- The AI Timeline
- Posts
- Pre-training under infinite compute
Pre-training under infinite compute
Plus more about Discovery of Unstable Singularities and AToken: A Unified Tokenizer for Vision
by cloud
September 23, 2025
Sep 15th ~ Sep 22nd
#73 Latest AI Research Explained Simply
🗞️ Industry News in 1 Line
♥ 6.5K xAI has launched Grok 4 Fast, which is its latest multimodal reasoning model, setting a new standard for cost-efficient intelligence with a massive 2 million token context window. The model is now available for free to all users on Grok's web and mobile apps. Grok 4 Fast is also accessible via the xAI API and is being offered for free for a limited time on platforms like OpenRouter.

Cost comparison of Grok 4 Fast
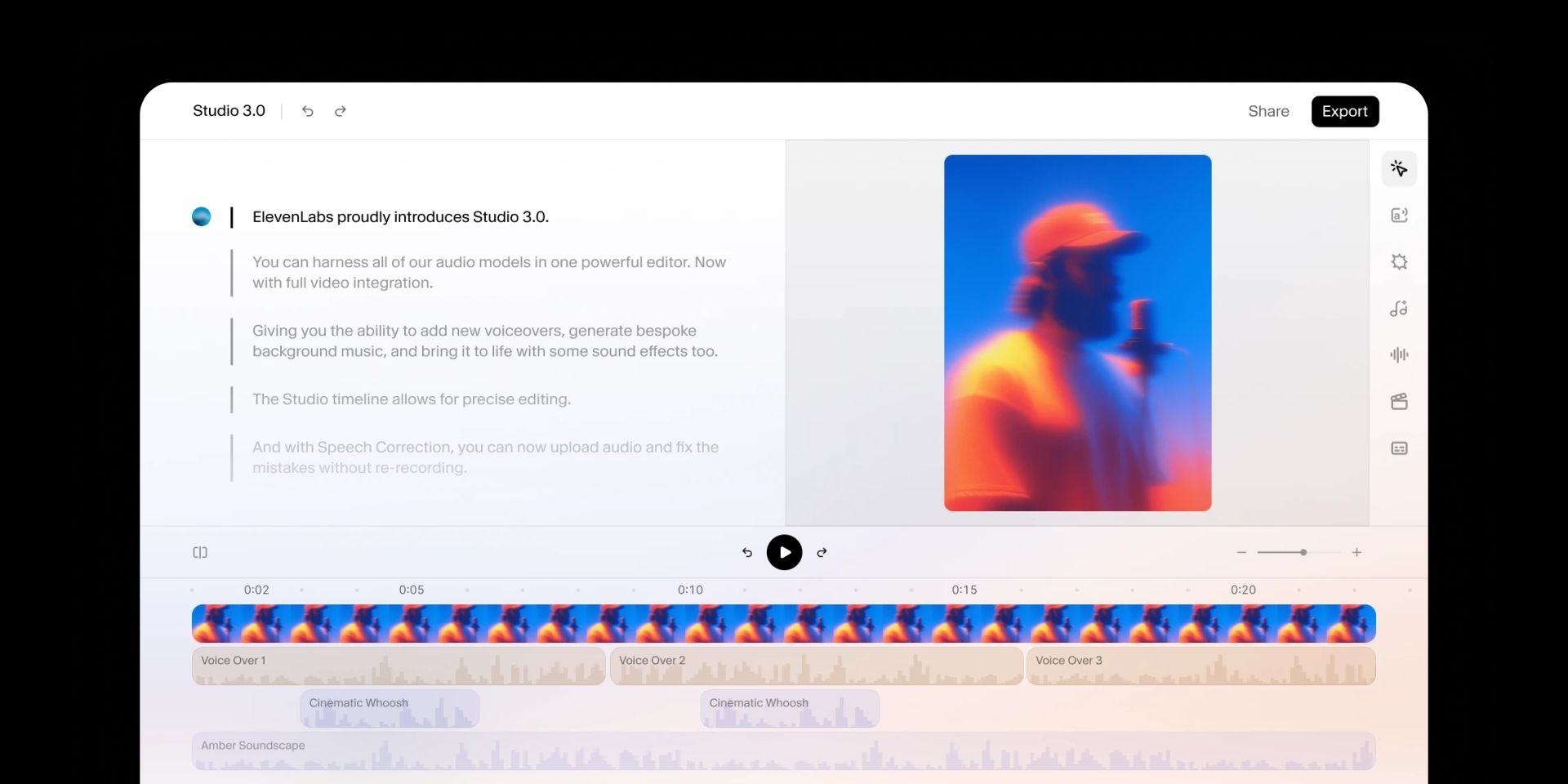
♥ 1.5k ElevenLabs has launched Studio 3.0, which is its latest AI audio and video editor designed for creators. It integrates text-to-speech with over 10,000 voices, an AI music generator, sound effects, and voice cloning capabilities into a single timeline editor. It also allows creators to enhance video content, clean up noisy audio with a "Voice Isolator," and instantly correct speech by simply editing the text. You can try Studio 3.0 for free right now.
♥ 1.1k Luma AI has released Ray3, a new AI video model designed for professional-grade storytelling and visual reasoning. It can generate videos in 16-bit High Dynamic Range (HDR) color, which makes it suitable for studio production pipelines. Ray3 also introduces a "Draft Mode," allowing creators to iterate on ideas up to five times faster before mastering final shots into high-fidelity 4K footage.
♥ 134 Good news for the merely rich: it turns out you don't need a billionaire's war chest to train a state-of-the-art AI model anymore. A new report from DeepSeek reveals they trained their massive 660B parameter model in just about four days using a cluster of 64*8 H800 GPUs. So if you have ~$250,000 to spare on computing, then you can also build foundational models from scratch.
Pre-training under infinite compute
Kim et al. [ Stanford University]
♥ 218 LLM Pre-training
Introduction to Data-Efficient Pre-training
Computational power is growing exponentially, but high-quality web text is limited. Does this make it difficult to train better language models when data is scarce but computing is abundant?
This paper introduces a set of practical techniques to overcome these limits. It shows that with careful tuning and clever scaling strategies, we can train models that are significantly more data-efficient without requiring more data.

