- The AI Timeline
- Posts
- RoPE Is Inherently Flawed
RoPE Is Inherently Flawed
plus more on Self-Play SWE-RL, Step DeepResearch, and Attention Is Not What You Need
by cloud
December 30, 2025
Dec 23rd ~ Dec 30th
#88 Latest AI Research Explained Simply
🗞️ Industry News in 1 Line
♥ 1.2k Z.ai is set for its IPO on Jan 8, 2026 on the Hong Kong Stock Exchange and set to raise $560 million at a valuation of 5.6 billion
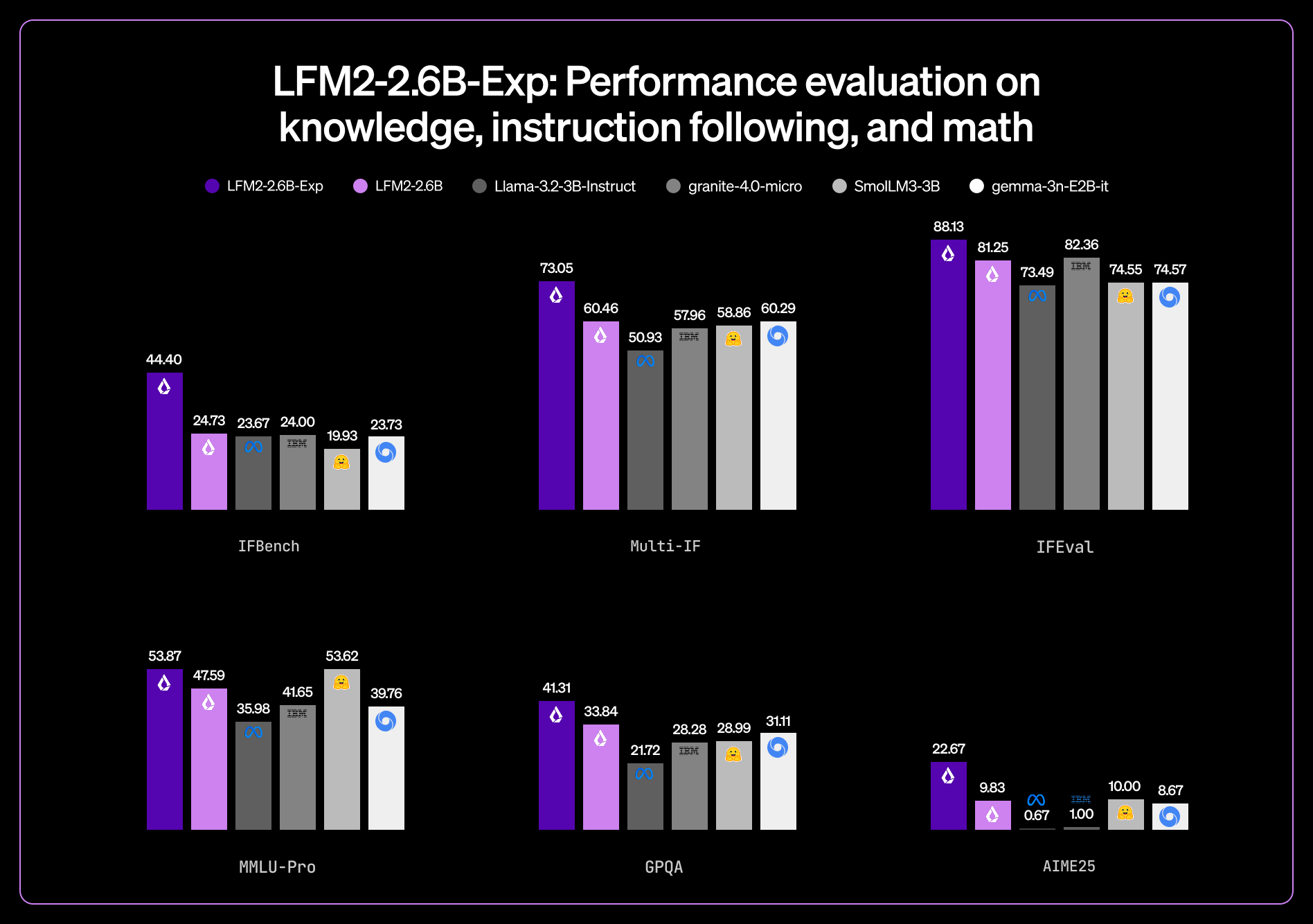
♥ 2.1k Liquid AI has announced the release of LFM2-2.6B-Exp, an experimental checkpoint built on LFM2-2.6B using pure reinforcement learning. The model delivers consistent gains in instruction following, knowledge, and math benchmarks, and outperforms other 3B models across these areas. Liquid AI also reports that its IFBench score surpasses DeepSeek R1-0528, despite being 263× smaller. Now on Hugging Face.
