- The AI Timeline
- Posts
- New Generative Paradigm: Drifting Model
Feb 3rd ~ Feb 9th
#94 Latest AI Research Explained Simply
🗞️ Industry News in 1 Line
♥ 72k ByteDance has released Seedance 2.0 in China, a powerful new AI tool that empowers creators to generate stunningly realistic, high-resolution videos from simple prompts. It is so advanced and its output so lifelike that it is already being hailed as a game-changing force which can revolutionize the filmmaking and visual effects industries.
♥ 10k OpenAI has launched GPT-5.3-Codex, which has the ability to handle long-running, complex tasks that involve research and tool use, effectively acting as an interactive collaborator. It is 25% faster and has set new industry standards in performance (real-world software engineering to building complex games and apps from scratch).

♥ 39k Anthropic has launched Claude Opus 4.6, its latest model for agentic coding, reasoning, and complex knowledge work. It now supports brand-consistent slide creation in PowerPoint, sophisticated multi-step planning in Excel, and autonomous "agent teams" for parallelized coding. Claude Opus 4.6 provides creators with an incredibly smart and efficient partner for handling long-running, high-stakes projects.

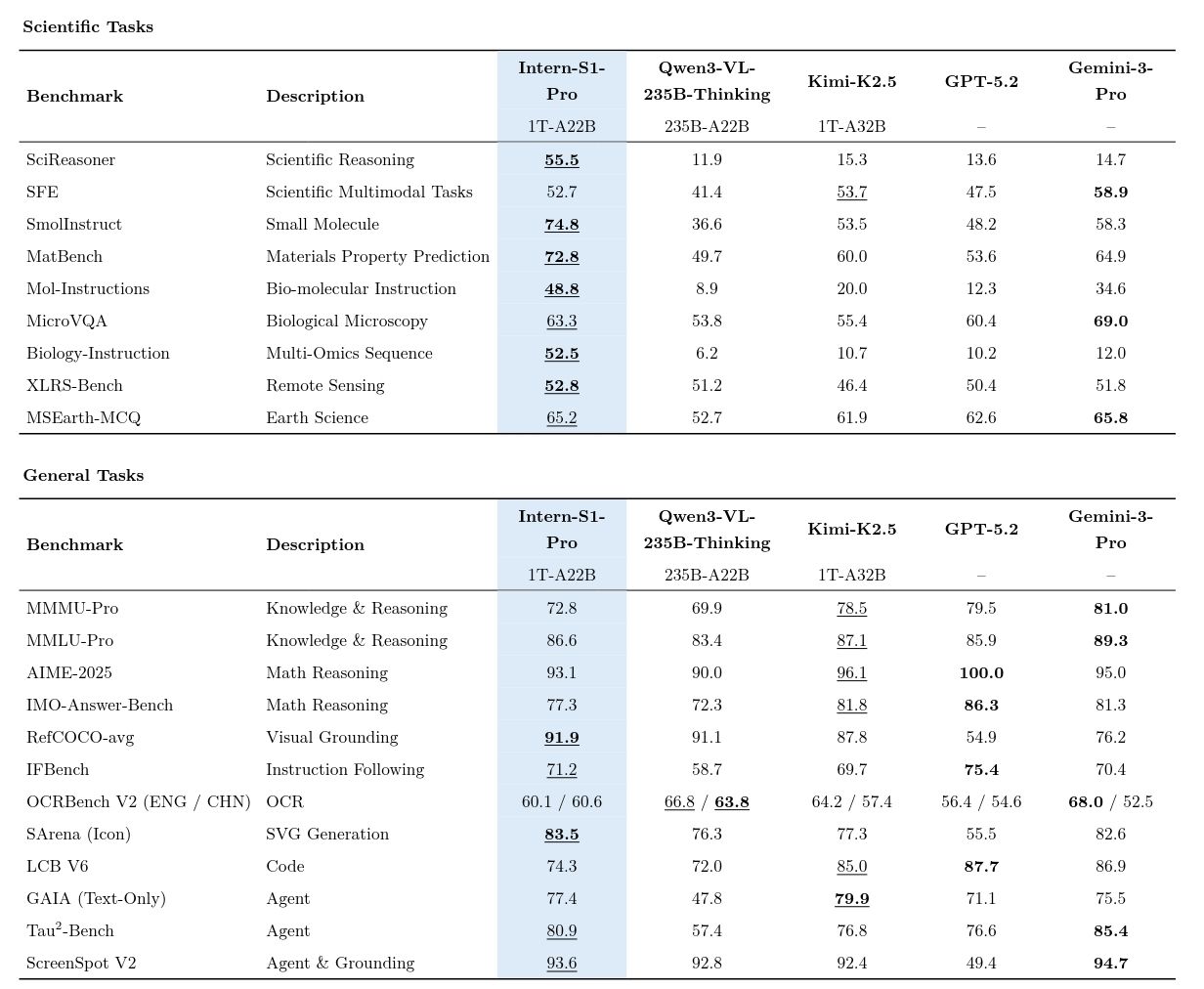
♥ 961 Intern-S1-Pro has launched as a 1T open-source model that delivers state-of-the-art scientific reasoning, rivaling the world's leading closed-source models in complex AI4Science tasks. It uses Fourier Position Encoding for superior time-series modeling and integrates with vLLM, this powerful tool provides researchers with an incredibly efficient and accessible way to master complex physical signals and advanced multimodal data. Get weights on Hugging Face or try via API.
Learn LLMs Intuitively - Intuitive AI Academy
Want to learn about LLMs, but never have a good place to start?
My latest project: Intuitive AI Academy has the perfect starting point for you! We focus on building your intuition to understand LLMs, from transformer components, to post-training logic. All in one place.

