- The AI Timeline
- Posts
- Neural Computer: Running an OS within an AI?!
Neural Computer: Running an OS within an AI?!
plus more about In-Place TTT, TriAttention, and Interleaved Head Attention.
by cloud
April 14, 2026
Apr 7th ~ Apr 14th
#103 Latest AI Research Explained Simply
🗞️ Industry News in 1 Line
♥ 5.5k Following its initial debut last month, MiniMax has now made the weights for MiniMax M2.7 openly available to the public under a restrictive license that limits commercial use and derivative works. The model shows SoTA performance in software engineering and command-line tasks, achieving a 56.22% on SWE-Pro and 57.0% on Terminal Bench 2. You can try it today on Hugging Face.
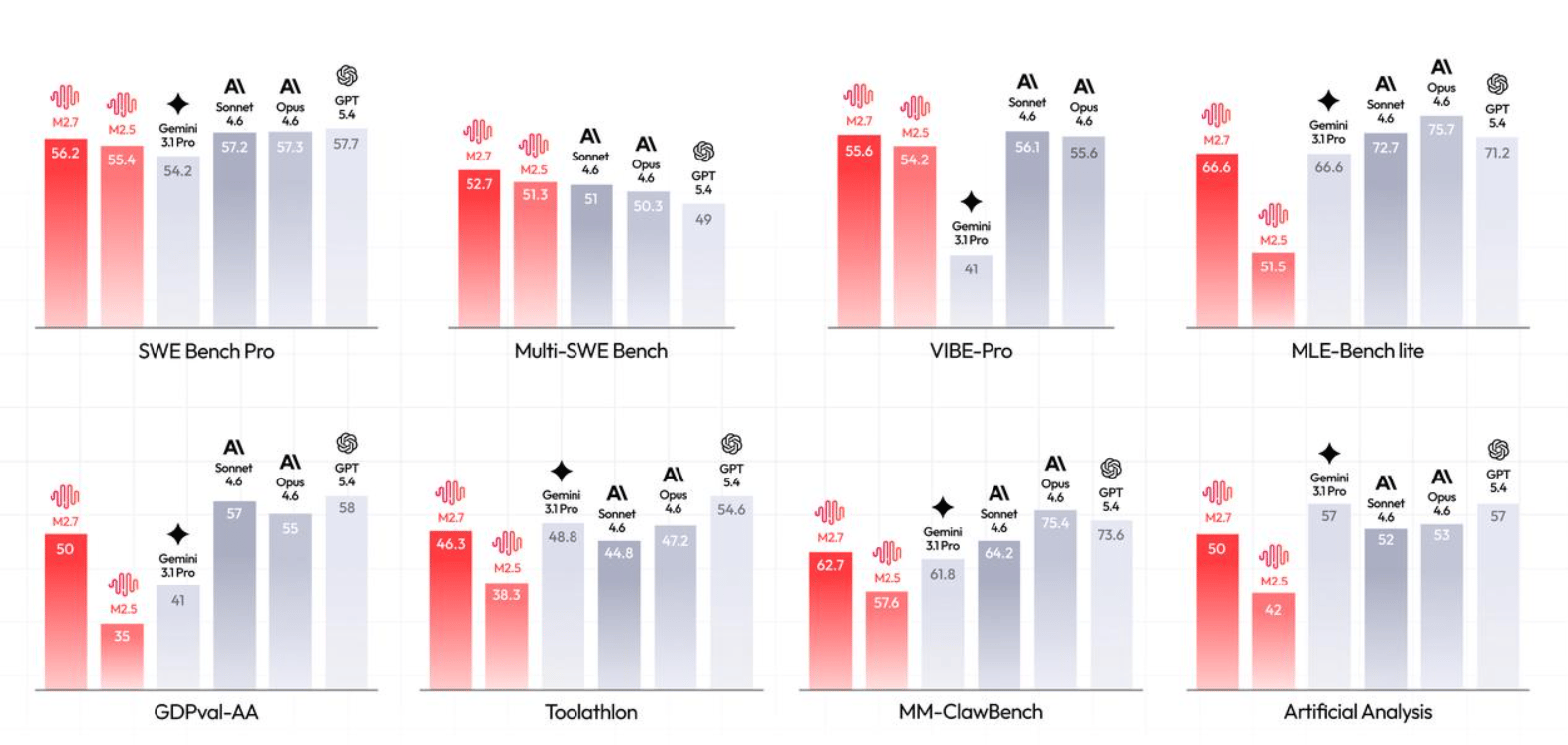
♥ 10k Meta Superintelligence Lab (MSL) recently released their first ever model Muse Spark, a natively multimodal reasoning model that features a "contemplating mode" for complex, parallel agent orchestration. The model serves as the backbone for Meta AI's new deep reasoning and shopping capabilities, demonstrating performance competitive with other leading frontier models like GPT Pro and Gemini Deep Think. You can try it on Meta AI Platform for free.
