- The AI Timeline
- Posts
- Predicting the Order of Upcoming Tokens Improves Language Modeling
Predicting the Order of Upcoming Tokens Improves Language Modeling
Plus more about StepWiser: Stepwise Generative Judges for Wiser Reasoning and Prophesy in LLMs: Diffusion LMs know the answer before decoding
by cloud
September 03, 2025
In partnership with
Aug 25th ~ Sep 2nd
#71 Latest AI Research Explained Simply
🗞️ Industry News in 1 Line
♥ 812 Meituan has launched LongCat-Flash-Chat, which was trained on 20T tokens. It uses 560B parameters and has a clever new ability: a "zero-computational expert" that allows it to ignore simple tokens and dynamically activate only a fraction of its brainpower. This innovative design lets it process information at over 100 tokens per second, so go ahead and try it out yourself.

♥ 633 NVIDIA has released Nemotron-CC-v2, which is a massive dataset that breathes new life into web crawl data by using models like Qwen3 to synthetically generate rephrased text and diverse Q&A, which is then translated into 15 languages. This open-source dataset also features a specialized pipeline that preserves math equations in LaTeX and a huge corpus of curated code, complete with its own synthetically generated Q&A.
♥ 873 Intern-S1 is a new open-source model that combines a huge 235B parameter language model with a vision encoder. It is trained on a massive 5-trillion-token dataset with a heavy focus on scientific material. This specialized training gives it a unique ability to understand complex inputs like molecular formulas and protein sequences directly. You can try Intern-S1 on the web or use it via API.

How 433 Investors Unlocked 400X Return Potential

Institutional investors back startups to unlock outsized returns. Regular investors have to wait. But not anymore. Thanks to regulatory updates, some companies are doing things differently.
Take Revolut. In 2016, 433 regular people invested an average of $2,730. Today? They got a 400X buyout offer from the company, as Revolut’s valuation increased 89,900% in the same timeframe.
Founded by a former Zillow exec, Pacaso’s co-ownership tech reshapes the $1.3T vacation home market. They’ve earned $110M+ in gross profit to date, including 41% YoY growth in 2024 alone. They even reserved the Nasdaq ticker PCSO.
The same institutional investors behind Uber, Venmo, and eBay backed Pacaso. And you can join them. But not for long. Pacaso’s investment opportunity ends September 18.
Paid advertisement for Pacaso’s Regulation A offering. Read the offering circular at invest.pacaso.com. Reserving a ticker symbol is not a guarantee that the company will go public. Listing on the NASDAQ is subject to approvals.
Predicting the Order of Upcoming Tokens Improves Language Modeling
Zuhri et al. [MBZUAI]
♥ 563 LLM Tokenization
Introduction to Token Order Prediction
LLMs are trained to predict the next word in a sequence. This approach has a few limitations; it doesn’t always help models reason about longer contexts or future words. Multi-token prediction (MTP) was introduced to improve this by having models predict several future tokens at once. However, MTP has shown inconsistent results, and it often underperforms on standard language tasks.
This paper introduces Token Order Prediction (TOP), which trains the model to learn the order of upcoming tokens based on their proximity instead of asking it to predict specific future tokens.

An overview of Token Order Prediction (TOP).
Inner Workings of Token Order Prediction
TOP works by training the model to rank tokens based on how soon they appear after the current position in a sequence. For a given input, the model learns to assign higher scores to tokens that appear sooner and lower scores to those that appear later. This is done using a learning-to-rank loss function adapted from information retrieval, which compares the model’s predicted ranking with the actual order of tokens in the training data.
Unlike MTP, which requires adding multiple transformer layers for each future token prediction, TOP only needs one additional linear layer (the TOP head) alongside the standard next-token prediction head. Both heads use the same hidden representations from the transformer, making the approach parameter-efficient and easy to integrate. During training, the model optimizes a combined loss from both the next-token and token-order prediction tasks.

This design allows the model to develop a richer understanding of sequence structure without overcomplicating the learning process. By focusing on relative order rather than exact token identity, TOP encourages the model to form representations that are more aware of context and future dependencies, which in turn improves its ability to predict the next token accurately.
Evaluation and Performance of Token Order Prediction
The researchers tested TOP against both standard NTP and MTP across three model sizes: 340 million, 1.8 billion, and 7 billion parameters. The results showed that TOP consistently outperformed both NTP and MTP across most tasks and improvements were more noticable as model size increased.

