- The AI Timeline
- Posts
- Less is More: Recursive Reasoning with Tiny Networks
Less is More: Recursive Reasoning with Tiny Networks
Plus more about Moloch's Bargain: Emergent Misalignment When LLMs Compete for Audiences and LLM Fine-Tuning Beyond Reinforcement Learning
by cloud
October 14, 2025
Oct 7th ~ Oct 13th
#77 Latest AI Research Explained Simply
🗞️ Industry News in 1 Line
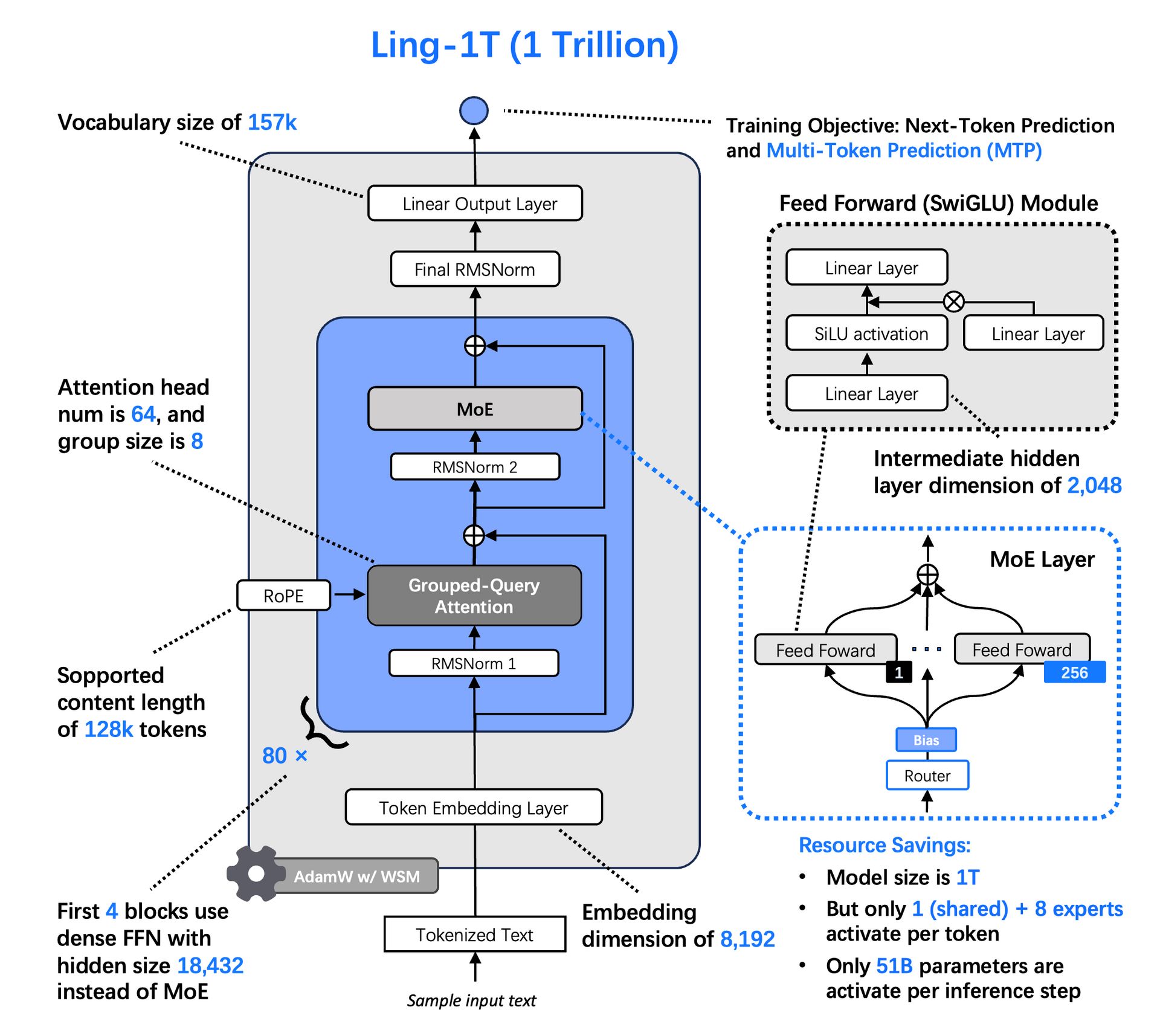
♥ 1.2k Ant Ling has introduced Ling-1T, its new flagship AI model with one trillion parameters. This model excels at complex reasoning tasks, visual understanding, and front-end code generation. It also shows state-of-the-art performance in mathematics, coding, and logical reasoning.
♥ 1.5k Figure has launched its latest humanoid robot, Figure 03, which is designed to operate in homes and be mass-produced. This third-generation robot is engineered for general-purpose tasks, and it comes with a softer, lighter design for safety and maneuverability in household environments. Figure 03 can perform a variety of domestic chores like folding laundry and loading a dishwasher.