♥ 2.4k Nvidia recently made a massive $20 billion deal with AI chip startup Groq, acquiring most of Groq's AI chip assets and licensing its inference tech (LPU), while also "acquihiring" Groq's key team, including founder Jonathan Ross, to boost Nvidia's AI inference performance, though Groq remains independent for its cloud services.
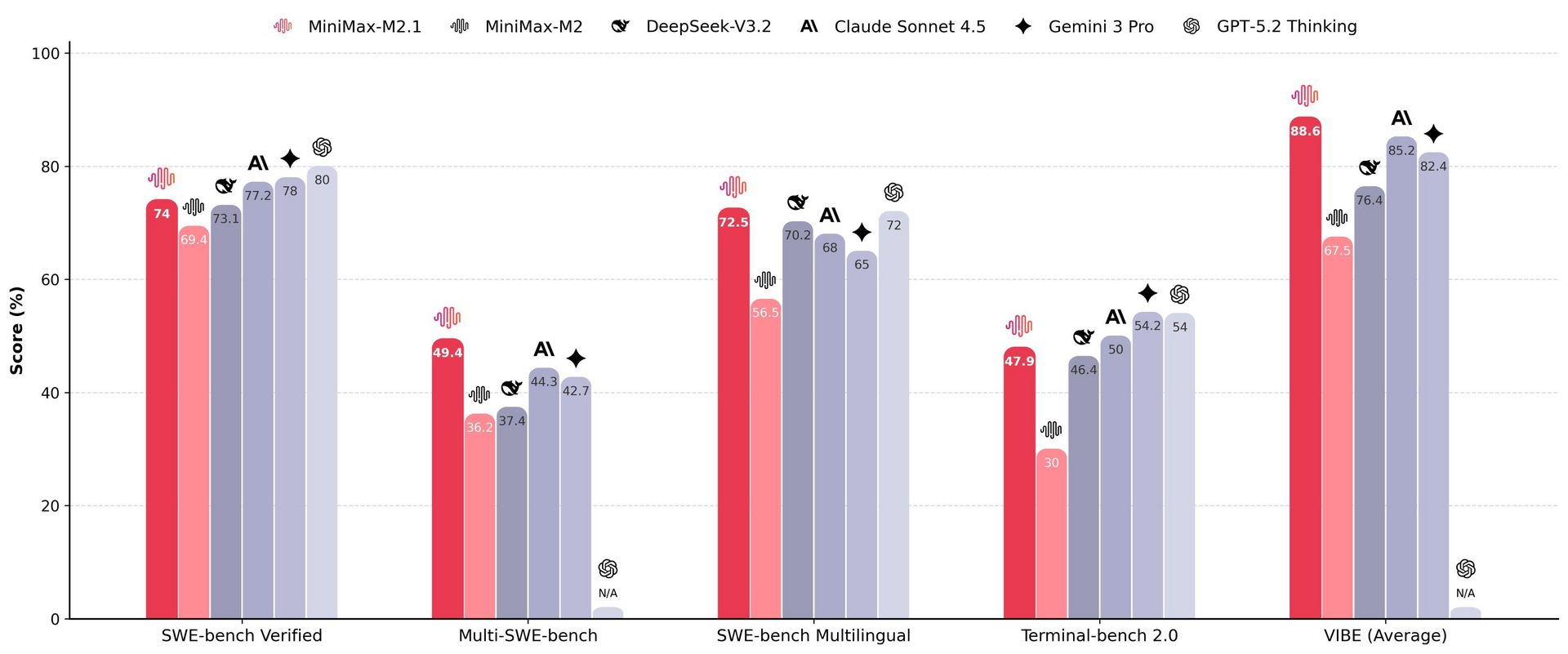
♥ 1.4k MiniMax has announced the open-source release of MiniMax M2.1, a SoTA model for real-world dev workflows and agentic applications. It uses a MoE with 10B active parameters and 230B total, aiming to be faster to run and easier to deploy than comparable models. Rankings #1 among open-source models and #6 overall for web dev arena. Now on HuggingFace.
Support My Newsletter
As I aim to keep this newsletter free forever, your support means a lot. If you like reading The AI Timeline, consider forwarding it to another research enthusiast. It helps us keep this up for free!
Decoupling the "What" and "Where" With Polar Coordinate Positional Embeddings
Gopalakrishnan et al. [The Swiss AI Lab (IDSIA), OpenAI, Center for Generative AI, University of Colorado]
♥ 1.3k RoPE
For modern AI to understand the world, it needs to track two distinct things: what a piece of information is and where it sits in a sequence. Rotary Position Embedding (RoPE) accidentally tangles the "what" and the "where" together, which confuses the model when it needs to make precise decisions based on just one of those factors. To solve this, the team developed a new approach called Polar Coordinate Position Embedding, or PoPE, designed to mathematically untangle these signals so the AI can process content and position independently.
