- The AI Timeline
- Posts
- Training Agents Inside of Scalable World Models
Training Agents Inside of Scalable World Models
Plus more about Polychromic Objectives for Reinforcement Learning and Stochastic activations
by cloud
October 07, 2025
Sep 29th ~ Oct 6th
#76 Latest AI Research Explained Simply
🗞️ Industry News in 1 Line
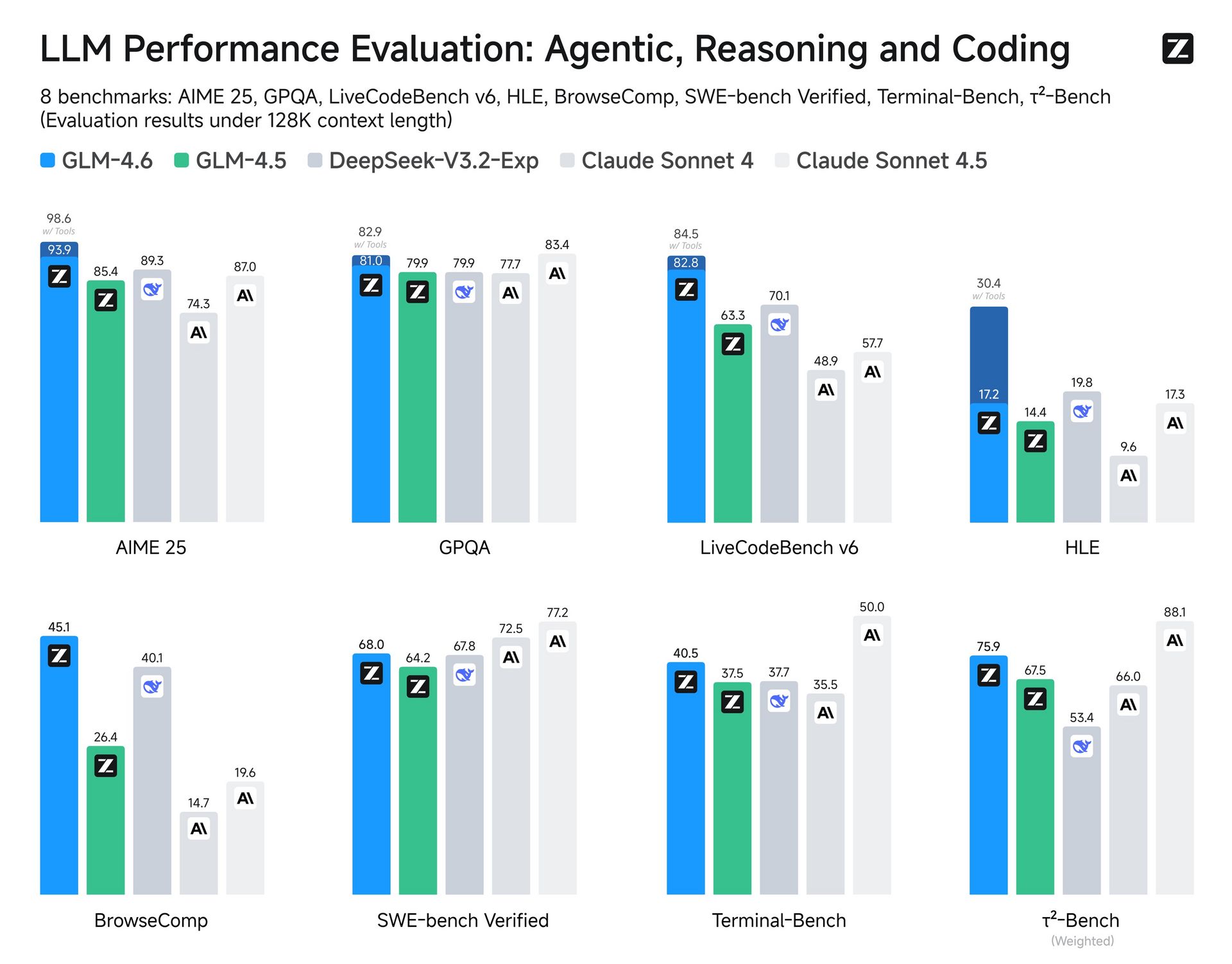
♥ 5.2k Zhipu AI has released GLM-4.6, a new LLM with a longer context window of 200K tokens, superior coding performance, and advanced reasoning capabilities. GLM-4.6 also has more capable agentic functions and an improved writing style that better aligns with human preferences. You can try out GLM-4.6 on the Z.ai website, use it via their API, or download the model weights from Hugging Face to run it locally.
