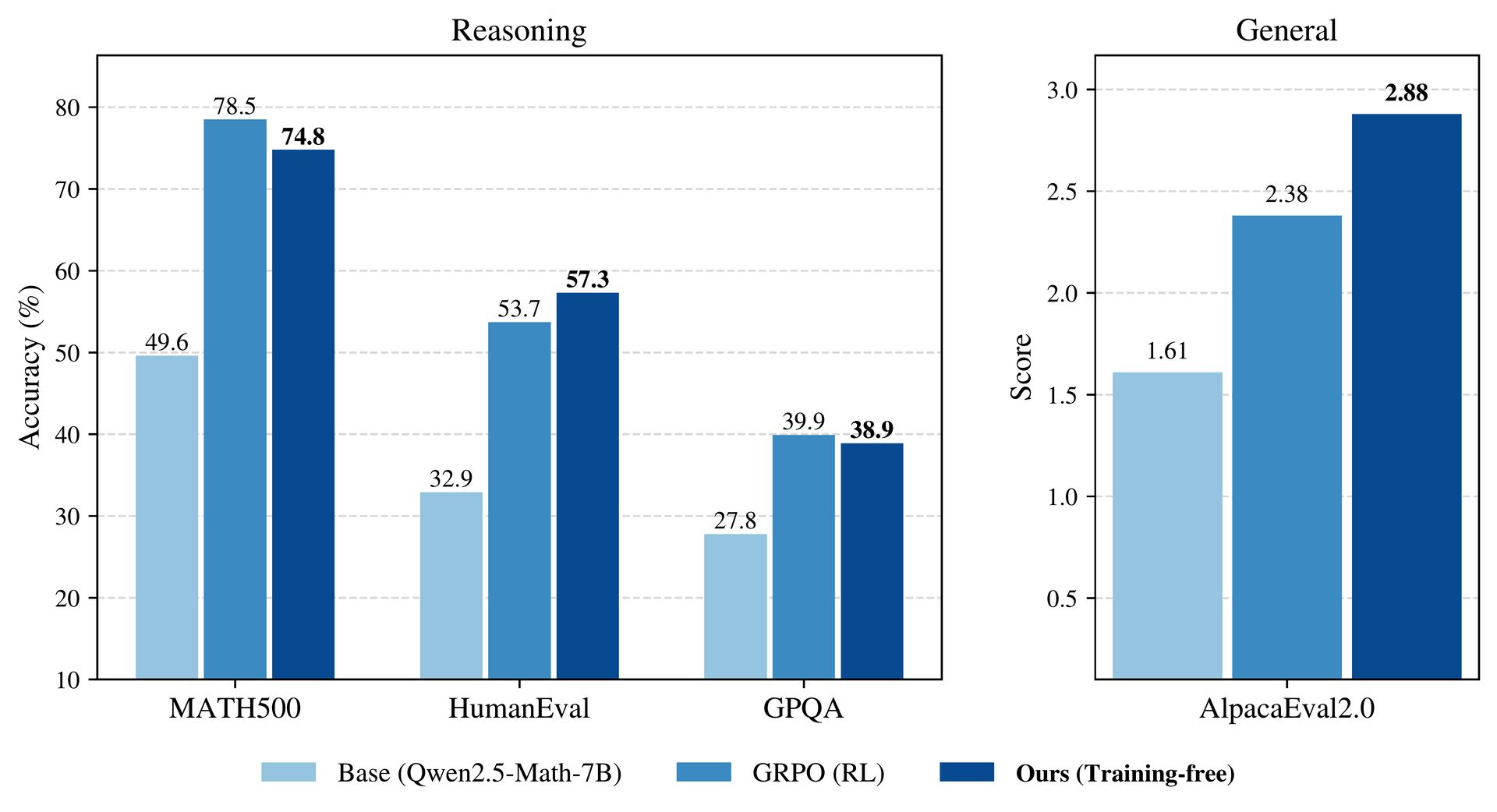
Single-shot reasoning performance of power sampling and GRPO relative to the base model for Qwen2.5-Math-7B.
This approach is inspired by a technique called Metropolis-Hastings sampling. The algorithm breaks the full sequence into blocks and progressively applies the resampling process block by block. At each step, it uses the current block as a starting point and runs several iterations of resampling and acceptance to sharpen the output. The procedure does not require any external reward or training data, relying only on the model’s own probability estimates to guide the sampling toward higher-quality reasoning traces.
