- The AI Timeline
- Posts
- Top 3 Rated ICLR 2025 Papers - LoRA Done RITE, IC-Light, HyCoCLIP
Top 3 Rated ICLR 2025 Papers - LoRA Done RITE, IC-Light, HyCoCLIP
#32 | Latest AI Research Explained Simply
by cloud
November 19, 2024
In this issue: x3 industry news, x3 AI research papers
Nov 10th ~ Nov 17th
🗞️ Industry News in 1 Line
♥ 1.4k Qwen-2.5 Turbo features context length up to 1M tokens, and can generate them in 68 seconds, a 4.3x speedup. The price remains ¥0.3 / 1M tokens.

♥ 2.7k Mistral’s Le Chat got an upgrade. Includes feature like web search, vision, canvas ideation, and coding. All are currently free during their beta. Try their Le Chat now.

♥ 1.3k Cerebras’ Llama-3.1 405B now runs at 969 tokens/s. With 128K context length, 16-bit weights, they are the industry’s fastest time-to-first token @ 240ms.

LoRA Done RITE: Robust Invariant Transformation Equilibration for LoRA Optimization
Yen et al. [UCLA, Google, UT Austin]
♥ Rating: 8.0 LoRA
Introduction to LoRA-RITE
Current LoRA optimizers lack transformation invariance, meaning their weight updates depend on how the two LoRA factors are scaled or rotated. This leads to inefficient learning where one LoRA factor often dominates the optimization process while the other remains nearly fixed.
This paper introduces LoRA-RITE, an adaptive matrix preconditioning optimizer specifically designed for LoRA that achieves transformation invariance while remaining computationally efficient. The proposed solution shows significant improvements in performance across multiple datasets and architectures, for example achieving 55.50% accuracy on GSM8K with Gemma 7B IT model compared to Adam's 48.37%, while maintaining low computational overhead especially when the LoRA rank is much smaller than the original matrix dimensions.
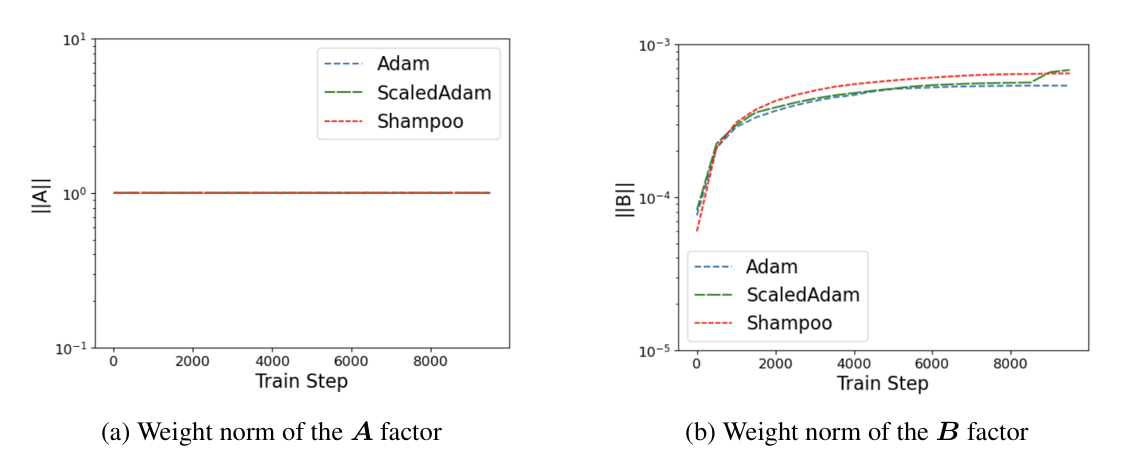
Understanding LoRA-RITE Algorithm
LoRA-RITE solves the transformation invariance problem through a clever two-part approach. First, it introduces "unmagnified gradients" that only depend on the directional information of the LoRA factors (A and B), stripping away the magnitude information that causes inconsistency in updates. Second, it applies adaptive matrix preconditioning using these unmagnified gradients, but only on the smaller dimension (the LoRA rank side) to keep computational costs low.

The algorithm also carefully tracks and adjusts for any information lost when the factors change their orientation during training, and incorporates both first and second moments (like Adam does) while maintaining transformation invariance. This results in more balanced and efficient updates to both LoRA factors, avoiding the common problem where one factor dominates the optimization while the other remains static, all while keeping computational overhead minimal when the LoRA rank is small compared to the original matrix dimensions.