General language modeling evaluation results of NTP vs MTP vs TOP on standard NLP benchmarks.
For example, the 7B TOP model achieved higher accuracy on Lambada, HellaSwag, and TriviaQA compared to baselines. It also had better scaling behavior than MTP, which often struggled on non-coding tasks. Interestingly, TOP models had a slightly higher training loss on the next-token prediction task but still generalized better, which suggests that TOP acts as a regularizer that prevents overfitting.
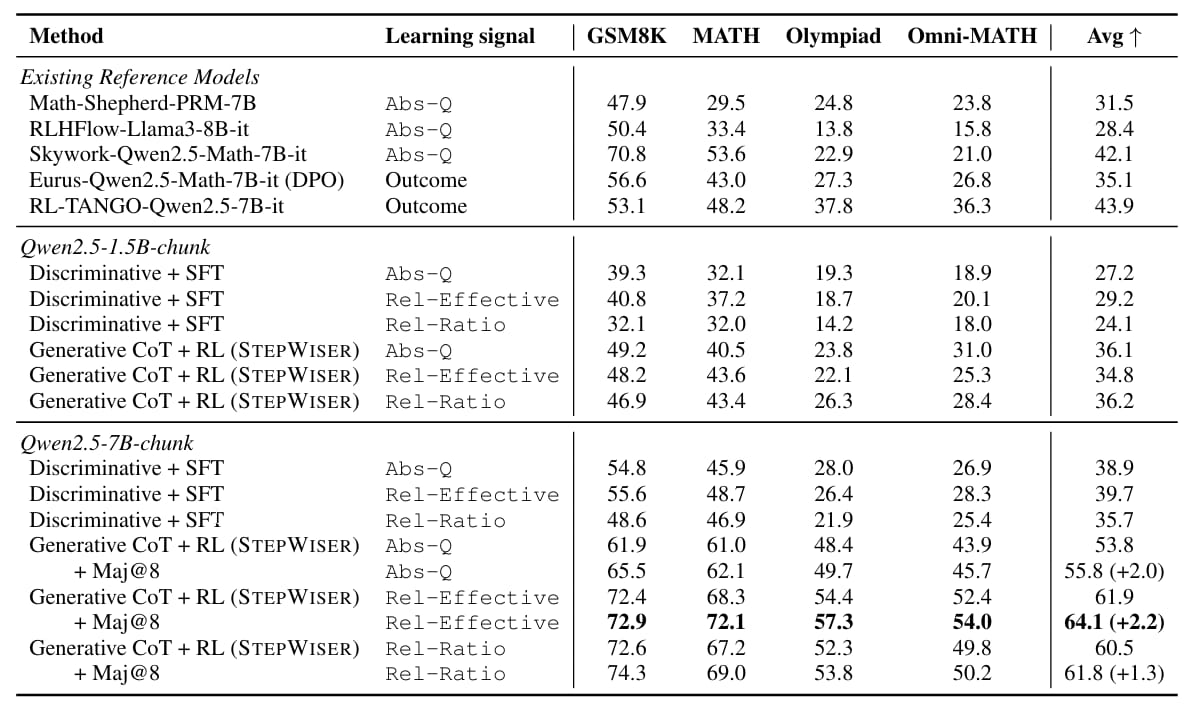
StepWiser: Stepwise Generative Judges for Wiser Reasoning
Xiong et al. [FAIR at Meta, University of Illinois Urbana-Champaign, NYU]
♥ 480 LLM Reasoning
Introduction to Stepwise Generative Judges
As LLMs rely on multi-step reasoning strategies like Chain-of-Thought to tackle complex problems. Supervising these intermediate steps for logical correctness has become a major challenge. Existing process reward models often act as black-box classifiers, and they offer scores without explanations.
This paper has reframed stepwise reward modeling from a classification task to a reasoning task. This led to the development of STEPWISER, which is a generative judge that meta-reasons about reasoning steps before delivering a verdict.