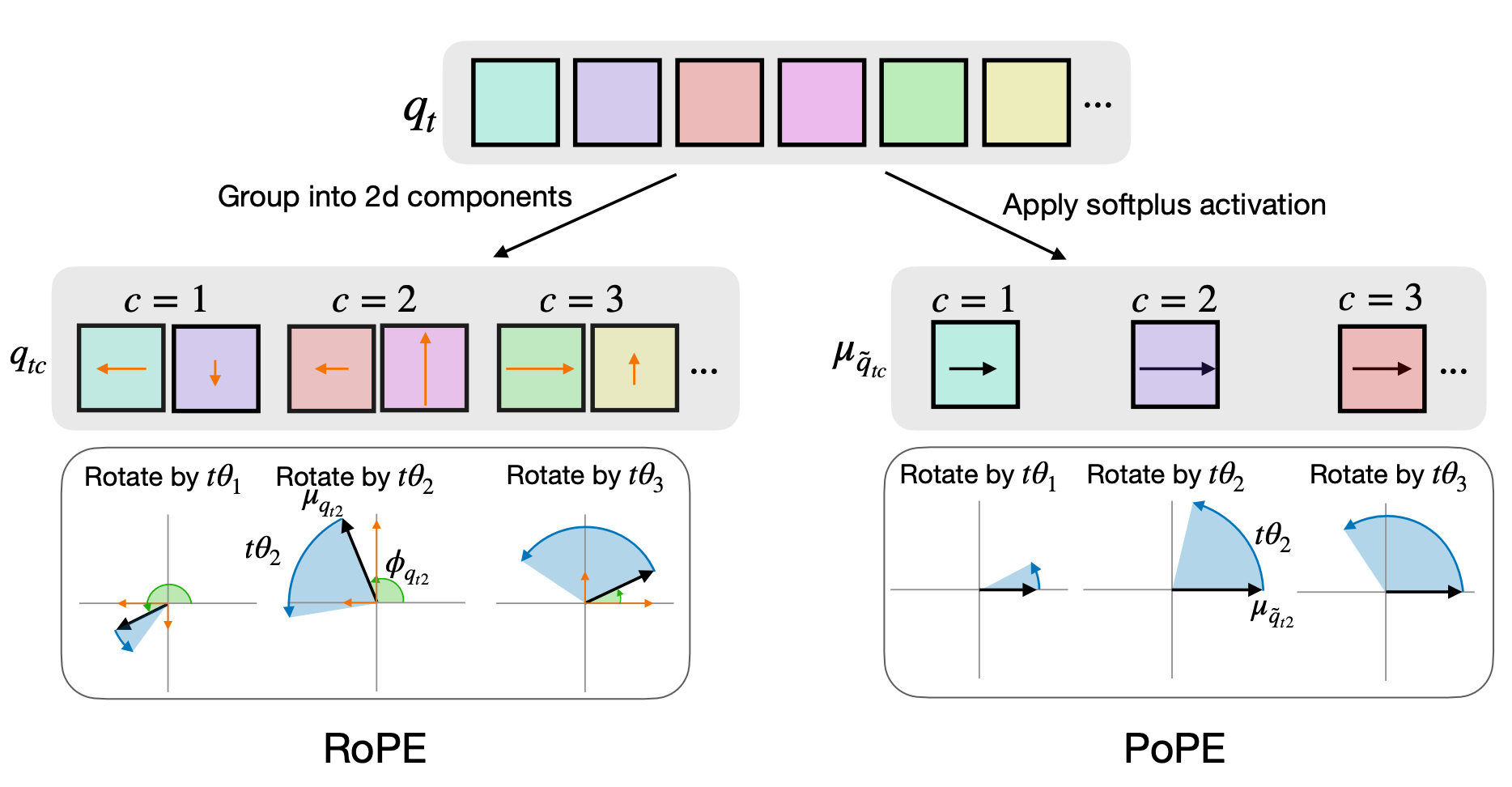
How RoPE and PoPE encode relative positions via rotations of queries.
In the polar coordinate system, the magnitude of a signal represents the content, and the angle represents the position. PoPE reduces the confusion found in previous models. When tested against standard baselines, this new method shows superior performance across a diverse range of complex tasks, including the generation of classical music and modeling the human genome.

Zero-shot performance on downstream tasks using Transformer models pretrained on OpenWebText with RoPE or PoPE positional encoding.