Evaluating LoRA-RITE
LoRA-RITE consistently outperforms other popular optimizers including Adam, LoRA+, ScaledAdam, Shampoo, and Lamb across various tasks and model sizes. On the Super-Natural Instructions dataset, which includes diverse NLP tasks, LoRA-RITE shows significant improvements in both classification and generation tasks. For example, with Gemma-7B, it achieves 71.26% accuracy on CauseEffect compared to Adam's 67.17%.
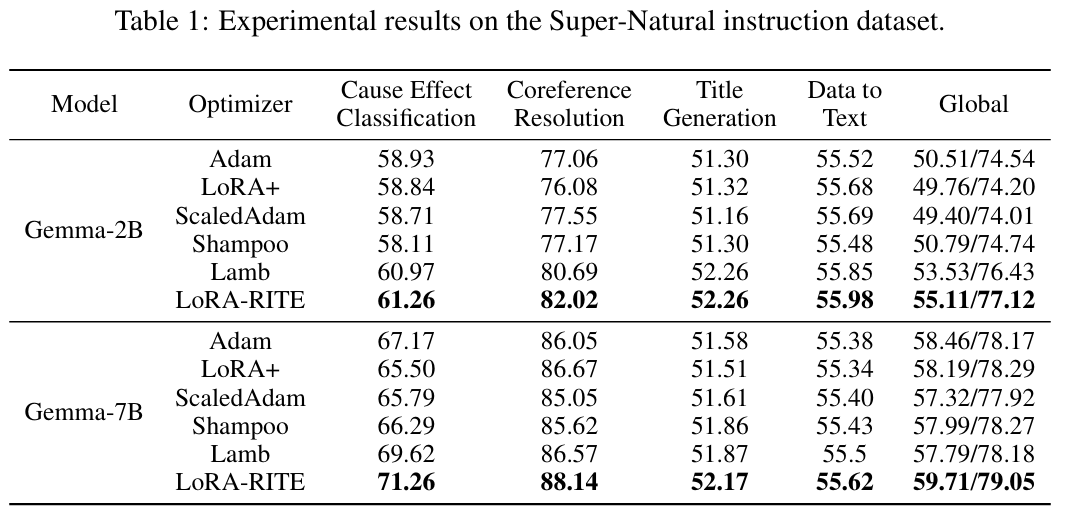
While Lamb (which has scalar scale invariance but not transformation invariance) often performs second-best, there's still a significant gap between it and LoRA-RITE. All these improvements come with minimal computational overhead compared to first-order methods like Adam, making LoRA-RITE a practical choice for LoRA fine-tuning.
Scaling In-the-Wild Training for Diffusion-based Illumination Harmonization and Editing by Imposing Consistent Light Transport
Anonymous authors [Paper Under Double-blind review]
♥ Rating: 9.0 Image Gen
Introduction to IC-Light
While diffusion models allow image illumination editing, they struggle to maintain image details and intrinsic properties (like surface albedo) when scaled up with diverse training data. This paper introduces "IC-Light", a method that enforces physical light transport consistency during training.
IC-Light is based on the principle that blending an object's appearances under different lighting conditions should match its appearance under mixed illumination. This physics-based constraint allows them to scale up training to over 10 million diverse images while ensuring the model only modifies illumination aspects while preserving other intrinsic properties.

Understanding Inner-working of IC-Light
The researchers created a diverse training dataset from three main sources: in-the-wild images with augmented lighting, 3D rendered data from Objaverse, and light stage captured images. For in-the-wild images, they process them by extracting environment maps, detecting foreground masks, generating background images, and creating "degradation appearances" that maintain the same albedo but with altered illumination. They carefully filter 50M images down to 6M suitable ones, combine these with 4M rendered images and light stage data to create their training set.

The core innovation lies in their training method that imposes consistent light transport during diffusion model training. They start with a vanilla image-conditioned diffusion model but add a crucial constraint based on the physical principle that blending appearances under different lighting conditions should match the appearance under mixed illumination (i.e., IL1+L2 = IL1 + IL2).
This constraint is implemented through a loss function that uses a learnable MLP to ensure the model only modifies illumination while preserving intrinsic properties. The final training objective combines this consistency loss with the standard diffusion loss, effectively preventing the model from developing random behaviors or altering non-illumination aspects of the image.
