- The AI Timeline
- Posts
- Microsoft just shared the frontier data engineering secrets
Microsoft just shared the frontier data engineering secrets
plus more about If LLMs Have Human-Like Attributes, Then So Does Age of Empires II, Cosmos 3, and Robots Need More than VLA and World Models
by cloud
June 09, 2026
June 3rd ~ June 9th
#111 Latest AI Research Explained Simply
🗞️ Industry News in 1 Line
♥ 12k Google has introduced Gemma 4 12B, an encoder-free multimodal model with Apache 2.0 license that is compact enough to run locally on just 16GB of VRAM. By using a lightweight 35M-parameter vision embedding module rather than a traditional encoder, it delivers advanced, multi-step reasoning capabilities with a significantly reduced memory footprint. You can try it out now on Ollama, Google AI Edge Gallery App, the Google AI Edge Eloquent app or Hugging Face.

♥ 3.9k Alibaba has introduced Qwen3.7-Plus, a new model that delivers text performance which matches Max-tier models across various benchmarks. The release also brings systematic enhancements to its visual understanding capabilities, which are specifically tailored for powering complex multimodal interactive hybrid and browser agents.

♥ 3.4k NVIDIA has released Nemotron 3 Ultra, a new model optimized for complex agentic tasks such as long-horizon planning, large-scale code analysis, and extensive tool calling. The release provides developers with access to the model weights, synthetic data, and post-training recipes tailored for popular agent frameworks. You can try it on Hugging Face.

♥ 1.1k Cognition has announced an "AI Productivity Guarantee" for its AI agent Devin. They are pledging to fund customer usage up to $10 million if the tool fails to deliver proportional engineering value. To support this initiative, the company detailed a newly developed measurement system that estimates an agent's productive output by comparing it to the time a human engineer would require to complete the same task within an enterprise codebase. Read more about gurantee.
Intuitive AI Academy - NEW Optimization Chapter!
My latest project: Intuitive AI Academy has the perfect starting point for you! We focus on building your intuition to understand LLMs, from transformer components, to post-training logic. All in one place.
We just added a new chapter on Optimization, that goes through the history, the key techniques, and the current state of optimizers that frontier model uses.
We currently have an exclusive newsletter offer, where you would get 40% off on the yearly plan for our users.
Use code: TIMELINE
MAI-Thinking-1: Building a Hill-Climbing Machine
The Microsoft AI Team
♥ 3.8k LLM release
Researchers are trying to build AI models, but just building a single impressive model isn’t the end goal. We need to figure out how to continually and reliably improve them. We need to create a system that genuinely learns to reason from the ground up, rather than taking the common shortcut of imitating older AIs.

Overview of the MAI-Base-1 architecture
To solve this, researchers designed what they call a "hill-climbing machine." This is a fully integrated system where data, hardware, and safety tests work together in a continuous loop, supporting a steady, measurable climb toward better reasoning.
The first milestone from this new approach is a powerful model called MAI-Thinking-1. Researchers trained it entirely on a pristine collection of human knowledge, including public code, academic papers, and books, while carefully removing synthetic, AI-generated content.

Pipeline for processing HTML pre-training data.
To do this, the model undergoes a rigorous reinforcement learning climb. During this phase, it learns how to connect chains of thought to solve complex problems, use external tools, and carefully balance the desire to be helpful with the strict necessity of staying safe.

Rank non-invariance in data mixture scaling.
By relying purely on authentic human data and systematic testing, MAI-Thinking-1 has proven itself to be one of the most capable models of its size for complex math, science, and software engineering.
Cosmos 3: Omnimodal World Models for Physical AI
NVIDIA
♥ 2.7K World Model
Let’s imagine a robot that can clear your dining table. To accomplish this seemingly simple task, today's robots must juggle a disjointed collection of artificial intelligence models: one to see the dishes, another to plan movements, and another one to predict what happens if a glass gets bumped.