content overview (a total of 100k words explainer so far!)
We currently have a New Year New Me launch offer, where you would get 50% off yearly plan FOREVER for our early users. Only a few left & the deal will not be back!
Use code: 2026
Generative Modeling via Drifting
Deng wt al. [MIT, Harvard University]
♥ 1.1k LLMs
Generative modeling is about teaching a computer to map simple random noise into complex, meaningful data, like a realistic image. Until now, leading approaches work by taking a noisy sample and refining it step-by-step until it becomes clear. This multi-step requirement makes the actual generation process computationally heavy and time-consuming. The researchers wanted to know whether it is possible to condense this complex evolution into a single, instant step without sacrificing quality.

Illustration of drifting a sample.
The researchers introduced a new approach called "Drifting Models," which reimagines how a neural network learns to create data. Instead of forcing the model to refine an image iteratively every time it runs, this approach allows the network to act as a single-pass generator.

The biggest change is the introduction of a "drifting field" that operates during the training process. This field governs how the distribution of generated samples moves, or "drifts," toward the target data distribution as the network optimizes. The system is designed to seek equilibrium: when the generated samples match the real data, the drift becomes zero, and the model stabilizes.

Evolution of samples.
This method effectively moves the iterative evolution out of the inference stage and into the learning stage. Once the model is trained, it can generate high-fidelity content in just one step. The results are highly encouraging, with the method achieving state-of-the-art performance on ImageNet benchmarks.

System-level comparison: ImageNet 256×256 generation in pixel space
Learning to Reason in 13 Parameters
Morris et al. [FAIR at Meta, Cornell University, Carnegie Mellon University]
♥ 2K Reasoning bycloud’s pick
Researchers are teaching models to "reason" and thoughtfully work through math and logic problems rather than just predicting the next word. Fine-tuning a massive model to improve these cognitive skills has been a heavy computational lift, which requires engineers to adjust millions, if not billions, of internal connections.
It is a common belief that learning a complex new behavior requires a substantial overhaul of the model’s weights, which makes personalization expensive and difficult to scale. However, this paper suggests that when it comes to reasoning, a model might not need to learn nearly as much new information as previously thought; perhaps it just needs a very precise, microscopic nudge in the right direction.

Using Qwen2.5-7B-Instruct as a base model, our TinyLoRA achieves performance within 5% of full finetuning on GSM8K with only 13 parameters. Dashed lines indicate untrained and full-FT baselines.
This paper introduced a method called TinyLoRA, which showed that large language models can learn to reason effectively by updating as few as thirteen parameters (a change so small it occupies merely 26 bytes of computer memory).
By using reinforcement learning, they were able to train a massive model to achieve over 90% accuracy on complex math problems, effectively matching the performance of traditional methods that update thousands of times more data. The researchers found that this extreme efficiency works because reinforcement learning acts as a highly effective filter.