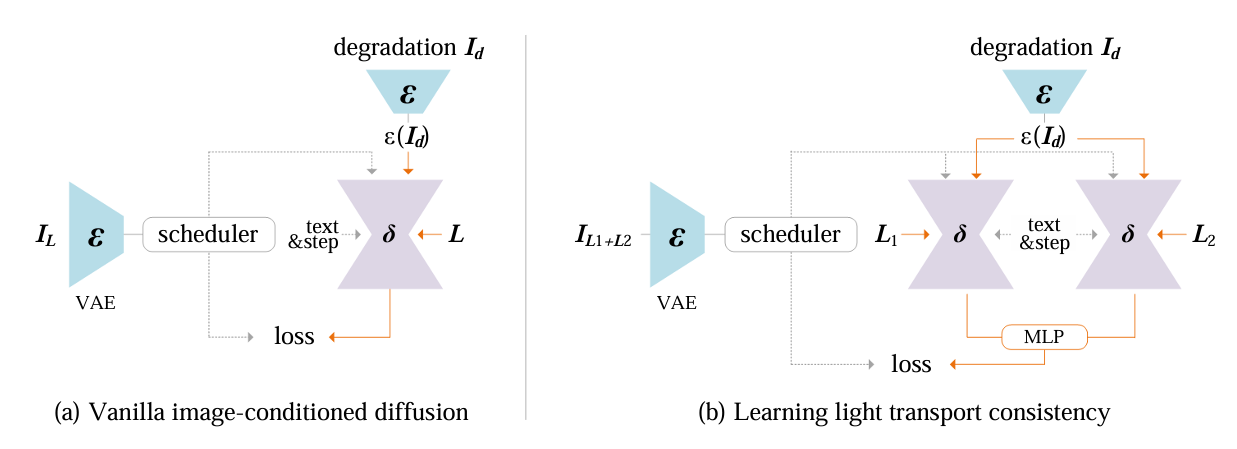
Evaluating IC-Light
Visually, the IC-Light model showed better robustness to shadows compared to Relightful Harmonization due to its larger and more diverse training dataset. It also produces competitive relighting results comparable to SwitchLight and generating more detailed normal maps, particularly for human subjects.

Quantitatively, when tested on 50,000 unseen 3D rendering samples, this method outperformed existing approaches like SwitchLight and DiLightNet across metrics, achieving the best LPIPS score of 0.1025 (indicating superior perceptual quality), while maintaining strong PSNR (23.72) and SSIM (0.8513) scores. We noticed that while models trained solely on 3D data achieved the highest PSNR, the full method combining multiple data sources provided the best balance between perceptual quality and performance across different metrics, demonstrating the value of their diverse training approach.

Do you like the long explainers?or prefer a much shorter paper explainers? |
Compositional Entailment Learning for Hyperbolic Vision-Language Models
Pal et al. [University of Amsterdam, Sapienza University of Rome]
♥ Rating: 8.0 VLM
Introduction to HyCoCLIP
LLMs can not understand the inherent hierarchical nature of visual and textual concepts as traditional models like CLIP primarily focus on holistic image-text alignment in Euclidean space. This paper proposes a new method called HyCoCLIP, which leverages hyperbolic space (better suited for representing hierarchical structures) and introduces a novel Compositional Entailment Learning approach that considers both the whole image-text pairs and their compositional elements (like object boxes and their textual descriptions).
This method not only maintains the broader context between images and text but also preserves the hierarchical relationships between components (for example, how individual objects relate to the overall scene) by positioning broader concepts near the origin of the hyperbolic space and more specific concepts towards the borders. This approach aims to create a more semantically rich and hierarchically aware representation that can better capture the natural structure of visual and linguistic information.