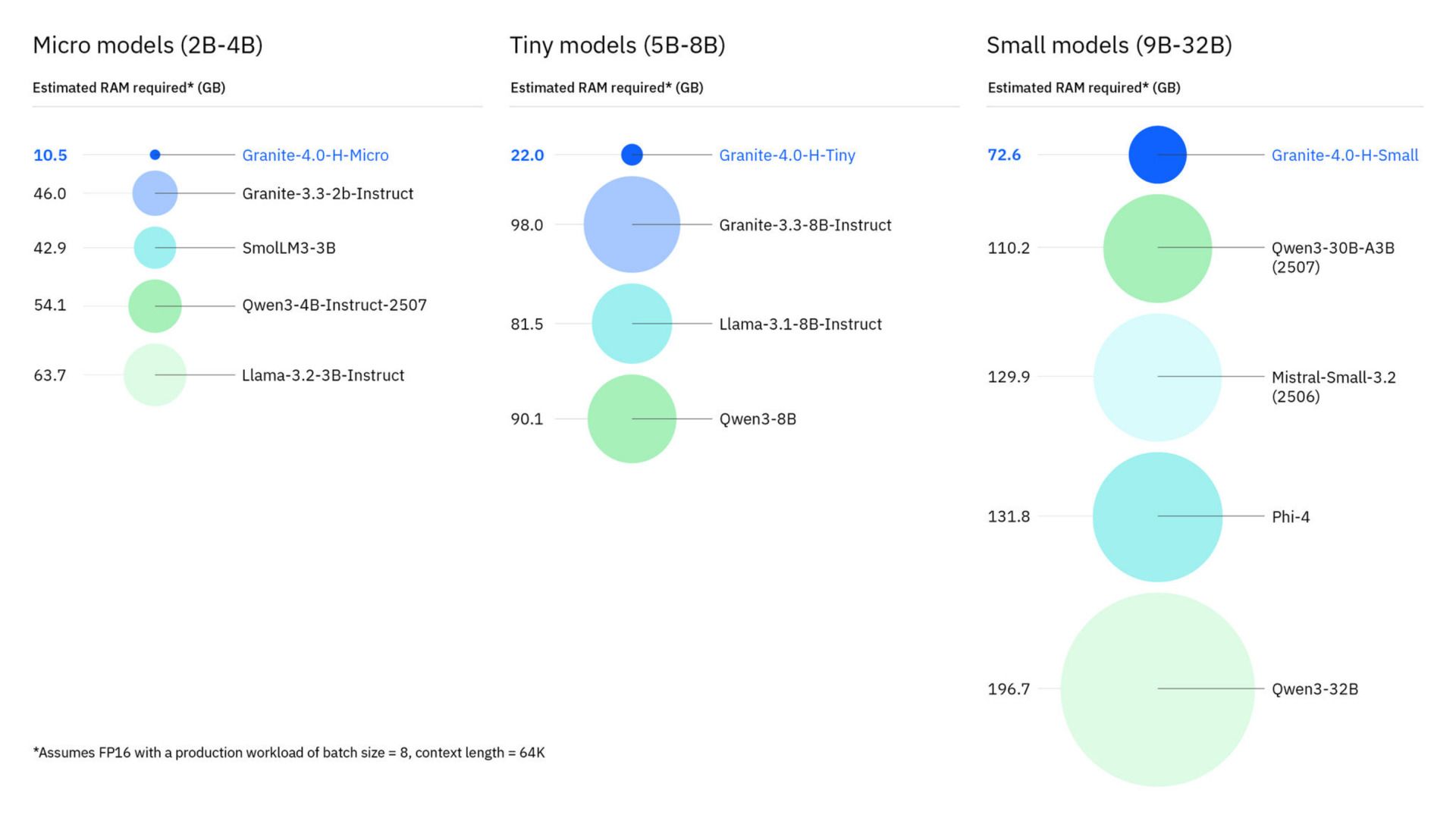
♥ 11k IBM has introduced Granite 4.0, a new generation of hyper-efficient, high-performance hybrid models that use a Mamba/transformer architecture, which significantly reduces memory requirements. The Granite 4.0 models are open-sourced under an Apache 2.0 license, and they are the first open models to receive ISO 42001 certification and be cryptographically signed, ensuring their security and trustworthiness. You can access Granite 4.0 on IBM watsonx.ai or via platform partners, including Hugging Face, Docker Hub, and NVIDIA NIM.