Cosmos 3 serves as a general-purpose backbone for Physical AI.
Training these physical agents directly in the real world is slow, expensive, and sometimes dangerous. We need to create a single, unified system that handles seeing, reasoning, simulating, and acting.
To solve this, this paper introduced Cosmos 3, which is a versatile model that unites language, video, audio, and physical actions into one continuous stream of thought. Instead of treating sight, sound, and movement as separate programs, this architecture translates all these senses into a shared digital vocabulary.

Cosmos 3 offers a strong starting point for training Physical AI agents.
It is built using a dual-pathway structure. One side focuses on deeply understanding the current environment, analyzing the scene much like a person reads a book. The other side acts as an imagination engine, generating plausible futures. When the AI considers a physical action, like grasping a cup or turning a steering wheel, the system instantly visualizes exactly how the physical world will react.

Unified action representation
This unified mind allows developers to generate rich, interactive simulations to safely train future robots. It proves that when AI can cohesively see, hear, think, and act, bringing helpful autonomous agents into our daily lives becomes a beautiful, tangible reality.
Self-Trained Verification for Training- and Test-Time Self-Improvement
Wu and Raghunathan [Carnegie Mellon University]
♥ 424 LLM Self-training
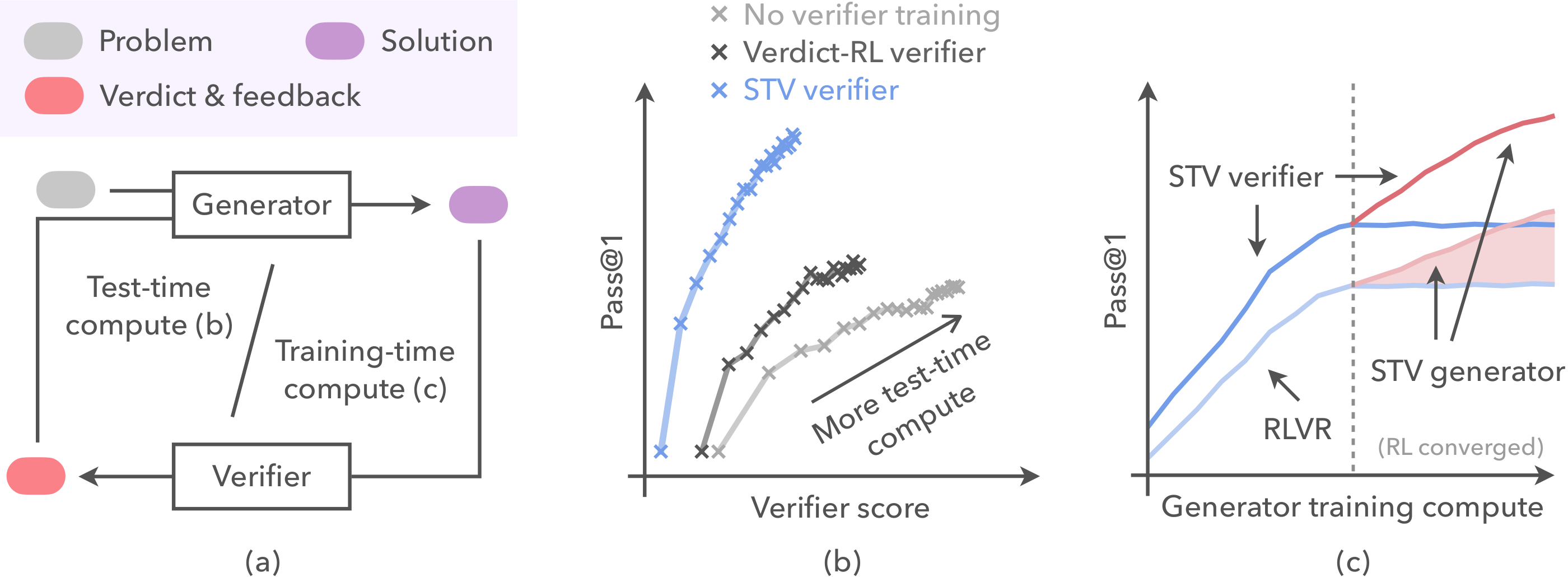
To master advanced reasoning, the AI models need to learn how to catch their own mistakes. We use a system where an AI proposes an answer and an internal "verifier" provides feedback. This mechanism works to some extent, but the verifier cannot spot hidden logical flaws, the system just reinforces its own errors.

