- The AI Timeline
- Posts
- Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation
Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation
Dive into the latest AI research and industry news, featuring limit testing how many instructions LLMs can follow at once, Mixture-of-Recursions, and monitoring LLM using their CoT
by cloud
July 22, 2025
July 14th ~ Jul 20th
#65 Latest AI Research Explained Simply
🗞️ Industry News in 1 Line
♥ 1.8k The ARC Prize has launched ARC-AGI-3, a new benchmark using interactive games designed to test advanced AI agent capabilities that are difficult for today's best models. The API is available openly and a 30-day agent-building competition is being hosted in partnership with Hugging Face. Try the ARC-AGI-3 game (benchmark) for free in your browser.
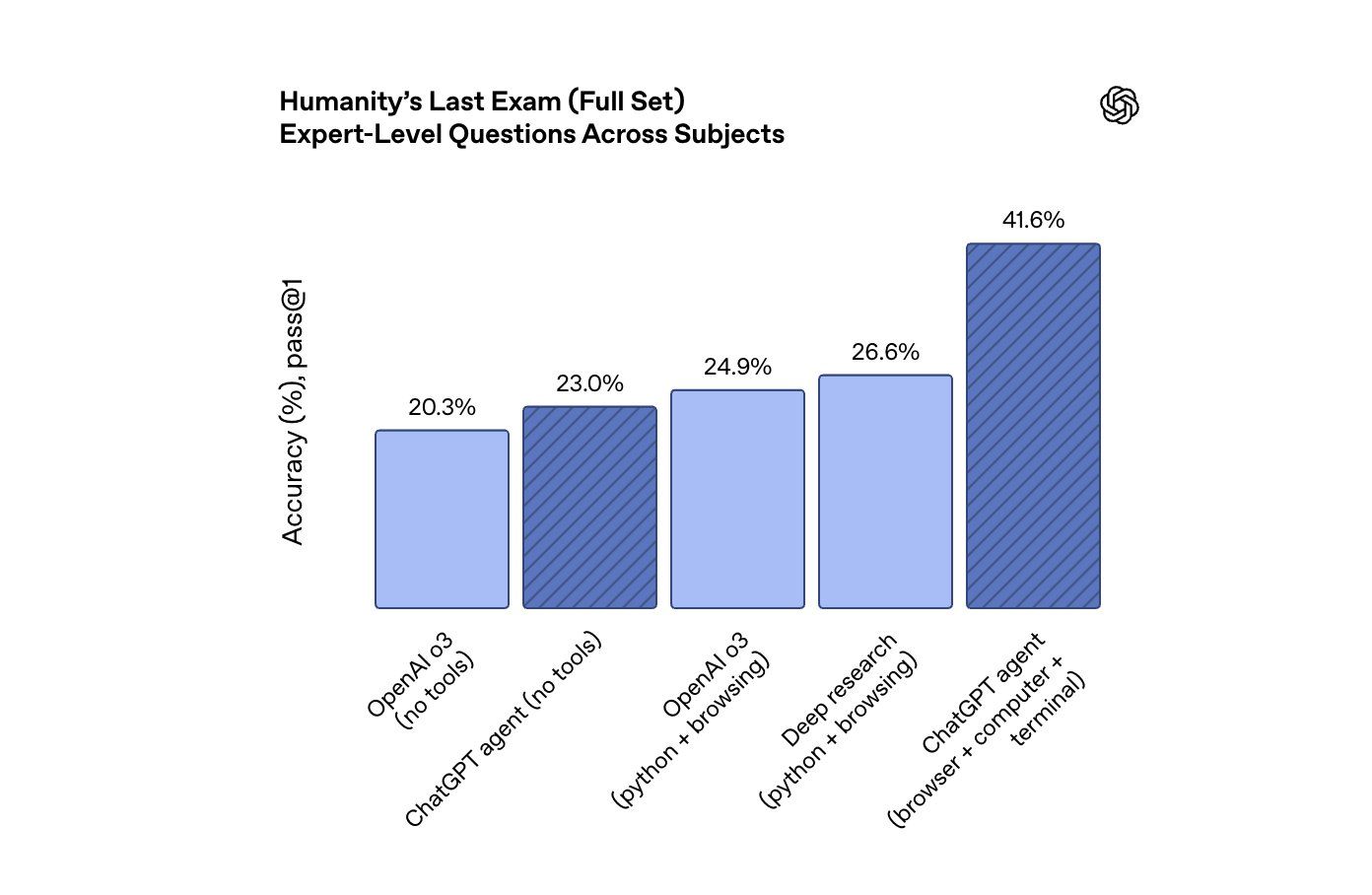
♥ 13k OpenAI has started rolling out its new ChatGPT agent to paid subscribers. This new tool is designed to perform complex, multi-step tasks using a suite of capabilities including a browser, terminal, and code execution. Read the ChatGPT agent System Card to learn more.