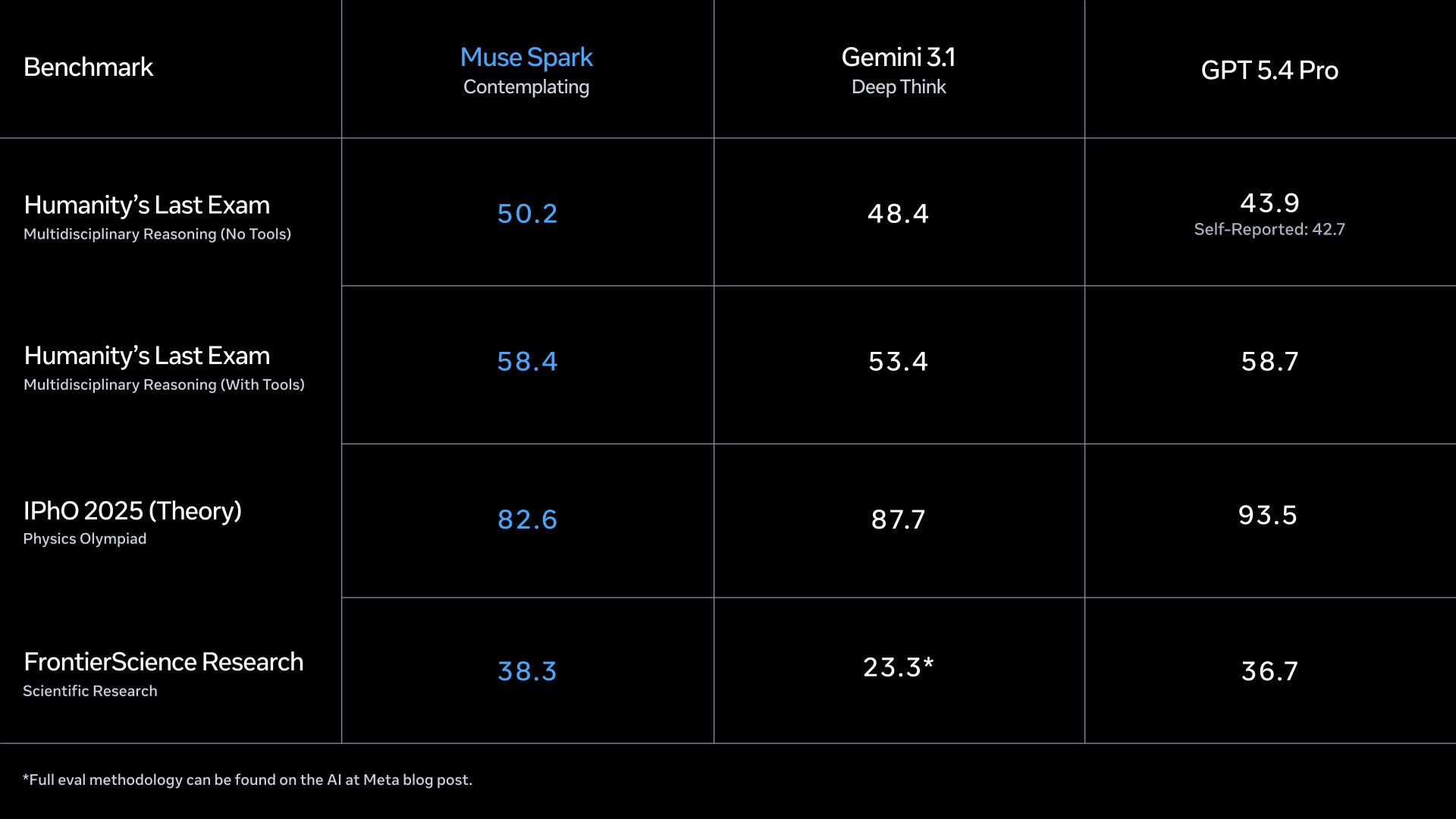
♥ 10k Z.ai has launched GLM-5.1, an open-source model that currently leads the open-weight rankings with a state-of-the-art 58.4 score on SWE-Bench Pro. The model is specifically optimized for long-horizon agentic tasks, capable of running autonomously for up to eight hours to solve complex engineering and database optimization problems. You can try it on Hugging Face or via the API.
Thunder Compute: The cheapest cloud GPU

H100 @ $1.38/GPU/hr!!!
Thunder Compute has one of the cheapest cloud GPUs for developers. They offer on-demand GPU cloud instances in enterprise-grade data centers for a fraction of the price of competitors.
With on-demand H100 sitting at $1.38/GPU/hr, you’d get best-in-class reliability and networking, compared to other competitors that offer at least $4/GPU/hr.

They have additional features like:
VSCode extension and CLI which let you connect to instances without SSH config.
Snapshots to save instance state and restore on any number of instances
Templates for ComfyUI, Ollama, Unsloth Studio, and more
$20 of free credit for students
In-Place Test-Time Training
Feng et al. [ByteDance Seed, Peking University]
♥ 1k Test time training
Current LLMs follow a strict “train then deploy” rule, meaning once they are released, their underlying knowledge is completely frozen. They cannot adjust their internal wiring to absorb continuous streams of new information in real time.