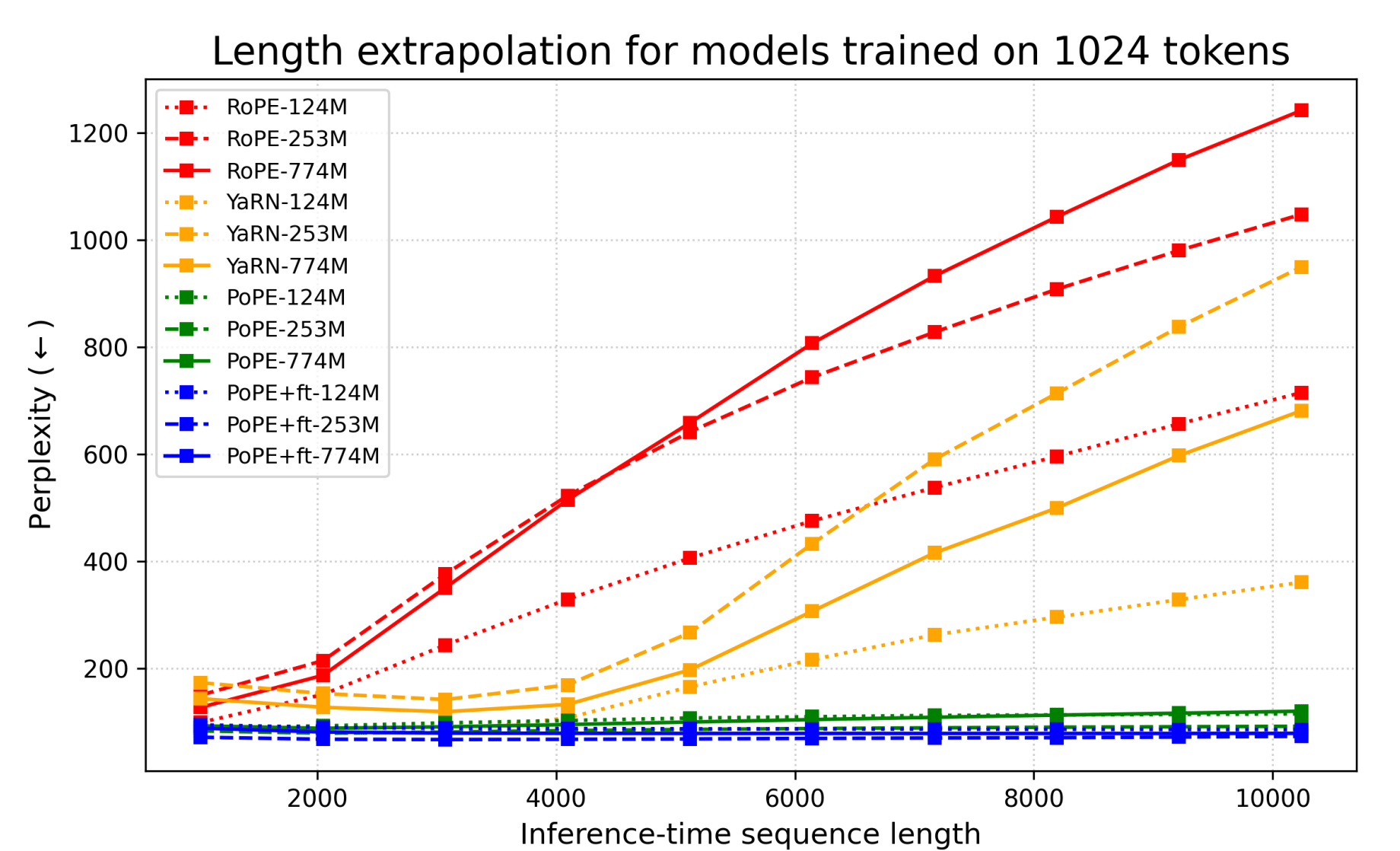
The researchers found that models using PoPE demonstrated a remarkable ability to handle sequences ten times longer than those for which they were trained. Unlike current state-of-the-art methods that require complex fine-tuning to "stretch" a model's attention span, PoPE naturally generalized to these longer contexts immediately, proving to be both more robust and data-efficient.
Toward Training Superintelligent Software Agents through Self-Play SWE-RL
Wei et al. [Meta FAIR, Meta, TBD Lab, UIUC, CMU]
♥ 1.6k LLM RL bycloud’s pick
Self-play SWE-RL (SSR) is a new framework designed to train superintelligent software engineering agents without relying on human-curated data. Current agents are limited by their dependence on finite resources, such as GitHub issues and manually written tests, which forces them to imitate human developers rather than discover new solutions.

Overview of Self-play SWE-RL.
To overcome this barrier, SSR allows a Large Language Model (LLM) to self-improve by interacting with raw, sandboxed code repositories. The system requires only the source code and dependencies, which eliminates the need for pre-existing test suites or natural language issue descriptions.

Bug-injection patches generated by code hunk removal (left) and historical change reversion (right).
The training process uses a single LLM alternating between two roles: a bug-injection agent and a bug-solving agent. The injection agent explores the repository to generate a "bug artifact," which consists of a bug-inducing patch, a custom test script, and a patch that weakens existing tests to hide the bug.
These valid bug artifacts are then passed to the solver agent, which attempts to fix the codebase using the strict test specifications defined by the injector. Failed attempts by the solver are converted into "higher-order bugs," creating an evolving curriculum that becomes increasingly complex as the agent improves.

Key consistency checks applied to validate bug artifacts, the full set described in the text.
SSR was tested on the SWE-bench Verified and SWE-Bench Pro benchmarks using the Code World Model (CWM) as a base. The results show that SSR achieves significant self-improvement (+10.4 and +7.8 points, respectively) and consistently outperforms baselines trained on human-curated data.