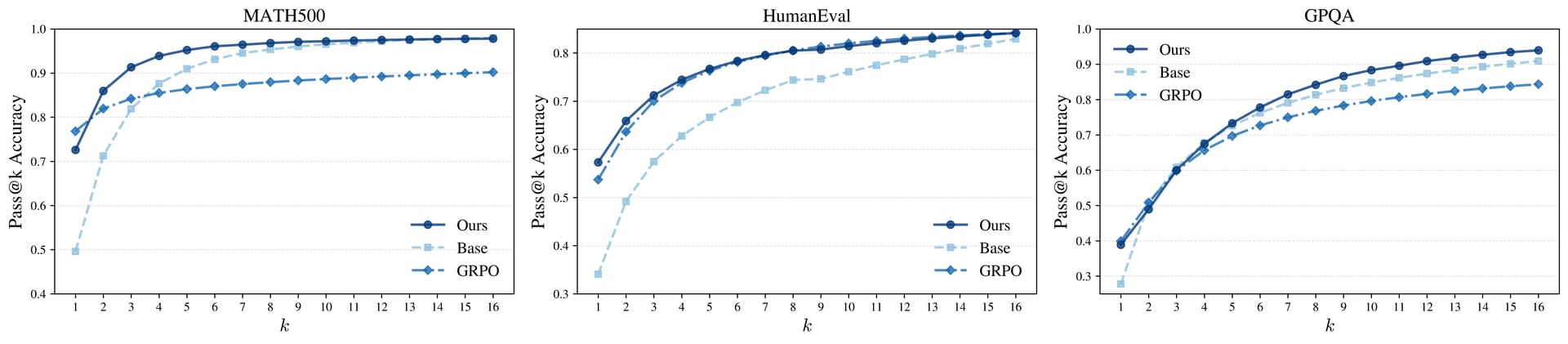
Pass@k performance of power sampling and GRPO relative to the base model for Qwen2.5-Math-7B.
On the MATH500 benchmark, it matched the performance of reinforcement learning post-training and outperformed the RL approach on HumanEval and GPQA. It also maintained better output diversity across multiple samples, avoiding the mode collapse often seen with RL. A key limitation is increased inference-time computation, as the resampling process requires generating more tokens.
The Art of Scaling Reinforcement Learning Compute for LLM
Khatri et al. [Meta, UT Austin, UCL, UC Berkeley, Harvard University, Periodic Labs]
♥ 805 LLM RL
Reinforcement learning enhances LLMs, but scaling it effectively has been more of an art than a science. A new study introduces a systematic framework to predict how RL performance improves with increased compute, which makes the process more reliable and efficient.
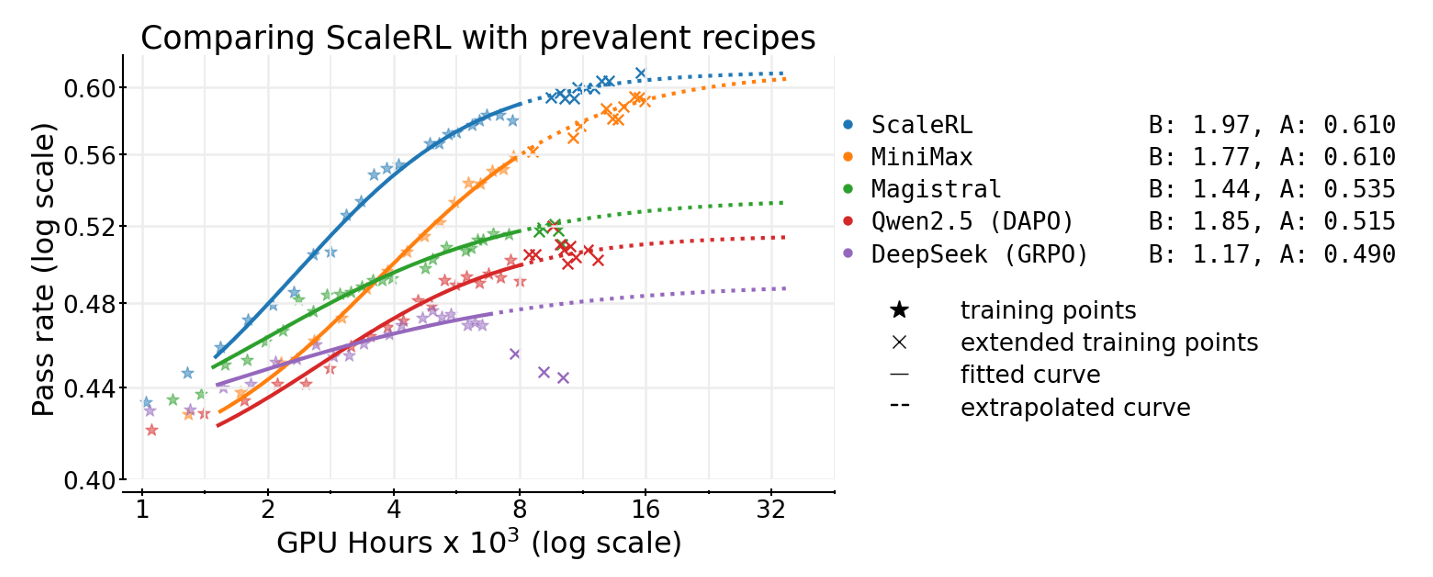
ScaleRL is more scalable than prevalent RL methods.