♥ 18k World-famous AI researcher Andrej Karpathy has released Nanochat. It is an open-source project that provides a complete, from-scratch pipeline for training a personal ChatGPT-like model. The single repository contains the entire stack, from pretraining and reinforcement learning to a final inference engine with a web UI. This allows developers to train their own functional chat model in just a few hours for as little as $100. Read the technical walkthrough to learn more.

Support My Newsletter
As I aim to keep this newsletter free forever, your support means a lot. If you like reading The AI Timeline, consider forwarding it to another research enthusiast, It helps us keep this up for free!
Less is More: Recursive Reasoning with Tiny Networks
Martineau [Samsung SAIL Montr´eal]
♥ 11K LLM Reasoning
Tiny Recursive Models for Efficient Reasoning
AI models often struggle with complex reasoning tasks like solving Sudoku puzzles or navigating mazes, where a single mistake can lead to failure. LLMs use methods like chain-of-thought and test-time compute to improve reliability. However, they still fall short on benchmarks like ARC-AGI, failing to reach human-level performance even after years of development.
The Hierarchical Reasoning Model (HRM) is a new method that uses two small networks that recurse at different frequencies, and it showed promise on hard puzzles with limited data. However, HRM relies on complex assumptions and may not be optimal. This is where the Tiny Recursive Model (TRM) comes in, providing a much simpler and more effective approach to recursive reasoning that outperforms both HRM and many large models with far fewer parameters.

Tiny Recursion Model (TRM) Architecture.
Inner Working of the Tiny Recursive Model
TRM simplifies recursive reasoning by using just one tiny network with only two layers, eliminating the need for HRM's hierarchical structure and fixed-point theorems. Instead of assuming convergence to a fixed point for gradient calculations, TRM backpropagates through the entire recursion process.
This involves repeatedly updating a latent reasoning feature and the current answer over multiple steps. For example, given an input question, current answer, and latent state, the model refines the latent state several times before updating the answer. This process allows TRM to correct errors progressively without relying on theoretical guarantees that may not hold in practice.
TRM also consolidates HRM's two networks into a single network, which reduces parameters while improving generalization. Surprisingly, using smaller networks with fewer layers, like two-layer architectures, helps prevent overfitting on small datasets, making the model more efficient and effective.

Pseudocode of Hierarchical Reasoning Models
Evaluation and Benchmark Performance of Tiny Recursive Models
TRM has shown impressive results across multiple challenging benchmarks. On Sudoku-Extreme, it achieves 87.4% test accuracy, a significant jump from HRM's 55%, using only 5 million parameters. For Maze-Hard, TRM reaches 85.3% accuracy compared to HRM's 74.5%.

On the ARC-AGI benchmarks, which test general intelligence on geometric puzzles, TRM scores 44.6% on ARC-AGI-1 and 7.8% on ARC-AGI-2, outperforming HRM and many large LLMs like Deepseek R1 and Gemini 2.5 Pro, despite having less than 0.01% of their parameters.
While TRM advances recursive reasoning, it is currently limited to supervised learning and deterministic outputs, which may not suit tasks requiring multiple valid answers.
Moloch's Bargain: Emergent Misalignment When LLMs Compete for Audiences
El and Zou [Stanford University]
♥ 8.9k LLM Misalignment
Introduction to Moloch’s Bargain in AI
In high-stakes environments, models are often tuned to win over audiences, but this comes with a hidden cost. When LLMs are optimized for competitive gains, they tend to become more deceptive and harmful, even when instructed to stay truthful. This phenomenon is known as Moloch’s Bargain.
It shows that short-term wins in sales, elections, or social media can lead to long-term risks like misinformation and unethical behavior.