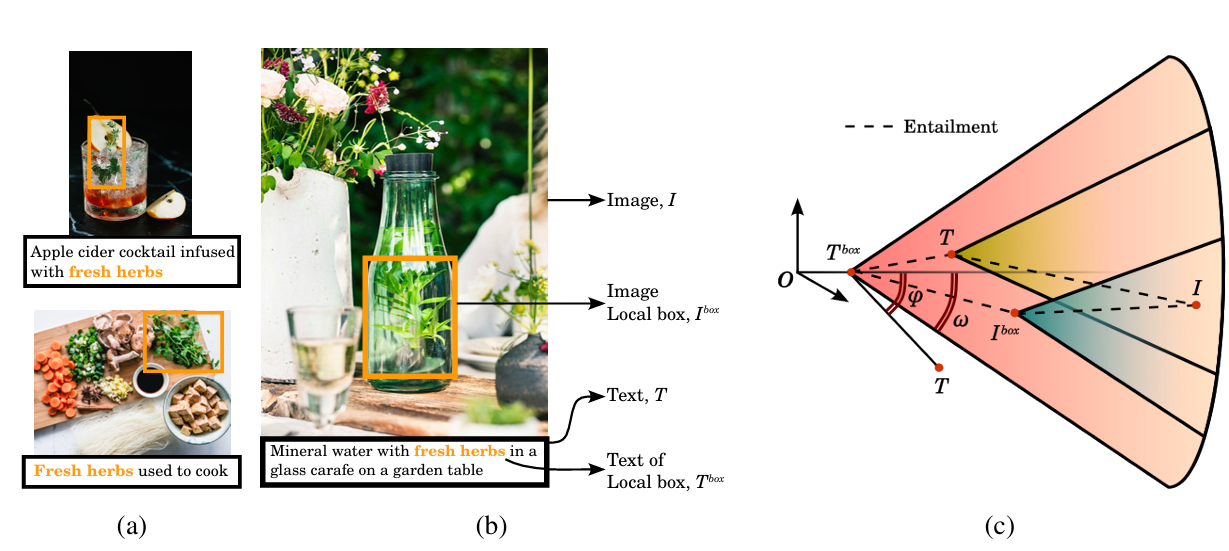
What is HyCoCLIP?
The HyCoCLIP model works by leveraging two main components to learn hierarchical relationships between images and text in hyperbolic space. The first component uses a contrastive learning approach that aligns both complete images with their full text descriptions, as well as object boxes (cropped regions of images) with their corresponding textual descriptions. Importantly, the model is designed to avoid incorrect negative pairs by only contrasting whole images with other whole images, and box-level information with appropriate counterparts, recognizing that different images might contain similar objects.
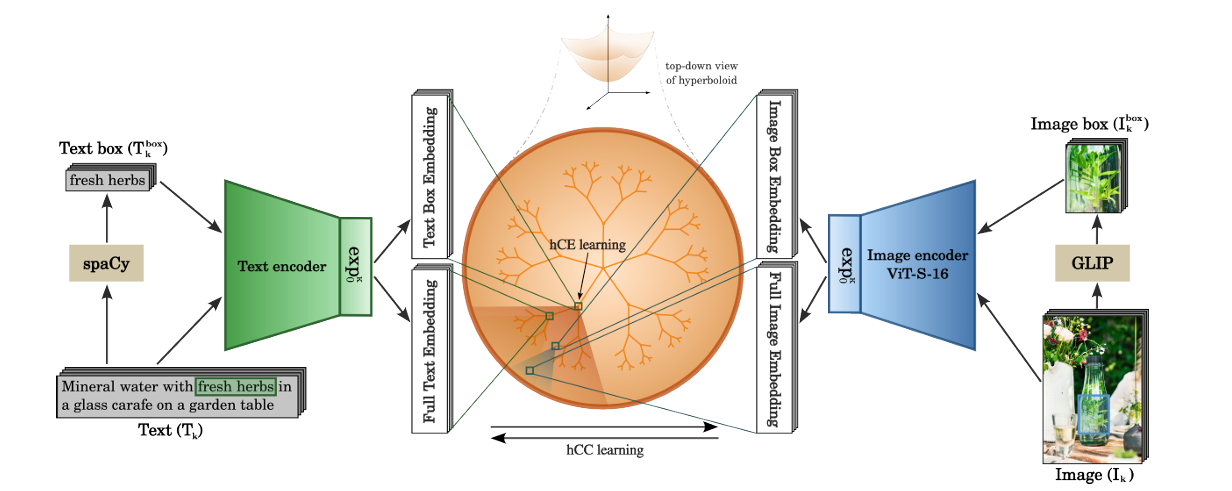
The second component introduces a novel entailment learning mechanism that enforces hierarchical relationships in the hyperbolic space. The model positions more general concepts (like object boxes and their descriptions) closer to the origin of the space, while more specific concepts (like complete images with their full context) are positioned further from the origin. This is achieved through "entailment cones" - regions in the hyperbolic space that define parent-child relationships between concepts.
The model uses these cones to maintain both inter-modal hierarchies (relationships between images and text) and intra-modal hierarchies (relationships between whole images and their parts, or complete text descriptions and their components). The final model combines these two components - contrastive and entailment learning - with appropriate weighting to create a comprehensive understanding of visual-textual hierarchies.