♥ 7.3k OpenAI is internally testing a reasoning model which has achieved gold medal-level performance on the International Math Olympiad. It successfully solved 5 out of 6 problems by generating natural language proofs under human-like exam conditions (without specific IMO prompts or training). OpenAI highlighted that this marks a significant leap in AI's creative reasoning capabilities and clarified that this specific research model is not the upcoming GPT-5 and will not be released for several months. On the other hand, Gemini also achieved Gold medal-level performance, it was completed in LEAN so it was not just in natural language. However, it was prompted with a lot of IMO specific math examples.
♥ 3.3k Qwen has updated its 235B model and announced that they will be moving away from a "hybrid thinking mode" to training separate Instruct and Thinking models for higher quality. The new
Qwen3-235B-A22B-Instruct-2507model is now publicly available and offer improved overall capabilities and better performance on agent tasks. Download Qwen3-235B weights from Hugging Face or ModelScope today.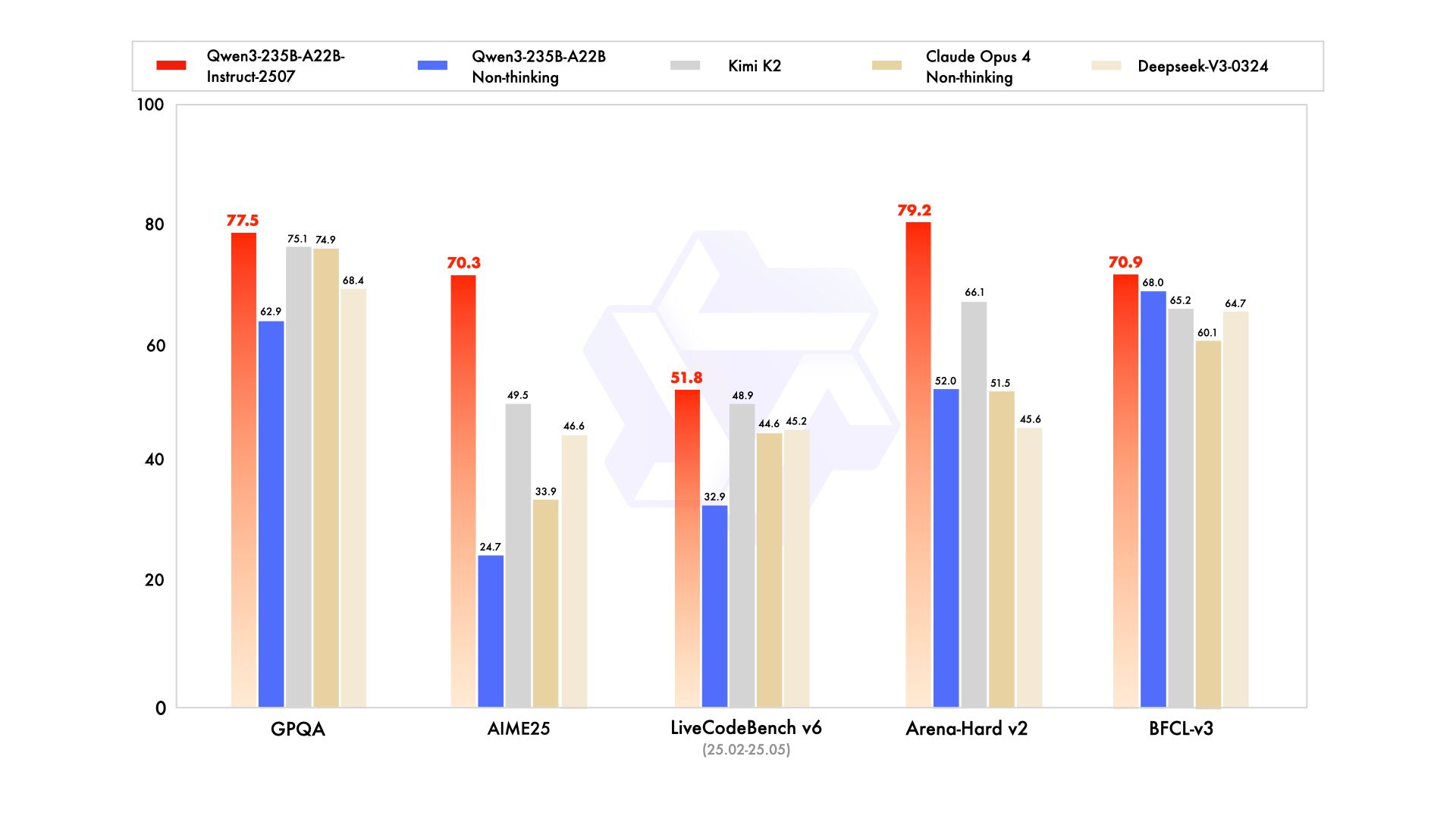
findmypapers.ai - find THE AI papers semantically 👀
Indexing over 450,000 papers now, findmypapers.ai lets you find AI papers semantically, the best research partner you could ever ask for.