Meta-RL Induces Exploration in Language Agents
Jiang et al. [EPFL, ETH Zurich, Idiap Research Institute]
♥ 877 LLM RL
AI can handle some complex tasks, but it struggles when we ask it to explore. While current LLMs can be trained via RL to solve specific problems, they often become rigid, and end up memorizing a single successful path rather than understanding how to adapt.
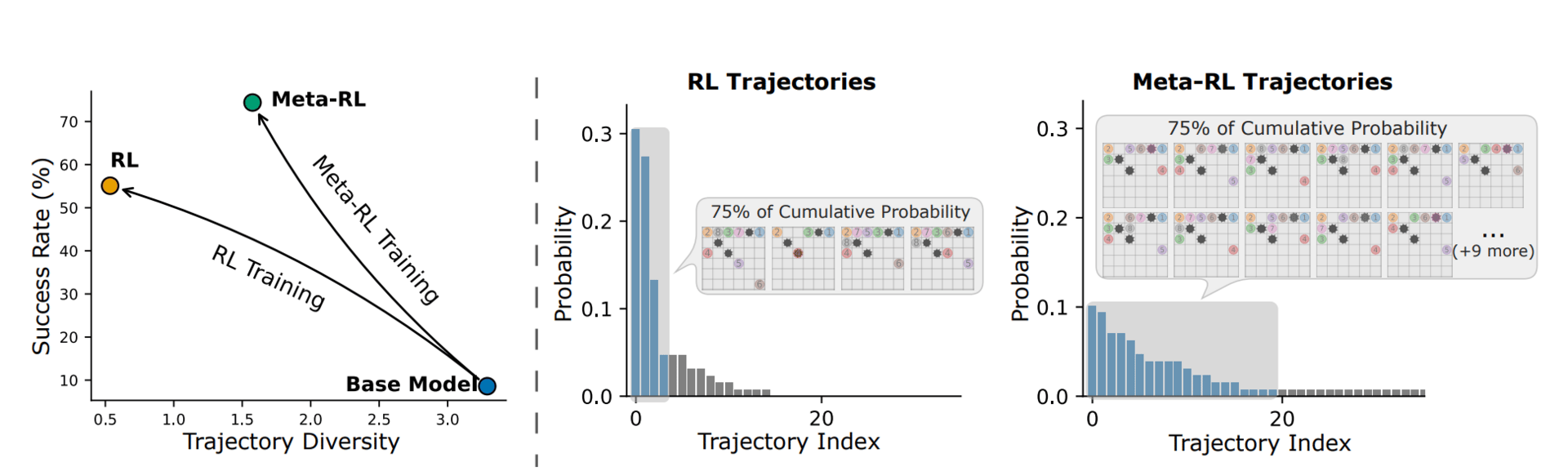
Comparison of RL and Meta-RL training on the MineSweeper environment.
When faced with a new or slightly changed environment, these agents frequently fail because they haven't learned how to learn from their mistakes. The research team sought to bridge this gap by designing a system that treats failure not as a dead end, but as a strategic investment. Their goal was to create agents that actively experiment with their surroundings and use that feedback to improve, mimicking the way a human might play a few practice rounds of a new game to understand the rules before trying to win.
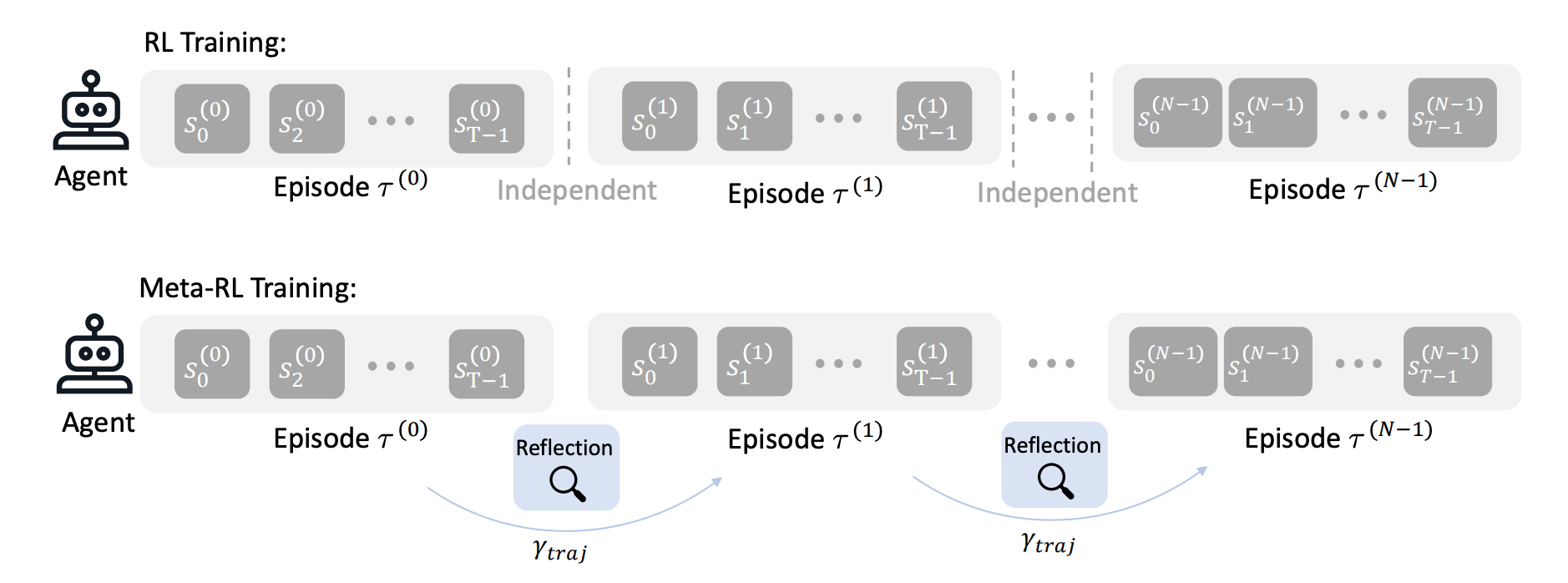
Comparison between the training processes of RL (top) and Meta-RL used in LAMER (bottom).