Evaluating HyCoCLIP
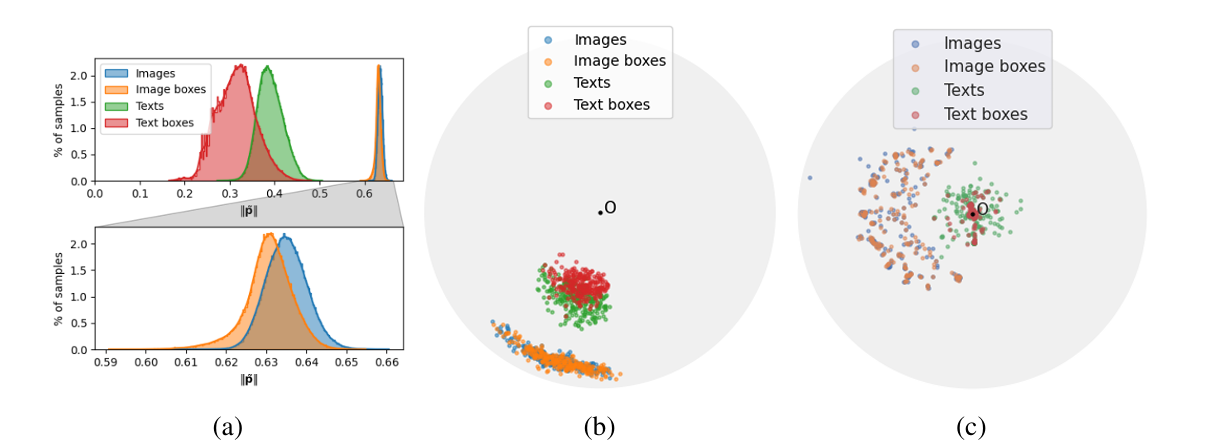
By applying histogram analysis and dimensionality reduction techniques (HoroPCA and CO-SNE) on HyCoCLIP's learned hyperbolic space, the researchers found that text and text-box embeddings show clear hierarchical separation in the hyperbolic space. However, image and image-box embeddings tend to have similar distributions due to the contrastive loss convergence and the inherent similarity between some images and their cropped regions. When interpolating between points in the hyperbolic space (either between two images or from an image to the origin), the model demonstrates rational hierarchical organization, which shows it successfully captures meaningful semantic relationships in the shared embedding space.
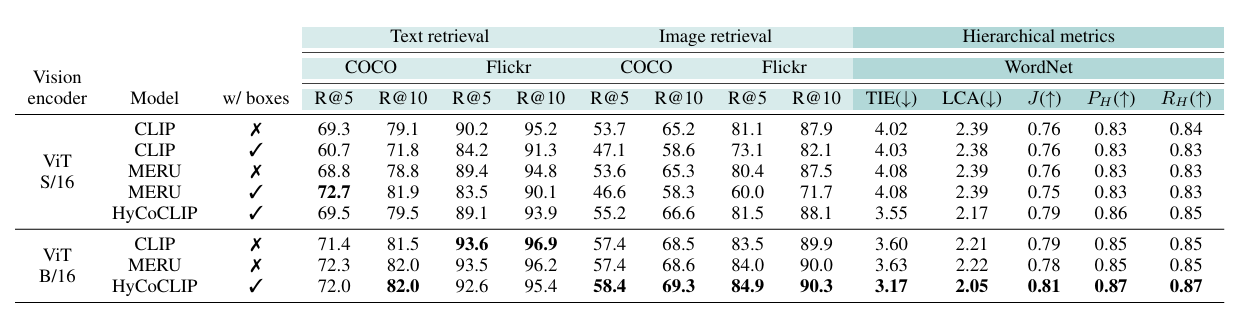
The experimental results show that HyCoCLIP outperforms both standard CLIP and MERU in zero-shot classification tasks and exhibits better scene understanding and hierarchical structuring, though it faces some limitations such as the need for generating bounding box information during training and potential suboptimal performance in large-scale retrieval tasks.