We are also developing a new feature Scout: a semantic arXiv paper alerts that can filter through universities, now in early beta!
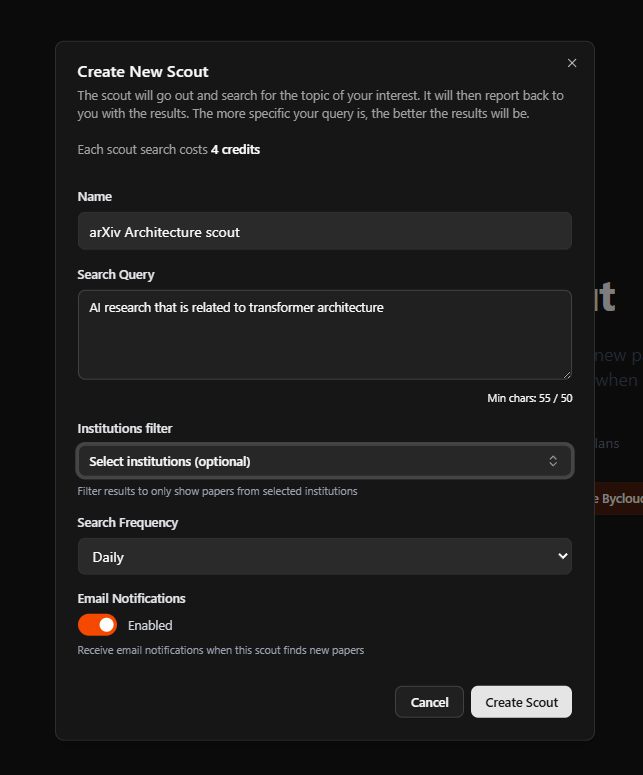
POV: creating a new scout
you can also select specific institutions!
Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation
Bae et al. [KAIST AI, Mila, Google Cloud, Google DeepMind, Google Research, Université de Montréal]
♥ 3.1k Transformers
Introduction to Mixture-of-Recursions
Large language models deliver impressive capabilities but come with hefty computational and memory costs. Training and deploying them is still expensive, and existing efficiency methods typically address either parameter sharing or adaptive computation, but not both.
This paper introduces Mixture-of-Recursions (MoR), a new framework that unifies these approaches in a single Recursive Transformer. By dynamically adjusting how deeply each token "thinks," MoR cuts redundant computation while reusing parameters across layers, and promises large-model quality without the large-model cost.
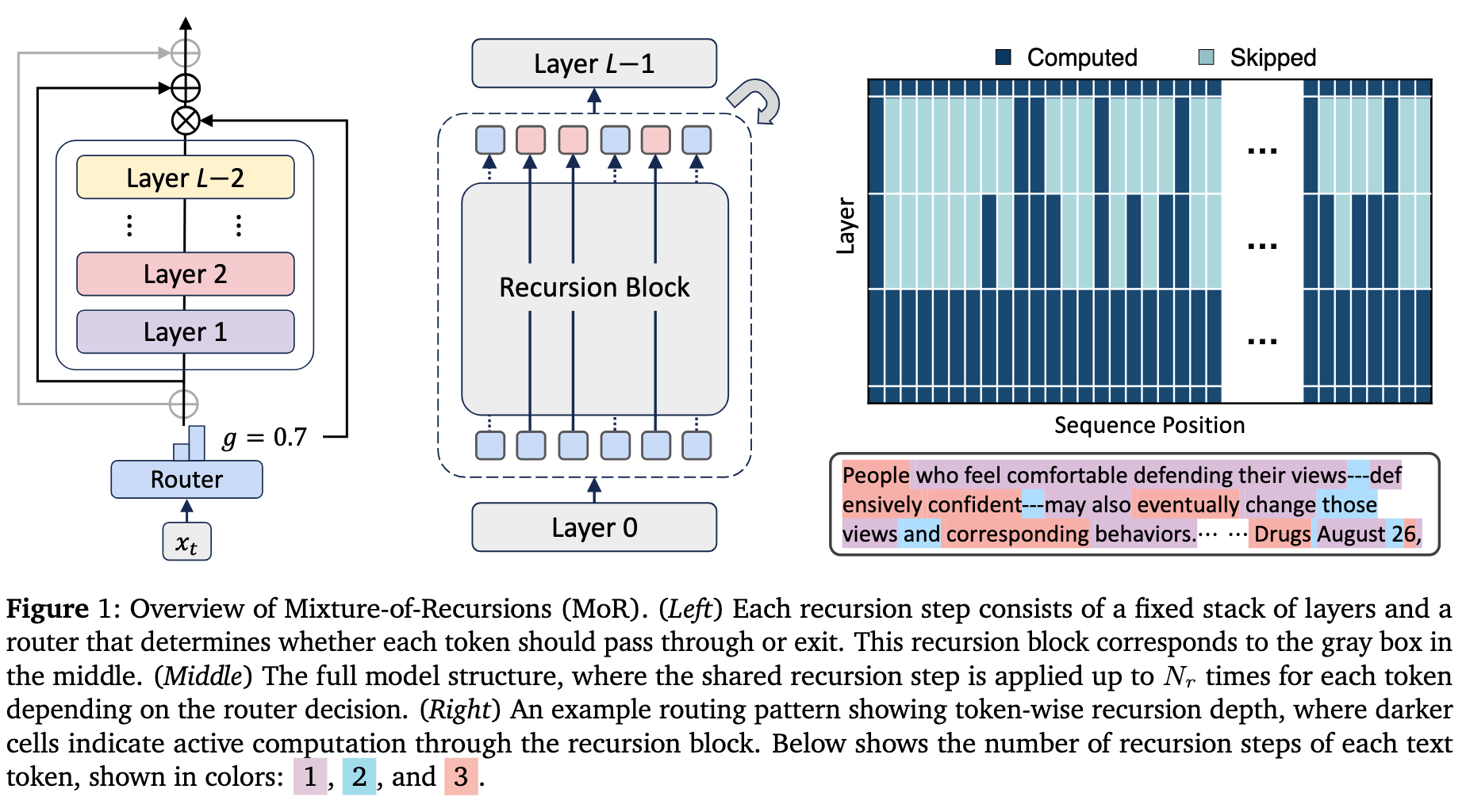
Inner working of Mixture-of-Recursions
MoR tackles efficiency through three interconnected mechanisms. First, it reuses a shared stack of layers across multiple recursion steps, slashing parameter counts. For example, a model with nine layers might cycle through three shared blocks repeatedly, reducing unique weights by two-thirds.