The team introduced a framework called LAMER that fundamentally shifts the training objective from winning a single episode to maximizing success over a series of attempts. By analyzing how agents behave across multiple tries, the researchers found that their model learned to sacrifice immediate rewards in favor of gathering information.
The agent effectively "reflects" on its previous performance, using the context of past failures to adjust its strategy in real-time without needing complex mathematical updates to its core programming. In testing across diverse environments (ranging from logic puzzles like Minesweeper to web navigation tasks), this approach created agents that were significantly more successful and creative. Instead of collapsing into repetitive behaviors, these agents maintained a diverse set of strategies and proved capable of solving problems that standard reinforcement learning models simply could not handle.
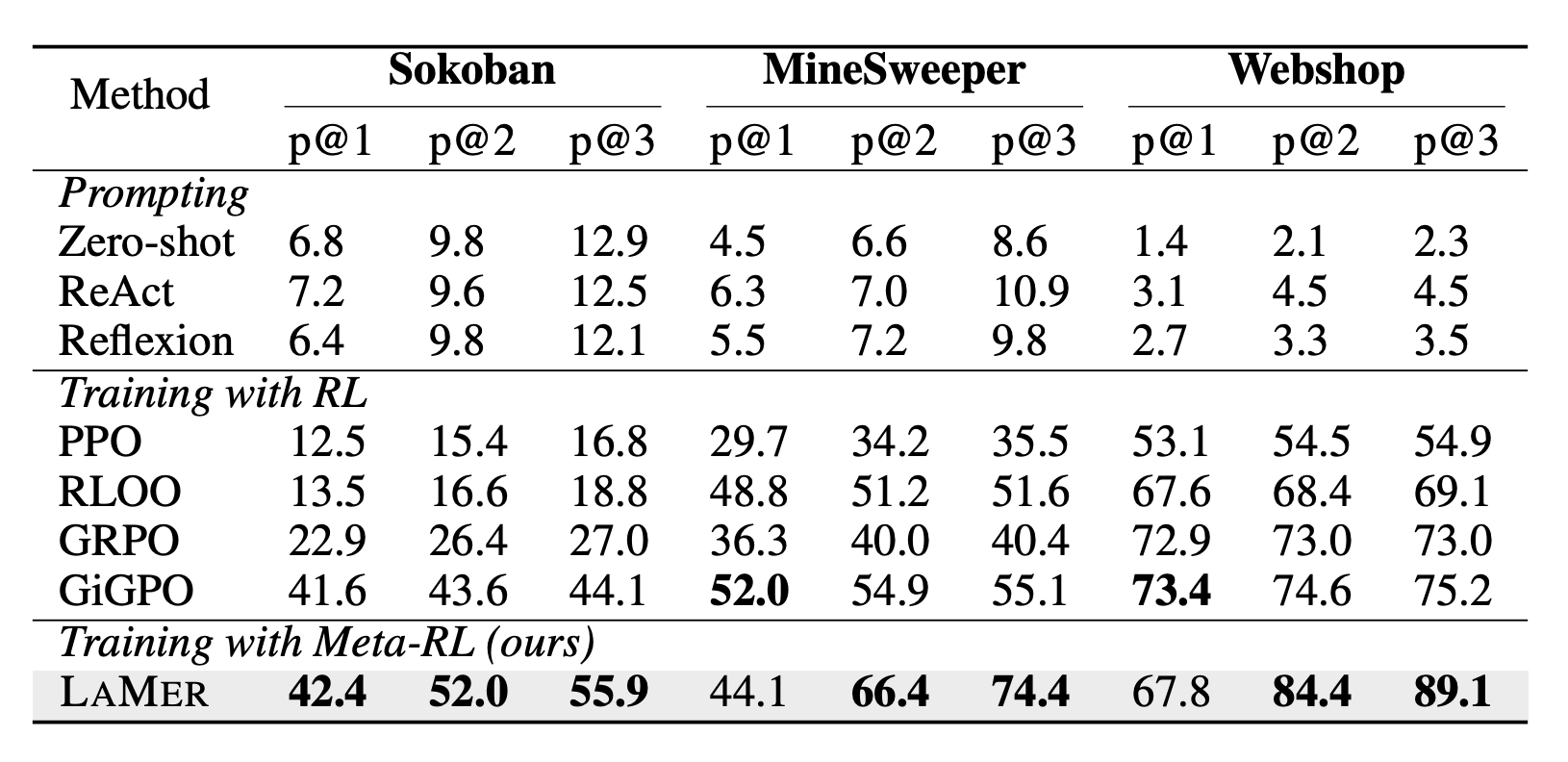
Performance on Sokoban, MineSweeper and Webshop environments.