Overview of our STEPWISER training method.
Inner Workings of STEPWISER
STEPWISER has three key components.
First, it uses self-segmentation to break reasoning chains into coherent chunks, called Chunks-of-Thought. This is done by fine-tuning the base model to identify logical segments based on rules like unified purpose and clear transitions, ensuring each chunk represents a complete step in the problem-solving process.
Next, each chunk is annotated with a binary label indicating whether it is helpful or harmful. This is done by estimating Q-values through Monte Carlo rollouts, i.e., generating multiple completions from each step and calculating the average success rate. To better capture progress, methods like relative effective reward thresholding compare success rates before and after a chunk, rewarding improvements rather than just absolute correctness.

Finally, the judge model is trained with reinforcement learning to generate its own reasoning about each chunk before outputting a judgment. It uses a reward based on alignment with the estimated labels and techniques like GRPO for optimization. Prompt balancing is used to ensure stable training by equalizing positive and negative examples.

Evaluation and Impact of STEPWISER
STEPWISER significantly outperforms existing methods on ProcessBench (a benchmark for identifying incorrect reasoning steps). It also excels in practical applications like inference-time search, where it guides models to discard flawed chunks and retry, leading to better final solutions. Moreover, when it is used for training data selection, it helps identify high-quality reasoning traces and improves downstream model performance through fine-tuning.
DIFFUSION LANGUAGE MODELS KNOW THE ANSWER BEFORE DECODING
Li et al. [The Hong Kong Polytechnic University, Dartmouth College, University of Surrey, Sun Yat-sen University, Google DeepMind, Max Planck Institute for Intelligent Systems, ELLIS Institute Tubingen]
♥ 226 LLM Diffusion bycloud’s pick
Introduction to Early Answer Convergence in Diffusion Language Models
Diffusion language models are gaining attention as a flexible alternative to autoregressive models. However, one major drawback has been their slower inference speed, largely because they require multiple refinement steps and use bidirectional attention.
This paper has uncovered an interesting behavior in these models: the correct answer often appears internally well before the decoding process finishes. For instance, on benchmarks like GSM8K and MMLU, up to 97% and 99% of answers can be correctly identified using only half the usual steps. This observation led to the development of Prophet, a method that uses early commit decoding to speed up inference without extra training.
Inner Working of Prophet’s Early Commit Decoding
Prophet works by monitoring the confidence of the model’s predictions during each decoding step. It calculates the confidence gap (the difference between the top two predicted tokens) at every position. A large gap indicates that the model is highly certain about a token, which suggests it may not change in future steps.

Based on this gap, Prophet decides dynamically whether to continue refining or to finalize all remaining tokens at once. It uses a threshold that changes as decoding progresses: early on, it requires a very high confidence level to commit, reducing the risk of errors. Later, as predictions stabilize, it allows for earlier termination. This approach integrates smoothly into existing diffusion model setups and adds almost no computational overhead.