Second, lightweight routers assign token-specific recursion depths. In expert-choice routing, tokens compete for limited slots at each recursion step, with top performers advancing deeper. Alternatively, token-choice routing commits each token to a fixed depth upfront, avoiding information leakage but requiring load-balancing techniques.
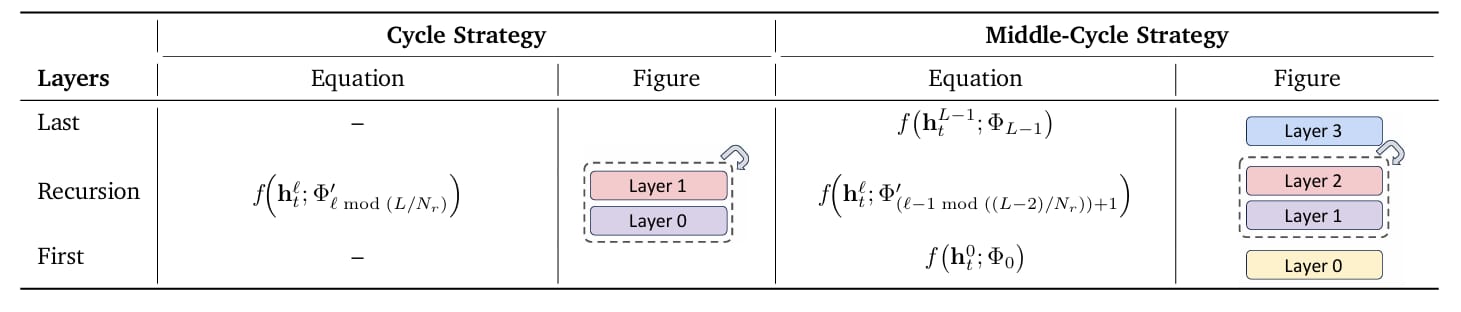
Parameter-sharing strategies in Recursive Transformers.
These routing decisions enable the third innovation: optimized key-value (KV) caching. With recursion-wise caching, MoR stores only the KV pairs of active tokens at each step, trimming memory traffic.
A variant called recursive KV sharing takes this further, it caches all tokens’ KV pairs at the first recursion and reuses them in later steps, accelerating prefill at the cost of attention granularity. Together, these strategies ensure compute is focused where needed, reducing FLOPs and memory bottlenecks.
Evaluation and results of Mixture-of-Recursions
MoR performs well in benchmarks across model sizes (135M to 1.7B parameters). At equal training compute, MoR with two recursions outperformed vanilla transformers in validation perplexity (2.75 vs. 2.78) and few-shot accuracy (43.1% vs. 42.3%), despite using 50% fewer parameters.