The researchers developed a method that uses a sigmoidal curve to model the relationship between training compute and model performance. This approach allows them to estimate future performance based on early training data, helping identify which RL recipes will scale well without needing extensive, costly runs. They tested this across numerous design choices, such as loss functions and normalization techniques, to see how each influences both the final performance ceiling and the efficiency of reaching it.
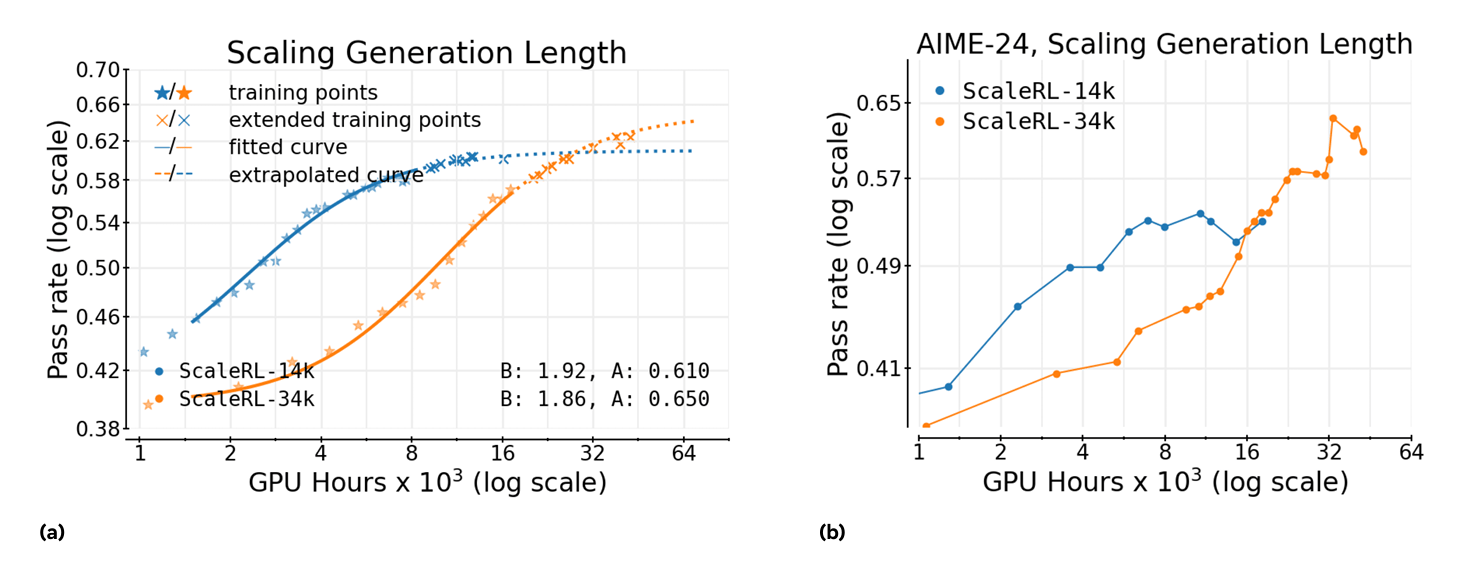
Scaling RL Generation Length.
By analyzing these factors, they found that certain elements, like the type of loss aggregation or advantage normalization, mainly affect how quickly the model learns rather than changing its ultimate capabilities. This insight helps distinguish between methods that look promising at small scales but may not hold up under larger compute budgets.
Do you prefer this new format? |
Reply