An illustration of the Prophet’s early-commit-decoding mechanism.
The process is fully adaptive and requires no retraining, which makes it easy to apply to models like LLaDA-8B or Dream-7B. By focusing on answer tokens and leveraging their early convergence, Prophet significantly cuts down the number of decoding steps while preserving output quality.
Evaluation and Performance of Prophet
The researchers performed experiments across multiple benchmarks and showed that Prophet reduces decoding steps by up to 3.4 times with minimal loss in accuracy. For example, Prophet nearly matches the performance of full-step decoding in general reasoning tasks like MMLU and ARC-Challenge. In some cases, it even slightly outperforms the baseline, possibly by avoiding unnecessary refinement that could introduce noise.
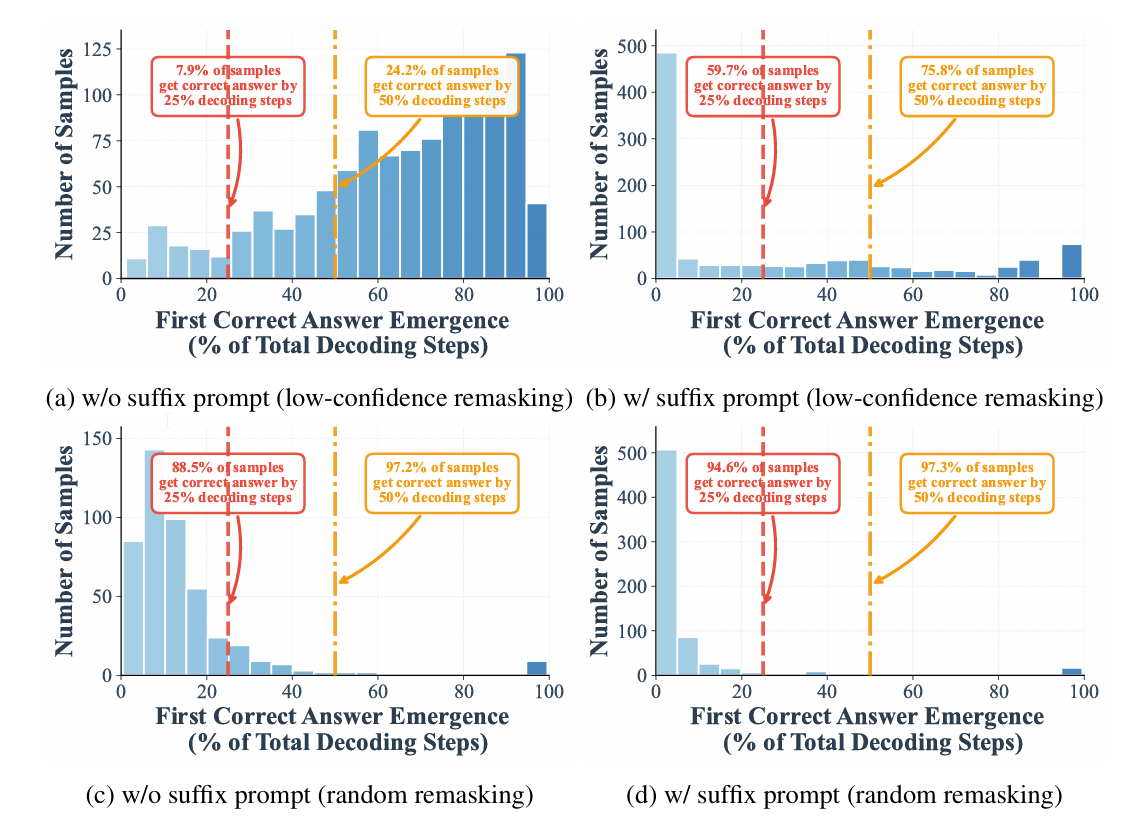
Distribution of early correct answer detection during decoding process.
On more demanding tasks like mathematical reasoning (GSM8K) and science questions (GPQA), Prophet maintains close to full accuracy while the naive half-step baseline often drops significantly.
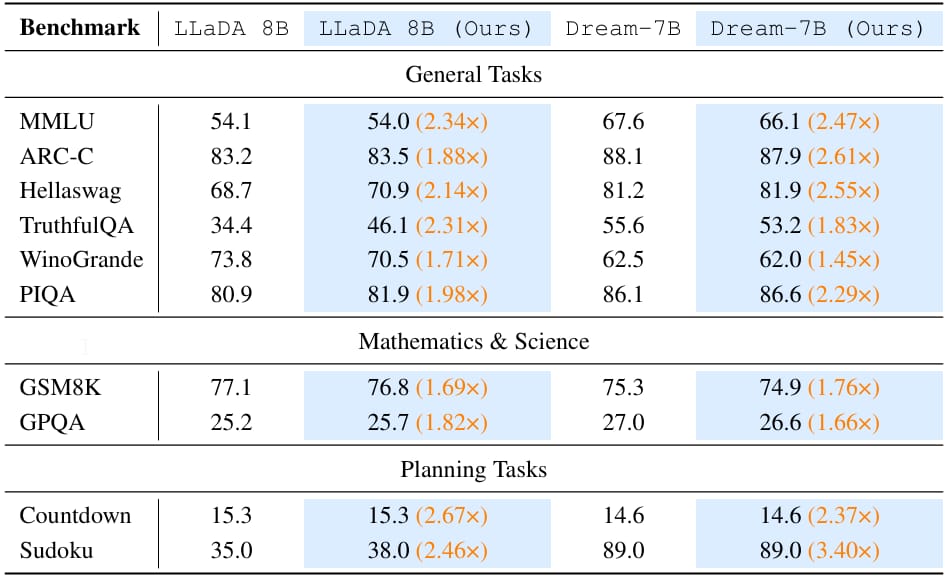
Benchmark results on LLaDA-8B-Instruct and Dream-7B-Instruct.
Reply