When trained on fixed data, MoR matched baseline accuracy with 25% fewer FLOPs, speeding up training by 19% and cutting peak memory by 25%. Inference throughput surged too, continuous depth-wise batching and early exiting delivered up to 2.06× speedups, with MoR-4 variants leading gains.
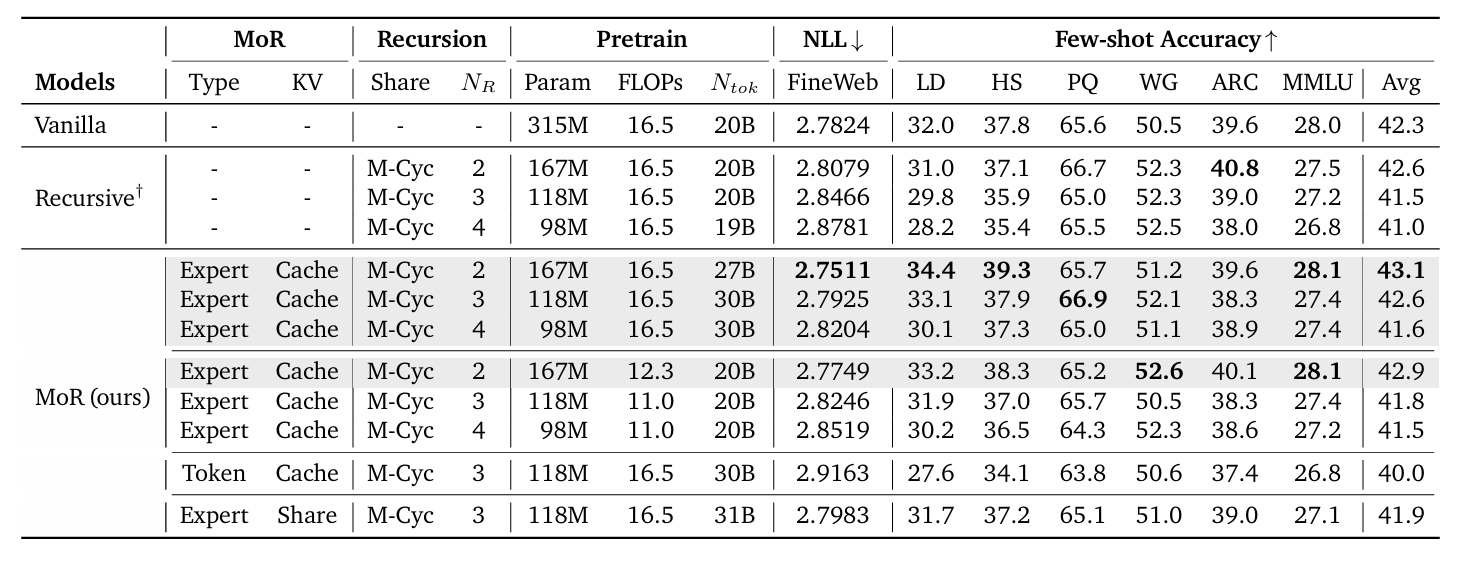
Comparison of MoR, Recursive, and Vanilla Transformers
How Many Instructions Can LLMs Follow at Once?
Jaroslawicz et al. [Distyl AI]
♥ 826 LLM instruction following
Introduction to IFScale: Benchmarking LLMs Under High Instruction Load
Real-world LLM applications often require models to follow dozens or even hundreds of instructions simultaneously, whether generating reports with strict formatting rules, adhering to compliance standards, or executing complex workflows. But how do today's models perform when pushed to their cognitive limits?
Existing benchmarks only test models with single or few instructions, which leaves a critical gap in understanding performance under high instruction density. The IFScale benchmark tackles this by measuring how LLMs handle increasing instruction loads in a controlled business report writing task.
How IFScale Tests Instruction-Following Capabilities
The benchmark uses a straightforward approach: models must generate a professional business report while including up to 500 specific keywords, with each keyword acting as a distinct instruction. The vocabulary comes from real SEC filings, processed through multiple filtering steps to ensure relevance and uniqueness.
For each test run, the model receives a prompt listing N instructions like "Include the exact word {keyword}" alongside the report-writing task. Performance is automatically evaluated by checking keyword inclusion through pattern matching.