TinyLoRA performance during training on MATH.
Standard training methods train the model with "noisy" data that it tries to memorize, but reinforcement learning provides a clean, sparse signal (simply telling the model if its logic was right or wrong). This clarity allows the model to ignore irrelevant details and isolate the specific neural pathways needed for reasoning.
Maximum Likelihood Reinforcement Learning
Tajwar et al. [Carnegie Mellon University, Tsinghua University, Zhejiang University, UC Berkeley, Impossible Inc.]
♥ 714 LLM RL
Researchers use RL to teach AI models how to solve tasks with clear right-or-wrong outcomes, such as writing code or solving complex math proofs. The authors of this paper suggest that this strategy is actually just a rough, first-order approximation of a far more powerful mathematical goal: maximum likelihood.

The problem has always been that targeting maximum likelihood directly in these complex, open-ended scenarios was considered computationally intractable. The research team set out to fix this misalignment, asking if there was a principled way to trade more computing power for a better, more mathematically rigorous learning objective without hitting a computational wall.
The researchers introduced a framework called MaxRL, which elegantly bridges the gap between standard reinforcement learning and the ideal maximum likelihood objective. They demonstrated that the learning signal can be viewed as a mathematical series where standard methods only optimize the very first term. MaxRL unlocks a "compute-indexed" family of objectives. By generating more sample attempts (or "rollouts") during training, the algorithm incorporates higher-order terms from this series, creating a progressively more accurate approximation of the ideal objective.

Results on Qwen3-4B. MaxRL Pareto-dominates GRPO across all benchmarks, achieving similar or better Pass@1 while significantly improving Pass@K. This translates to 7.9×–19.2× gains at test-time scaling efficiency.
This approach effectively transforms extra computing time into a smarter learning signal. The study reveals that MaxRL focuses the model’s attention on harder, lower-probability successes rather than just reinforcing easy wins.

Example maze: successful navigation (left) vs. failure case (right).
Additionally, the method consistently outperforms existing techniques in mathematical reasoning and navigation tasks. The researchers found that their approach prevents the model from "overfitting," or losing its creativity, as training progresses.
Kimi K2.5: Visual Agentic Intelligence
Kimi team at Moonshot AI
♥ 16K Visual LLM
There is a difference between how models process language and how they understand images, combined with their inability to handle massive, multi-step tasks efficiently. Until now, visual capabilities were often bolted onto text models like an afterthought, and "agents" worked linearly. The team behind Kimi K2.5 created a model where vision and language are treated as equal partners from day one, while simultaneously reinventing how AI manages complex workflows.

Vision RL training curves on vision benchmarks starting from minimal zero-vision SFT.
It has two clever architectural innovations. First, rather than teaching the model to read and then teaching it to see, researchers integrated visual data and text together at the very beginning of the training process. This "early fusion" created a surprising synergy: learning to interpret images actually made the model better at text-based reasoning, and text training helped it understand visuals without needing specific image examples. It turns out that a balanced diet of inputs helps the AI generalize better across the board, creating a shared understanding where vision refines text and text bootstraps vision.

An agent swarm has a trainable orchestrator that dynamically creates specialized frozen subagents and decomposes complex tasks into parallelizable subtasks for efficient distributed execution.
Secondly, the researchers introduced a framework called "Agent Swarm." Instead of a single AI struggling through a long to-do list, Kimi K2.5 acts as an orchestrator. It looks at a complex problem, breaks it down into smaller pieces, and assigns them to specialized sub-agents that work in parallel.

Overview of training stages: data composition, token volumes, sequence lengths, and trainable components.
By treating the AI as a manager of a digital swarm rather than a solo worker, the system can handle heavy workloads in coding and research that would typically overwhelm a standard model.

Performance and token efficiency of some reasoning models. Average output token counts (in thousands) are shown in parentheses.
Reply