How Does Data-Efficient Pre-training Work?
The standard pre-training recipes use regularization techniques, like weight decay, that are too weak for data-constrained settings. The authors of this paper found that the optimal weight decay can be up to 30 times larger than commonly used values.
By properly tuning regularization, learning rate, and epoch count, they enabled models to scale predictably: loss decreases smoothly as model size increases. This "regularized recipe" allows training models with parameter counts far beyond what was previously feasible without overfitting.

Evaluating standard recipe of epoching and parameter scaling for 200M tokens.
However, scaling up a single model isn't the only option. The researchers also explored ensembling, i.e., training multiple smaller models independently and combining their predictions. Interestingly, ensembling achieves a lower loss asymptote than simply making a single model larger.
The paper goes further by combining both approaches: scaling up the size of each ensemble member while also increasing the number of members. This "joint scaling recipe" leverages infinite compute in two dimensions simultaneously.

Comparing scaling parameter count vs scaling ensemble member count.
Evaluation and Future Implications
The proposed methods achieve remarkable improvements in data efficiency. On a 200M token budget, the joint scaling recipe performs as well as a standard recipe would with 5.17 times more data. These gains persist across larger token counts, and distillation allows recovering 83% of the ensemble benefit with an 8x smaller model. Downstream benchmarks confirm that lower pre-training loss translates to better performance on tasks like PIQA, SciQ, and ARC Easy, with improvements up to 9% over baselines.

Performance of pre-trained models on downstream tasks.
In continued pre-training experiments, these techniques enabled a model trained on just 4B tokens to outperform a baseline trained on 73B tokens, which is a 17.5x data efficiency improvement.
Discovery of Unstable Singularities
Wang et al. [New York University, Stanford University, Google DeepMind, Ecole Polytechnique Federale de Lausanne, Brown University]
♥ 4.2k Fluid Dynamics
Introduction to Unstable Singularities in Fluids
The question of whether fluids can develop infinitely sharp features from smooth initial conditions has puzzled mathematicians for centuries. This phenomenon, known as singularity formation, occurs when solutions to fundamental equations like the 3D Euler equations blow up in finite time.
While some singularities are stable (they form reliably even with small changes to the initial setup), many important open problems, including the famous Navier-Stokes Millennium Prize problem, are thought to involve unstable singularities. These are much harder to find: they require infinitely precise initial conditions, and even a tiny perturbation can steer the solution away from blowing up.