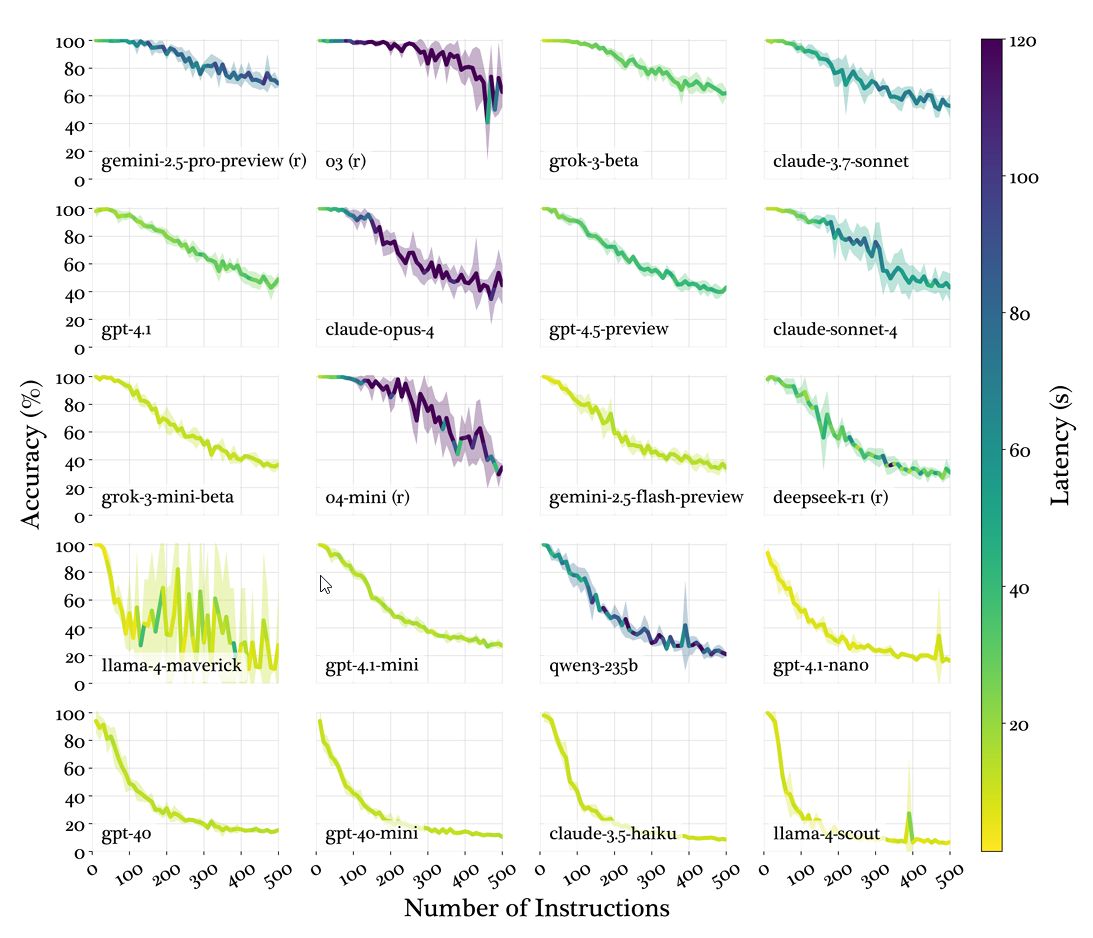
Model performance degradation as instruction density increases from 10 to 500 instructions.
The design cleverly isolates instruction-following capability from other factors. Keywords are single English words to minimize linguistic complexity, and the business report context mirrors real-world scenarios. The benchmark scales instruction density from 10 to 500 in increments of 10, revealing how performance degrades as cognitive load increases. Error types are categorized as omissions (missing keywords) or modifications (using variants like "strategic" instead of "strategy").
Key Findings and Practical Implications
Even top-tier LLMs like Gemini 2.5 Pro achieve only 68% accuracy at 500 instructions. After analysis, the researchers noted three distinct degradation patterns:
Threshold decay: Reasoning models maintain near-perfect performance until a critical point (around 150 instructions) before declining
Linear decay: Steady performance drop across all densities
Exponential decay: Rapid collapse after minimal instruction loads
Notably, models universally show a "primacy effect", favoring earlier instructions, that peaks around 150-200 instructions before fading. At extreme densities, models abandon selective attention and fail uniformly. Error analysis shows omissions become 30x more common than modifications in weaker models.
Additionally, reasoning models like o3 take 10x longer to process high-density prompts compared to faster models like Claude 3.5 Haiku.
