- The AI Timeline
- Posts
- The Only Perfect Score Paper at NeurIPS 2025
The Only Perfect Score Paper at NeurIPS 2025
Breaking down "Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?"
by cloud & Gifted Gummy Bee
December 04, 2025

Their NeurIPS poster
Project Page | Code | Paper
This paper called “Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?” was published back in April, and in this year’s NeurIPS, it has received a staggering (6,6,6,6) score, which is the highest rating a paper can ever receive. It is also the only paper that has received the perfect score at this year’s NeurIPS.
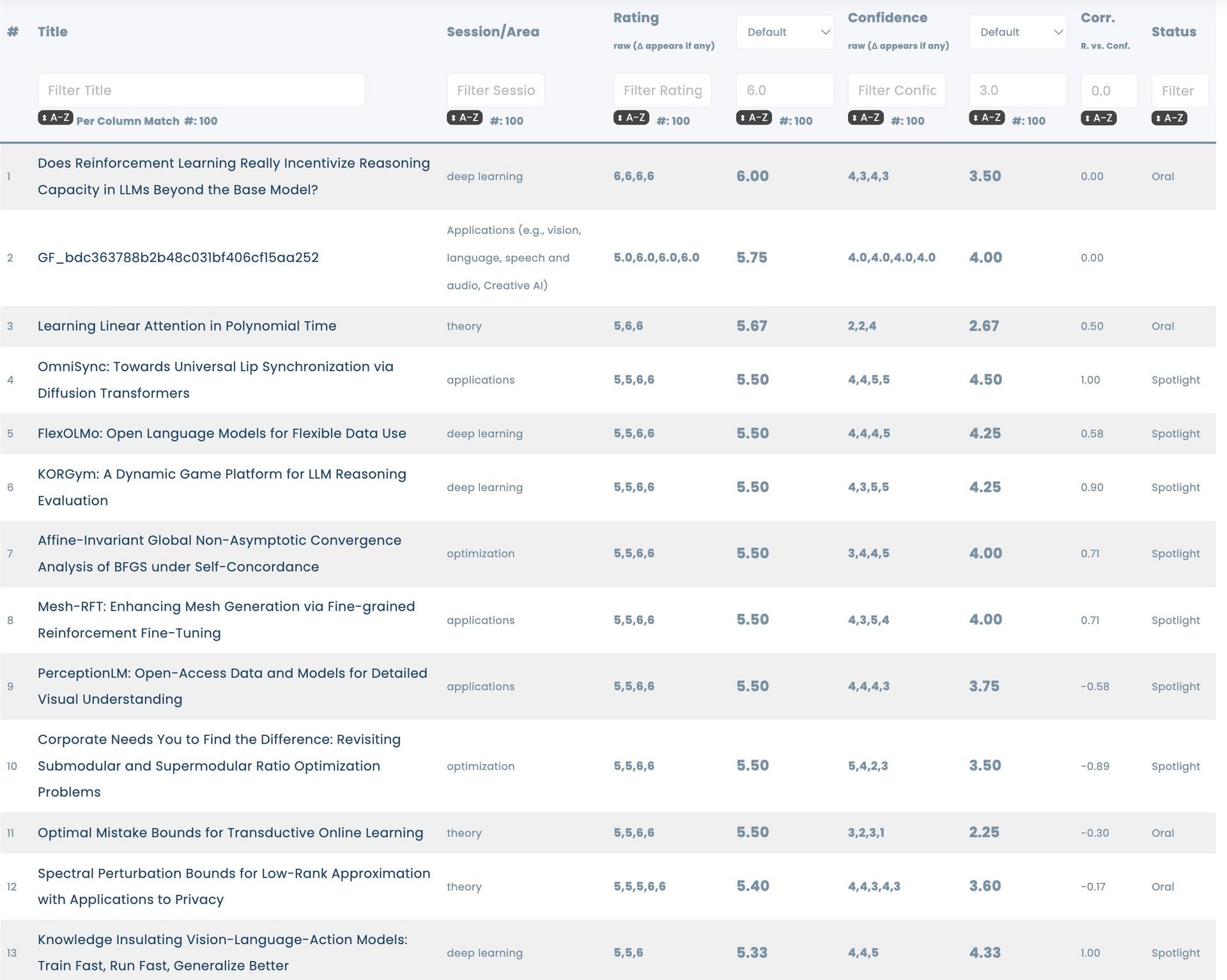
Top rated NeurIPS 2025 papers
So in this blog, let’s dive deeper into what idea did this paper explore and along with the authors’ rigor, is able to stand at the pinnacle of research in 2025.
Introduction
If you are able to spin up DeepSeek-R1-Zero (r1-zero) and DeepSeek-V3-Base right now, throw them a few prompts.
There’s something rather odd that you can pick up. With DeepSeek-V3-Base, the first token it generates would always be something wildly different no matter how diverse the prompt would be.
But with r1-zero, its first few tokens seem to be always the same, starting with something like "Okay", "Hmm" or some slight variations.
And this is by no coincidence the work of reinforcement learning, more specifically, reinforcement learning with verifiable rewards (RLVR).