Step-DeepResearch Technical Report
StepFun
♥ 757 LLM Deep Research
Researchers have identified an important distinction between simple search and true research. While current AI is excellent at answering specific, closed questions, it often stumbles when faced with open-ended projects that require long-term planning and logical structuring. It is challenging to create an agent that doesn't just retrieve links but understands the intent behind a request and can navigate the ambiguity of the real world.
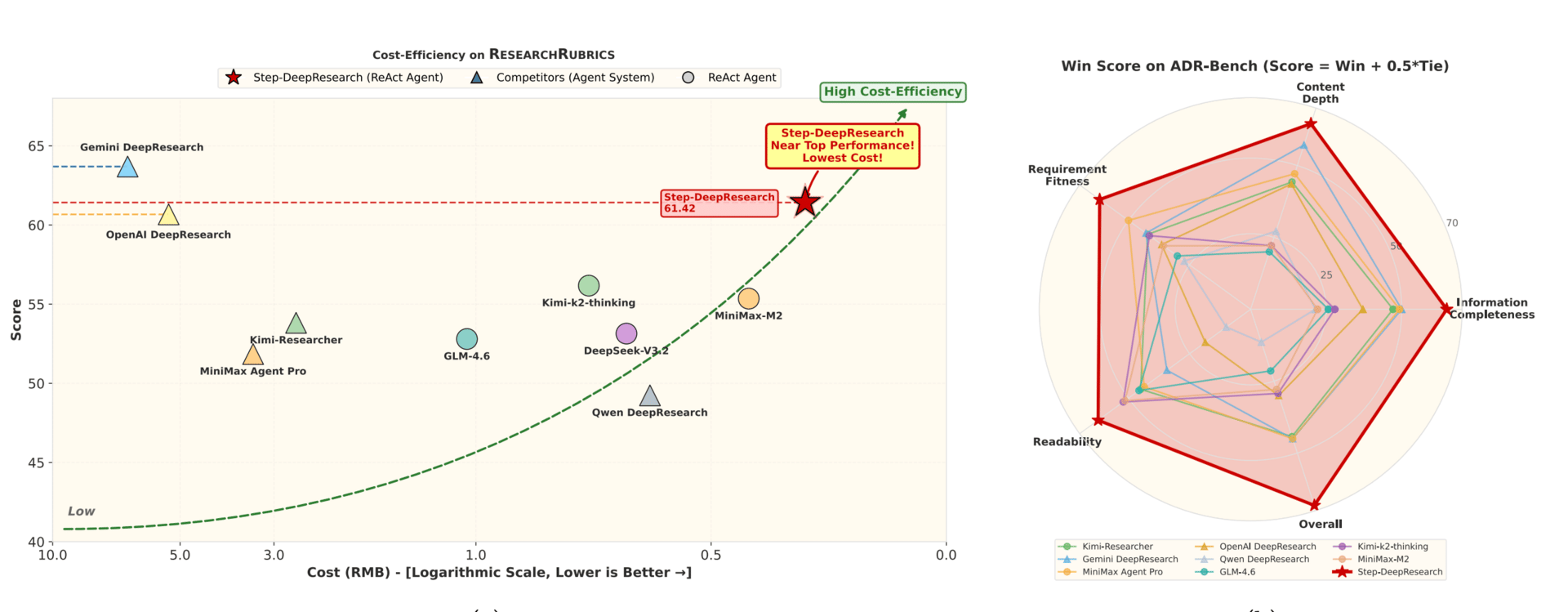
Comprehensive Evaluation of Step-DeepResearch.
The team developed Step-DeepResearch, a framework that achieves expert-level performance without relying on massive, expensive computational resources. Instead of just feeding the model more data, they focused on training "atomic capabilities", fundamental skills like decomposing a complex problem, verifying information across multiple sources, and reflecting on mistakes in real-time.

By teaching the model to internalize this cognitive loop of planning, executing, and self-correcting, they created a medium-sized system that rivals the performance of the industry's largest proprietary models. It shows that a refined training strategy, which prioritizes decision-making and synthesis over raw size, can produce an agent that effectively navigates complex workflows to produce comprehensive reports.