Isolating the contribution of trained feedback using ground-truth verdict.
To solve this, the researchers used a simple logic: diagnosing a mistake is much easier when you already hold the answer key. They developed a new method called Self-Trained Verification.
First, they let a "teacher" version of the verifier look at both the AI's flawed attempt and the correct reference solution. With the right answer in hand, the teacher easily identified exactly where the logic failed. Then, they trained the standard verifier to imitate this insightful feedback without ever peeking at the answer key. By matching the teacher's deep critique, the standard verifier learned to catch subtle errors entirely on its own.

Overview of self-trained verification.
When using this self-trained verifier on exceptionally hard math problems, researchers saw accuracy increased dramatically. On complex scientific reasoning tasks, success rates rocketed from just over one percent to twenty-one percent.
If LLMs Have Human-Like Attributes, Then So Does Age of Empires II
Wynter [Microsoft & The University of York]
♥ 11K LLM SuperIntelligence bycloud’s pick
We want to achieve superintelligence and build AI which possess generalized, intrinsic anthropomorphic attributes (e.g., empathy, self-awareness, anxiety, morality). When researchers try to check if a "mind" exists inside the machine, it leads to flawed, circular, or scientifically uninformative conclusions.
To prove their point, the authors take a highly unconventional approach: they demonstrate that a neural network can be trained inside the 1999 video game Age of Empires II (AoE II).
Let’s think of a fully functioning LLM built entirely out of AoE II goats running across a map. If you input "I feel lonely," the goats will shuffle around and eventually output the text: "I feel bad for you, maybe catch up with a friend."
Because you are watching digital goats do math, you would never assume the goats are actually experiencing empathy or understanding.
However, when a standard LLM outputs the exact same text via a sleek chat interface, users and researchers readily ascribe human emotions to it.
This proves that anthropomorphism is an illusion driven by presentation/substrate, not an intrinsic property of the model's mathematics.

Ansatz-based training algorithm for our 1-bit perceptron, as a circuit (top) and as an AoE II implementation.
The authors argue that standard scientific methods fail when researchers assume a model possesses human traits beforehand (the "Accept/Reject Computational Theory of Mind" framework):
Positive Results: If you assume an LLM has empathy and design a test to measure it, a positive result just circularly confirms your underlying assumption.
Negative Results: If the LLM fails the test, the result is completely ambiguous. You don't know if the LLM lacks empathy, or if your test was just poorly designed.
The authors suggest abandoning the debate over whether LLMs have "minds" when conducting empirical research. Instead, researchers should adopt a "null assumption." This means studying an LLM's outputs purely causally and behaviorally rather than jumping to ascribe anthropomorphic intent (a "Geist") to the system.
Robots Need More than VLA and World Models
Karcini et al. [Motoniq.ai, Stanford University, Istituto Italiano di Tecnologia, ETH Zurich, Technical University of Darmstadt, UCL Centre for AI]
♥ 582 LLM Word Models
We have seen text-based AI models trained on the entire internet, but general purpose robots have been stuck learning the hard way. Until now, researchers relied almost entirely on collecting explicitly labeled robot data.
Researchers need to physically guide a robot arm through a task thousands of times just to teach it one simple chore. This process is expensive, slow, and carries the constant risk of hardware damage. Researchers realized that if we want robots to achieve the leaps we have seen in language AI, simply building larger neural networks is an incomplete solution.

Next generation robotics will come from advances that go well beyond scaling vision language action (VLA) models.
The internet has a lot of unstructured behavioral data, like countless internet videos of people interacting with everyday objects. These videos contain rich information about how things move, how forces work, and what a successful task looks like. However, a robot cannot directly use this information because it does not know which of its specific motors to turn to replicate what a human hand does.
To solve this problem, the researchers suggest building a new physical intelligence stack to translate this abundant data. This system can automatically label unstructured behaviors, map human motions onto different robot bodies, predict physical consequences using 3D world models, and allow robots to understand success just by watching.
Reply