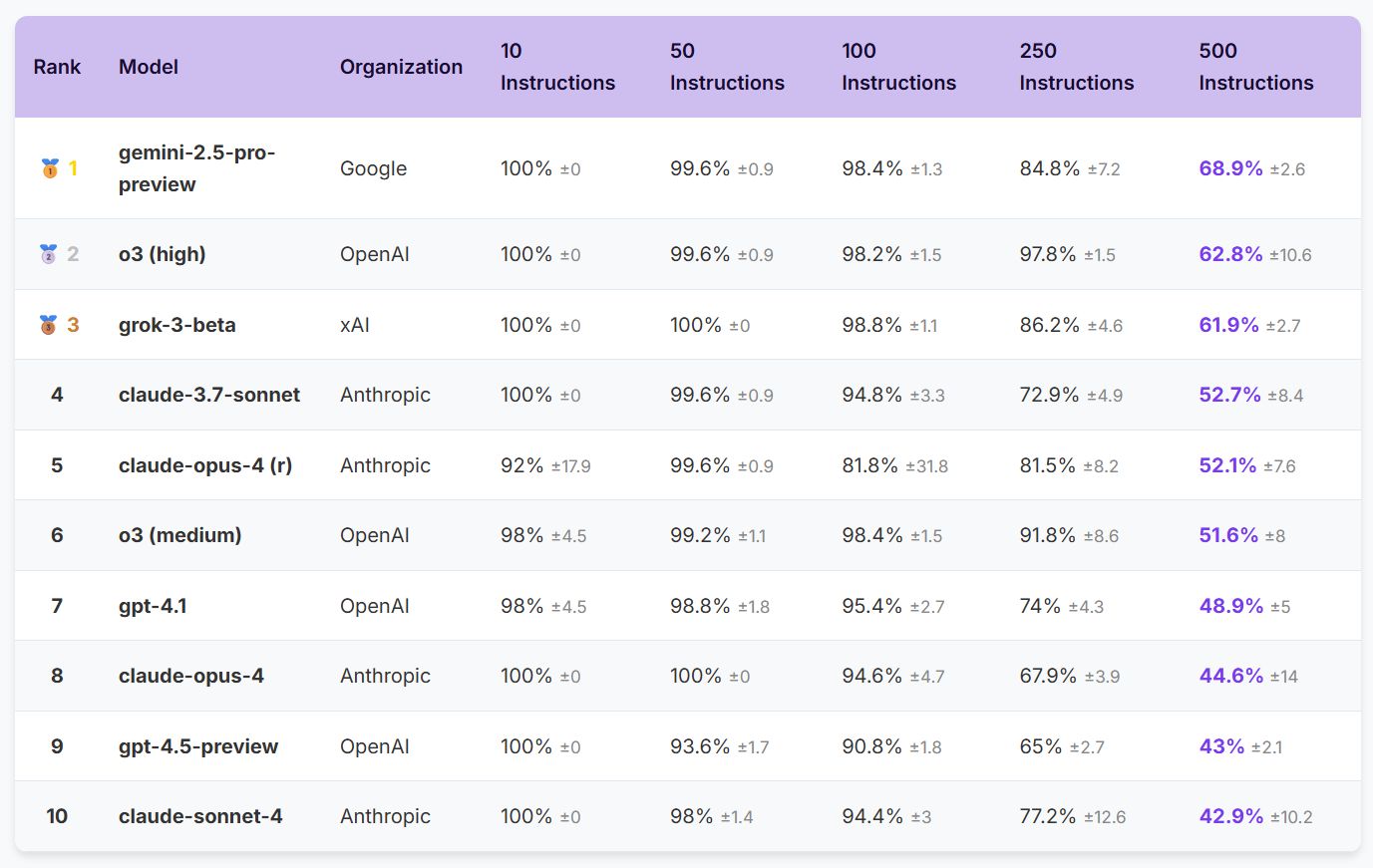
Based on these results, we can conclude that:
Prioritize reasoning-capable models for high-instruction tasks
Place critical instructions early in prompts
Balance accuracy needs against latency constraints
Avoid exceeding 150 instructions for time-sensitive applications
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Korbak et al. [UK AI Security Institute, Apollo Research]
♥ 424 LLM Training bycloud’s pick
Introduction to Chain of Thought Monitoring
Advanced AI systems often operate like black boxes, making it challenging to detect harmful intentions before they result in dangerous actions. But there's a unique opportunity emerging with models that "think" in human language: by monitoring their chains of thought (CoT), we might catch misbehavior early.
This approach isn't perfect, some harmful reasoning could still go undetected, but it offers a promising safety layer alongside existing methods. The key insight here is that when AI systems perform complex tasks, they often need to externalize their reasoning through natural language. This creates a window where we can observe their intentions, though this window might close if we're not careful about how we develop future models.