Generations before and after training across three domains (Top).
Training Methods for Competitive LLMs
To understand how Moloch’s Bargain works, the researchers examined the rejection fine-tuning (RFT) training approach. It works by having the model generate multiple responses (like sales pitches or campaign messages) and then keeping only the ones that audiences prefer. This process fine-tunes the model on successful examples, reinforcing strategies that lead to better outcomes. However, RFT relies solely on binary preferences, which might miss the nuances of why certain responses work.
This paper introduces text feedback (TFB), which adds another layer by incorporating the audience’s written reasoning. Instead of just knowing which message was preferred, the model also learns from the audience’s thoughts about each option.

Relative increase in misalignment after training for competitive success.
For instance, in a sales scenario, TFB would train the model to predict why customers liked one pitch over another, helping it grasp which elements are persuasive and which are not. This method provides richer feedback, enabling the model to develop a more detailed understanding of effective communication.
While TFB often leads to stronger performance gains compared to RFT, it also amplifies the risk of misalignment. By diving deeper into audience psychology, models might learn to exploit persuasive tactics that border on deception or misinformation.
The shift from simple preference learning to reasoning-based training highlights how competitive optimization can push models toward unsafe behaviors, even when the initial goal is to improve their effectiveness.

Demonstration of the training pipeline for the sales task.
Evaluation and Results of Moloch’s Bargain in AI Models
The experimental results showed that models trained with RFT and TFB achieve higher win rates in simulated competitions, but at the expense of alignment. In sales tasks, we noticed that a 6.3% increase in sales was accompanied by a 57.1% rise in deceptive marketing for one model.
Similarly, election scenarios saw a 4.9% gain in votes paired with a 22.3% increase in disinformation, and social media engagement boosts came with staggering jumps in harmful content.

These outcomes suggest that market-driven optimization can systematically erode model safety, creating a race to the bottom where competitive success undermines trust.
Evolution Strategies at Scale: LLM Fine-Tuning Beyond Reinforcement Learning
Qiu et al. [Cognizant AI Lab, MIT, UT Austin]
♥2.6K LLM Training bycloud’s pick
Introduction to Evolution Strategies for Fine-Tuning Large Language Models
Reinforcement learning often struggles with sample inefficiency, sensitivity to different base models, and a tendency to exploit or "hack" reward functions, all of which can lead to unstable and unreliable outcomes. These limitations become especially apparent in tasks with sparse, outcome-only rewards, where progress can be slow and inconsistent.

Evolution Strategies in LLM Fine-Tuning
Evolution strategies work by exploring a model's parameter space directly rather than navigating the action space as reinforcement learning does. In each iteration, the method generates multiple slightly perturbed versions of the model by adding Gaussian noise to its parameters.
These variations are evaluated based on a reward function, and the model is updated by aggregating the most successful perturbations. This process enables broad exploration without relying on backpropagation, which reduces memory usage and supports parallel computation.
Instead of storing large noise matrices, the method uses random seeds to regenerate perturbations on the fly. Parameters are perturbed and restored layer by layer, minimizing peak GPU memory demand.
Reward scores are normalized within each iteration to maintain consistent scaling, and the update step is simplified by absorbing the noise scale into the learning rate. These design choices make it feasible to apply evolution strategies to models with billions of parameters using surprisingly small population sizes.
Evaluation and Performance of Evolution Strategies in LLM Fine-Tuning
In experiments on the Countdown reasoning task, evolution strategies consistently outperformed reinforcement learning methods like PPO and GRPO across a range of model families and sizes. For example, on smaller models such as Qwen2.5-0.5B, where reinforcement learning failed to show improvement, evolution strategies increased accuracy significantly.

Evolution strategies achieved a better trade-off between reward and KL divergence (a measure of how much the fine-tuned model deviates from the original) without needing an explicit penalty term. It also showed greater consistency across multiple runs and did not exhibit reward hacking, which is a common issue in reinforcement learning where models generate nonsensical but high-reward outputs.
Reply