While scientists have tried a workaround called Test-Time Training (allowing a tiny fraction of the model to update on the fly) it historically required changing the system's architecture and undertaking a massive, costly retraining process.
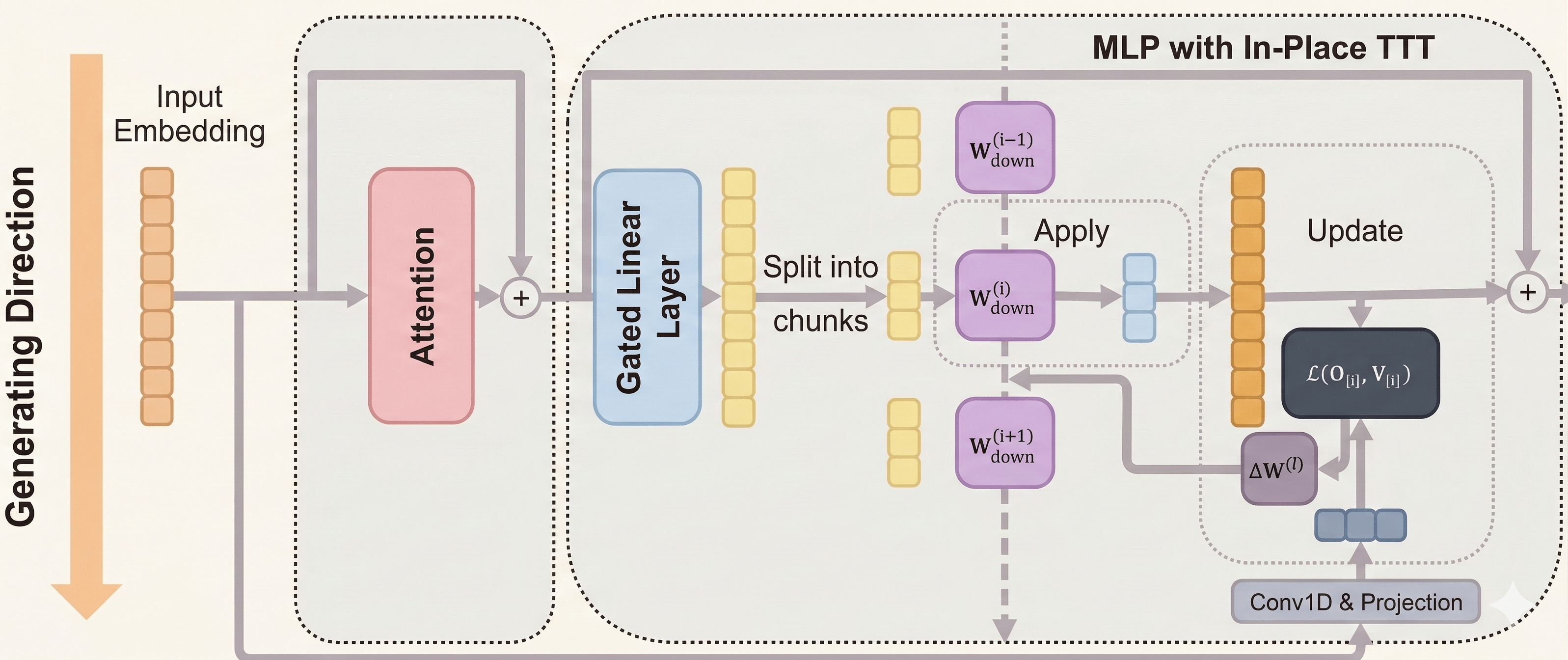
To overcome this, researchers designed a brilliant upgrade called In-Place Test-Time Training. Instead of bolting on brand-new components to the system, they realized they could simply repurpose existing ones. They targeted ubiquitous processing centers inside the model, known as MLP blocks, which normally store the static knowledge acquired during initial training.

Efficiency analysis of In-Place TTT.
The team unlocked the final layer of these blocks to act as a flexible, fast-updating memory. Because this elegant drop-in design leaves the original architecture perfectly intact, it preserves the system's foundational knowledge while seamlessly granting it the ability to adapt as it processes new data.
The team paired this structural cleverness with an efficient engine that updates the memory in scalable chunks, avoiding heavy computing bottlenecks. Additionally, they aligned this real-time learning with the system's natural goal of predicting the next word.
TriAttention: Efficient Long Reasoning with Trigonometric KV Compression
Mao et al. [MIT, NVIDIA, ZJU]
♥ 1.1K Attention bycloud’s pick
Modern LLMs generate incredibly long chains of thought to solve logic puzzles, but this creates a massive memory bottleneck. Every thought the model holds onto is stored in a cache, and as reasoning grows, this memory gets completely overwhelmed. Until now, the best solution was deleting older memories based on recent observations. However, just like someone forgetting the beginning of a math problem midway through, this causes the system to lose critical context.

Q/K concentration and its implications for attention.
To solve this, researchers looked deeper into the architecture of the model, the raw space before the system applies rotational math to track word positions. Here, they noticed a beautifully consistent pattern. The specific components the model uses to match questions with answers naturally cluster around stable centers, regardless of the actual text.

Performance comparison on Qwen3-8B.
Because these centers never wander, researchers realized they could predict exactly which memories the model would need in the future based purely on distance. By using a mathematical curve known as a trigonometric series, they mapped out the natural distance preferences of the model to perfectly score memory importance.

Performance trade-offs on AIME25 (Qwen3-8B)
Building on this insight, the team designed a system named TriAttention. Instead of guessing which past thoughts matter based on recent windows, it calculates the true future importance of every piece of data.