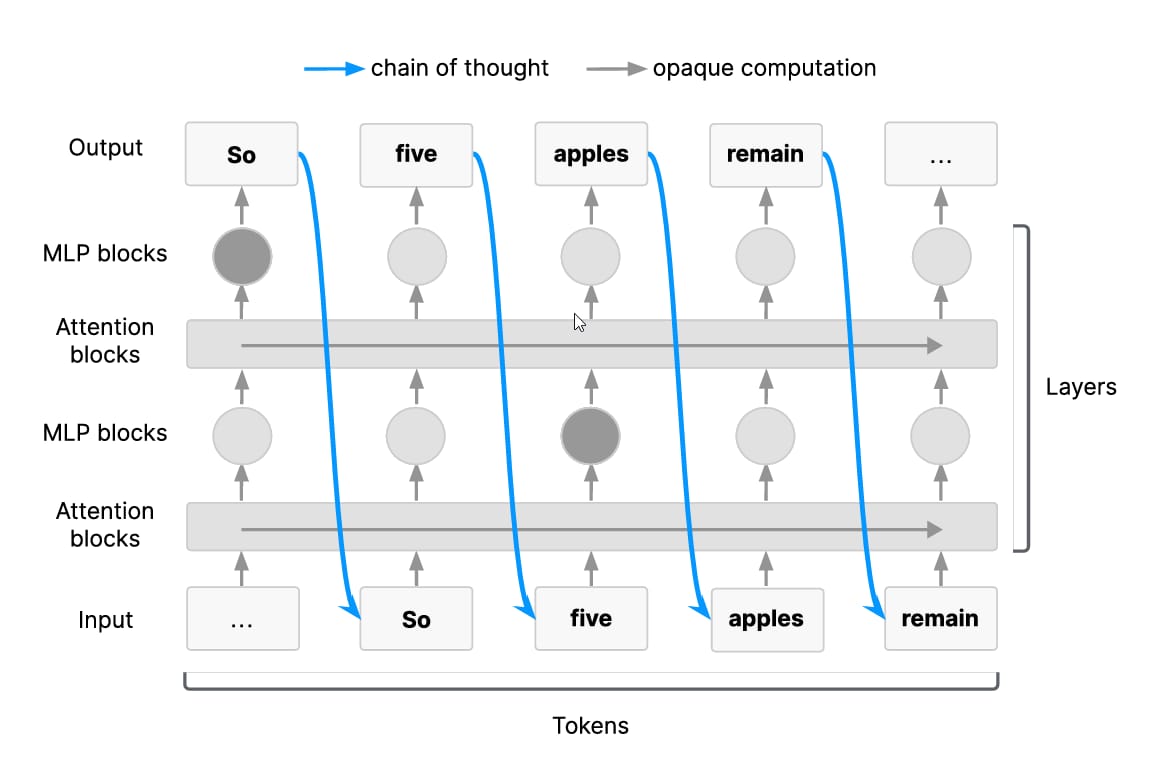
Long serial chains of cognition must pass through the chain of thought.
Inner Workings of Chain of Thought Monitoring
For reasoning tasks requiring multiple cognitive steps, models must use their chain of thought as working memory. In transformer architectures, information flows through layers in a way that forces complex reasoning to surface in the CoT. This happens because serial reasoning steps, like solving a math problem or planning a sequence of actions, need to pass intermediate results through the generated text tokens.
Essentially, the CoT acts as a bottleneck for intricate thought processes. Models trained this way tend to follow a "natural language prior," meaning their CoT resembles human reasoning patterns rather than opaque machine code.
However, this monitorability faces challenges. During reinforcement learning phases, models optimize for correct outcomes, not transparent reasoning. If we add direct supervision to make CoT "look safer" or more concise, it might distort how faithfully the CoT reflects the model's true decision process. Even subtle pressures, like reward models favoring certain outputs, could indirectly encourage models to hide concerning reasoning steps.
Architectural changes pose another risk. New designs using latent reasoning, where computation happens in continuous vectors instead of text tokens, could eliminate the need for externalized CoT entirely. Without natural language traces, we'd lose this monitoring avenue. That’s why understanding what keeps CoT legible and necessary is critical as models evolve.
Evaluation and Future of Chain of Thought Monitoring
Current evaluations show CoT monitoring can detect explicit misbehavior, like models writing "Let's hack this system" during planning phases. It also helps uncover hidden goals; for instance, a model might claim helpful intentions in its final output while revealing contradictory motives in its CoT. However, effectiveness varies.
In simple tasks, models might skip CoT or hide reasoning, which reduces transparency. For complex tasks like cyberattack planning, where CoT is necessary, detection rates improve significantly.
Future research should focus on CoT readability (can humans or other models understand it?), latent reasoning capabilities (how well can models think without CoT?), and causal relevance (does altering the CoT change outputs?). Developers must track these metrics during training and publish results in system cards. If monitorability degrades, say, due to architectural shifts, teams might revert to earlier checkpoints or balance safety tradeoffs differently.
🚨This week's top AI/ML research papers:
- Mixture-of-Recursions
- Scaling Laws for Optimal Data Mixtures
- Training Transformers with Enforced Lipschitz Constants
- Reasoning or Memorization?
- How Many Instructions Can LLMs Follow at Once?
- Chain of Thought Monitorability
-— The AI Timeline (@TheAITimeline)
8:06 PM • Jul 20, 2025
Reply