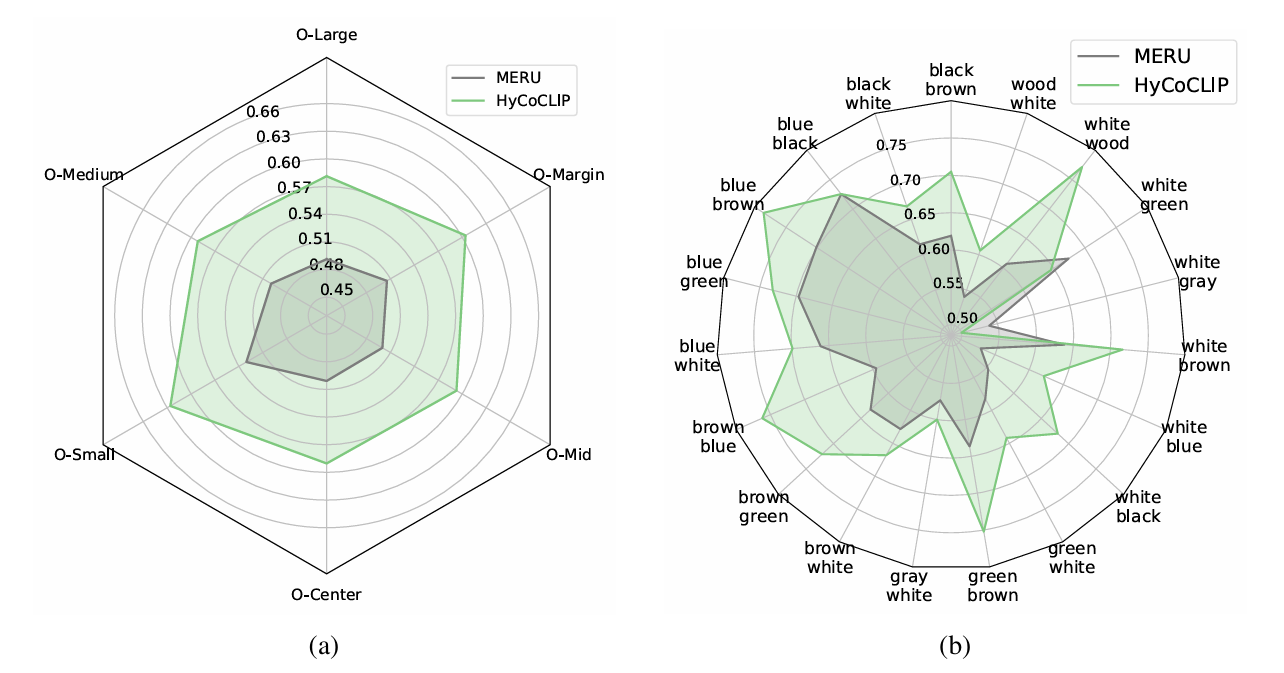
We observed that despite the increased computational overhead during training due to processing additional box-level information, this model maintains inference efficiency comparable to its predecessors while providing enhanced interpretability through distinct regional organization of images and texts in the embedding space.
The visualizations and interpolation experiments provide strong evidence that HyCoCLIP successfully learns meaningful hierarchical relationships between visual and textual content, even though there are some challenges in distinctly separating image-level and box-level representations.
Top-rated papers from ICLR 2025
papers included in previous issues are skipped
covered in this issue: Scaling In-the-Wild Training for Diffusion-based Illumination Harmonization and Editing by Imposing Consistent Light Transport - Rating: 9.0
discussed previously: OLMoE: Open Mixture-of-Experts Language Models - Rating: 8.67

covered in this issue: Compositional Entailment Learning for Hyperbolic Vision-Language Models - Rating: 8.0
SAM 2: Segment Anything in Images and Videos - Rating: 8.0
discussed previously: Differential Transformer - Rating: 8.0

covered in this issue: LoRA Done RITE: Robust Invariant Transformation Equilibration for LoRA Optimization - Rating: 8.0
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions - Rating: 8.0
Cybench: A Framework for Evaluating Cybersecurity Capabilities and Risks of Language Models - Rating: 8.0
Idea taken from this tweet:
Top-rated papers from ICLR 2025
Scaling In-the-Wild Training for Diffusion-based Illumination Harmonization and Editing by Imposing Consistent Light Transport
- Rating: 9.0
- openreview.net/pdf?id=u1cQYxR…OLMoE: Open Mixture-of-Experts Language Models
- Rating: 8.67
-… x.com/i/web/status/1…— jack morris (@jxmnop)
3:36 PM • Nov 15, 2024
more papers:
🚨This week’s top AI/ML research papers:
- Cut Your Losses in Large-Vocabulary Language Models
- Rapid Response: Mitigating LLM Jailbreaks with a Few Examples
- Convolutional Differentiable Logic Gate Networks
- LLaMA-Mesh
- LLMs Can Self-Improve in Long-context Reasoning
-… x.com/i/web/status/1…— The AI Timeline (@TheAITimeline)
3:47 PM • Nov 17, 2024
Reply