Researchers demonstrated that their method perfectly matches the reasoning accuracy of an uncompressed model, yet it slashes memory usage by nearly eleven times and runs two and a half times faster. This shortcut frees up enough memory that advanced AI can now run smoothly on a single consumer graphics card.
Neural Computers
Zhuge et al. [Meta AI, KAUST]
♥ 1.2K LLM Computer Use
Think about how computers operate today: the hardware, the operating system, the applications, and the AI tools navigating them are all completely separate pieces. Researchers are trying to solve this fundamental fragmentation by asking a bold question: what if a single AI model could actually be the entire computer?
Currently, traditional computers execute explicit programs, AI agents click around those programs from the outside, and predictive models guess what a screen should look like next. To bridge this gap, scientists are building Neural Computers.
Instead of relying on a rigid, traditional stack of physical processors, memory banks, and standard code, this approach combines computation, working memory, and user inputs into one continuously learning neural network.
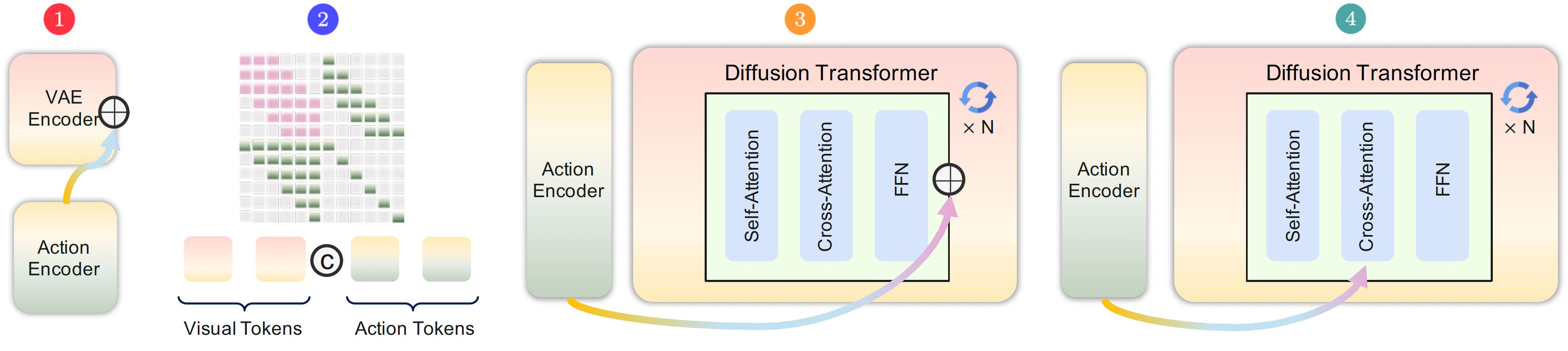
To test this ambitious idea, the team built early prototypes using advanced video generation technology, observing how the AI handled both text-heavy command-line terminals and traditional visual desktops. By feeding the system streams of user actions, text prompts, and starting screen visuals, the network's internal state essentially became the computer’s processor and RAM.
The researchers discovered that these neural systems can intuitively learn the physical rules of our digital worlds from observation alone. The models successfully rendered fast-scrolling text, aligned precise cursor movements, and perfectly simulated short-term desktop responses like hovering over menus or clicking buttons.
While they still require careful instruction to solve complex math or maintain focus over long periods, this fascinating discovery proves the foundational building blocks of a completely neural computer are already within our reach.

Interleaved Head Attention
Duvvuri et al. [Meta, UT Austin, UC Berkeley, Harvard University, MIT]
♥ 487 LLM Attention
When modern artificial intelligence reads a prompt, it relies on independent processors called "attention heads." Think of these heads as a team of isolated researchers, where each person analyzes a document in a sealed room without speaking to their colleagues. While this works for simple facts, researchers realized it creates a massive bottleneck for multi-step reasoning.
If you ask an AI where the author of a specific book was born, the system must first identify the author, then find their birthplace. Because these processors cannot communicate during their computation, standard models are forced to rely on an inefficient, ever-growing number of isolated heads to piece together these chains of logic.