In this paper, researchers present the first systematic discovery of new families of unstable singularities. They use a computational approach that blends tailored machine learning with high-precision optimization. The study uncovers multiple unstable self-similar solutions for key fluid equations.
How to Find Unstable Singularities in Fluids
To find these unstable singularities, the team reformulated the fluid equations using self-similar coordinates, which rescale space and time around the point of blow-up. This turns the dynamic problem of tracking a singularity into a static one: finding a smooth, stationary profile.
After this, they modeled these profiles using physics-informed neural networks (PINNs), but with important enhancements. Instead of treating PINNs as general-purpose equation solvers, the researchers carefully embedded known mathematical properties (like symmetries, boundary conditions, and expected behavior near the origin) directly into the network architecture. This provided strong inductive biases that guided the search toward physically meaningful solutions.
Additionally, it used a high-precision Gauss-Newton optimizer, which leverages second-order curvature information for more accurate and stable convergence. This was combined with a multi-stage training process, where a second network corrects errors left by the first; this approach achieved unprecedented accuracy.
For some solutions, residuals reached levels near double-float machine precision, limited only by GPU hardware rounding errors. This precision is necessary because it meets the bar for stringent validation via computer-assisted proofs.

Self-similar singularities to IPM and Boussinesq.
Evaluation and Implications for Fluid Dynamics
The method successfully discovered unstable singularities for three canonical fluid systems: the Córdoba-Córdoba-Fontelos (CCF) model, the incompressible porous media (IPM) equation, and the Boussinesq equations.
For each, the team identified not only stable blow-up profiles but also several unstable ones, with each higher-order unstable solution exhibiting more instability modes. In the case of the CCF equation, the discovery of a second unstable solution suggests that singularities can persist under stronger dissipation than previously thought.
AToken: A Unified Tokenizer for Vision
Lu et al. [Apple]
♥ 424 Tokenization bycloud’s pick
Introduction to ATOKEN: Unified Visual Tokenization
Visual AI has long been stuck in a siloed approach: some models excel at reconstructing pixels but miss the semantics, while others grasp concepts but can’t reproduce visual details. Imagine if we could process images, videos, and 3D objects the same way we handle text, just with a single model that understands both the fine details and the broader meaning.

Illustration of our method on different visual modalities.
In addition, handling different data types such as 2D images, time-based videos, and spatial 3D assets is challenging, which is why there is no standard solution. ATOKEN breaks these barriers by introducing a shared 4D representation that works across modalities and tasks, all within one transformer-based framework.
Inner Workings of ATOKEN
ATOKEN’s biggest innovation is in its 4D latent space, where images, videos, and 3D data are mapped as sparse sets of feature-position pairs. Instead of treating each modality separately, the model uses space-time patch embeddings to convert inputs, such as video frames or multi-view 3D renders, into a consistent format.
A pure transformer encoder then processes these patches, enhanced with 4D rotary position embeddings to handle variations in resolution and duration natively. This design allows the same architecture to work on a still image, a video clip, or a 3D shape without modification.

Overview of AToken Architecture
To ensure stable training without adversarial networks, ATOKEN uses a combination of perceptual loss and Gram matrix loss. The Gram loss, in particular, focuses on capturing textures and styles by comparing feature covariances, which accounts for most of the reconstruction error.
The model is trained progressively: it starts with images, adds video understanding and reconstruction, and then incorporates 3D data. At each stage, the model retains previous capabilities, and surprisingly, multimodal training even improves single-modality performance (image reconstruction gets better as video and 3D are added).

Progressive training curriculum of AToken.
Evaluation and Performance of ATOKEN
On ImageNet, ATOKEN achieves 0.21 rFID for reconstruction and 82.2% accuracy in zero-shot classification, which outperforms earlier unified tokenizers like UniTok. In video, it scores 3.01 rFVD on TokenBench and 40.2% retrieval accuracy on MSRVTT, competitive with specialized video models. For 3D reconstruction on Toys4K, it reaches 28.28 PSNR, close to the dedicated Trellis-SLAT model. The discrete token variant (ATOKEN-So/D) maintains this performance, enabling generative applications across all modalities.

Video understanding performance on multimodal LLMs.
One limitation is that video-text retrieval, while reasonable, lags behind pure understanding models, suggesting room for better pooling strategies or more video-text data.
Reply