Step-DeepResearch System Architecture.
Attention Is Not What You Need
CHONG [Meta, UT Austin, UCL, UC Berkeley, Harvard University, Periodic Labs]
♥ 1.1k Attention Alternative
If you know anything about how LLMs work, then you would have heard about Transformers. Transformers use "self-attention", which is a mechanism that requires every word in a sequence to continuously check its relationship with every other word.
Although it is incredibly effective, this process creates a massive, opaque web of calculations that becomes computationally expensive and notoriously difficult for humans to interpret. Researchers recently posed a provocative question: Is this expensive "attention" mechanism actually necessary for AI to reason, or is it just one inefficient way to achieve a goal?
To solve this, the team developed a new architecture called the Causal Grassmann Transformer, which completely removes the standard attention mechanism. Instead of building a massive grid of connections between all words, the model treats language processing as a flow through a specific mathematical landscape known as a Grassmann manifold. The system condenses information into lower dimensions and interprets the relationships between words as geometric subspaces.
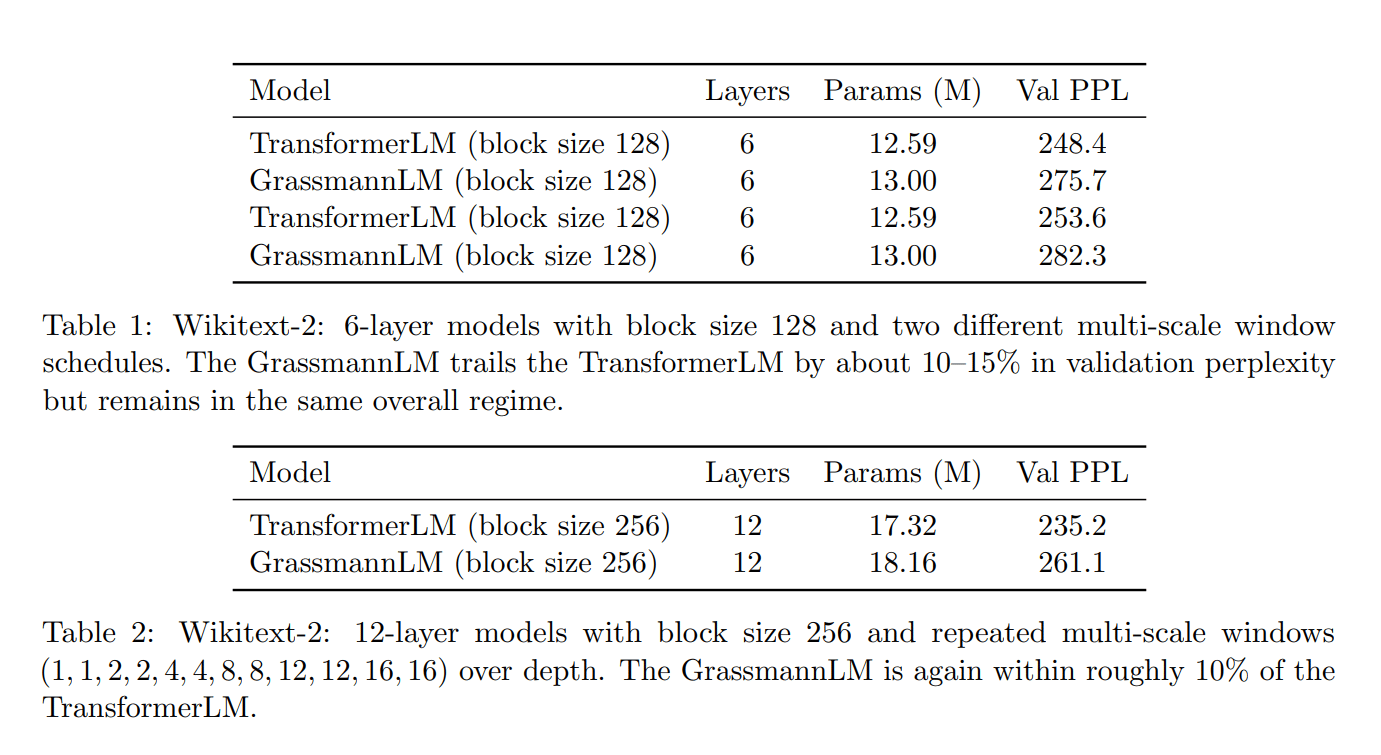
This geometry-first approach proved that high performance doesn't require the traditional heavy machinery of self-attention. When tested on standard language modeling tasks, the simplified Grassmann model performed competitively with standard Transformers, achieving accuracy levels within a close margin of the established baselines.

This paper suggests that the future of language models may not rely solely on scaling up existing architectures, but rather on redesigning their mathematical foundations. By proving that "attention" can be replaced by "geometric evolution", this work opens the door to AI systems that are drastically more efficient and easier to audit.
Message from bycloud:
This will be the last issue of 2025! I hope you had a great holiday, and I wish you all the best in your endeavors in 2026!
Reply