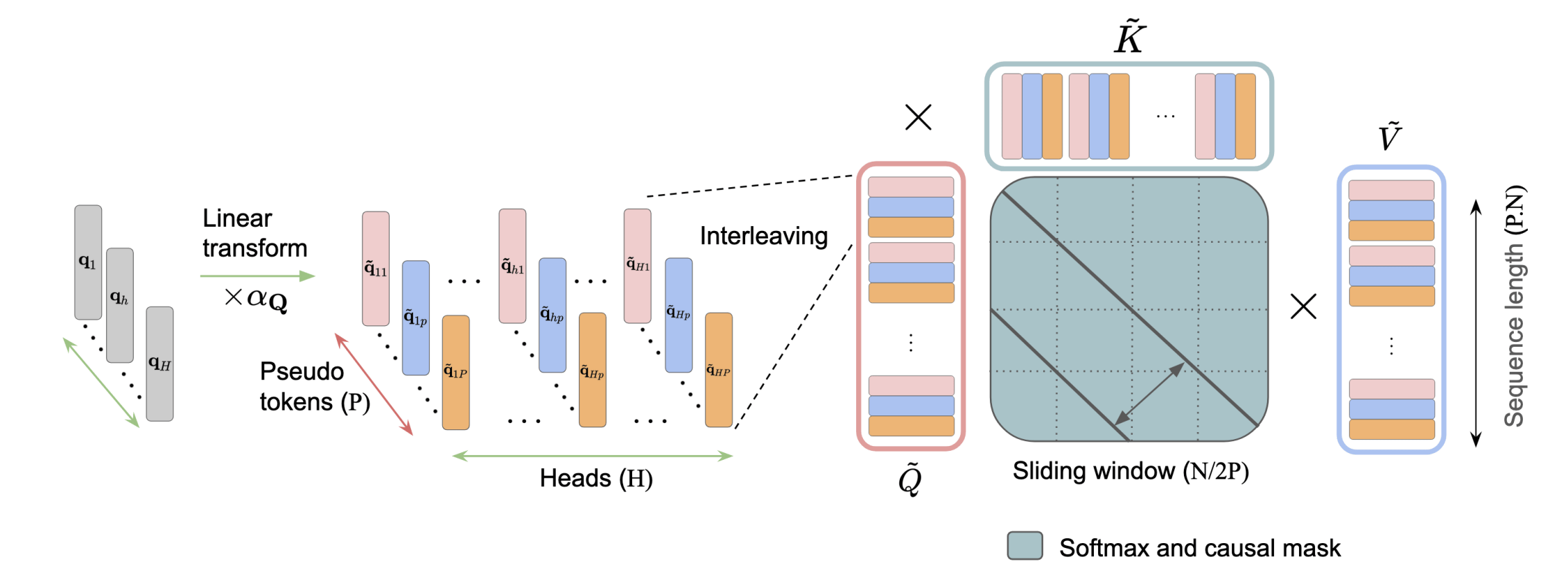
Overview of Interleaved Head Attention (IHA).
To solve this, researchers developed a brilliant new approach called Interleaved Head Attention. Instead of forcing processors to work in isolation, the system constructs "pseudo-heads" that actively blend information from the entire team before analyzing the text. By mixing their perspectives together, these virtual processors can suddenly share context.
Rather than learning just one pattern per head, this collaborative mixing allows a single processor to recognize multiple complex patterns simultaneously. It literally multiplies the model's ability to connect the dots while capturing complex, overlapping relationships.

RULER long-context results after 64k fine-tuning.
The researchers proved that this technique requires vastly less underlying code to achieve the same reasoning power as older models. When put to the test, this cross-mixing improved the system's ability to retrieve multiple facts hidden in extremely long documents by up to twenty percent.
Furthermore, when fine-tuned for complex logic, it boosted accuracy on advanced math problem-solving benchmarks by nearly six percent.
Reply