♥ 8.3k Perplexity has launched Comet, a new browser with a built-in personal AI assistant designed to work for you. Comet can help you with a variety of tasks, such as understanding how different news outlets are covering a topic, organizing your tabs, drafting emails, and even building a basic website.
♥ 2.4k Tencent has released Hunyuan Image 3.0, and this new version has enhanced dual encoders and advanced RLHF optimization to produce stunning, high-quality images. Hunyuan Image 3.0 supports both Chinese and English prompts and offers flexible aspect ratios for your creative projects. You can get started or see a demo on the Hunyuan Image website.

♥ 14k OpenAI has announced Sora 2, a video and audio generation model that can generate videos with synchronized dialogue and sound effects. It can even insert real-world people, animals, or objects into generated scenes with remarkable fidelity. You can use Sora 2 by downloading the new "Sora" social iOS app, which is now available in the U.S. and Canada.

♥ 425 Google has launched Jules Tools, which is a command-line interface for their asynchronous coding agent, Jules. This tool allows developers to interact with Jules directly from their terminal to perform tasks like writing tests, building new features, and fixing bugs. You can install Jules Tools via npm by installing the
@google/julespackage.
Support My Newsletter
As I aim to keep this newsletter free forever, your support means a lot. If you like reading The AI Timeline, consider forwarding it to another research enthusiast, It helps us keep this up for free!
Training Agents Inside of Scalable World Models
Hafner et al. [Google DeepMind]
♥ 485 LLM Wordl Models
Introduction to World Models and Dreamer 4
We all know about language models, but that’s not the only kind of model out there. Researchers have developed world models, which learn from videos and simulate experiences to train intelligent behaviors. However, previous world models have struggled to accurately predict complex object interactions, especially in rich environments like video games.
This paper introduces Dreamer 4, which addresses this challenge by learning a fast and accurate world model that enables reinforcement learning inside simulated experience.
Inner Workings of Dreamer 4
Dreamer 4 consists of two main components: a tokenizer and a dynamics model, both built on an efficient transformer architecture. The tokenizer compresses video frames into compact representations, while the dynamics model predicts future representations based on past actions and observations.
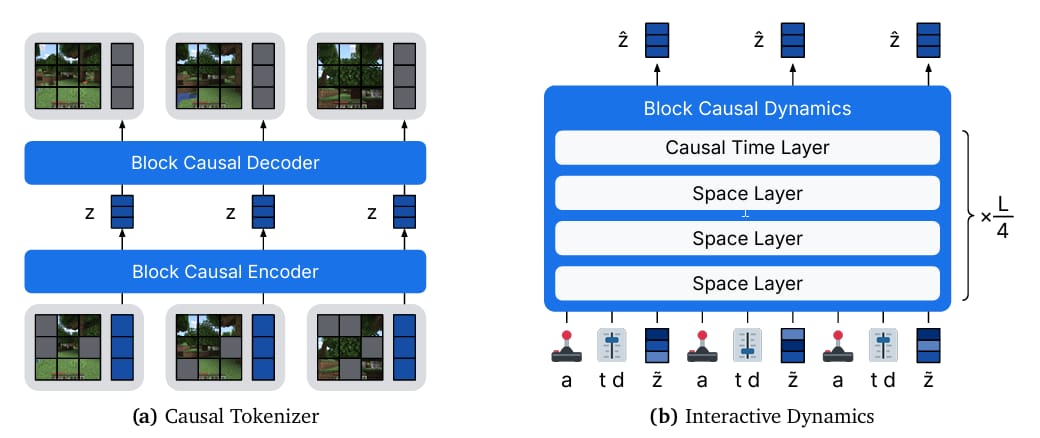
World model design. Dreamer 4 consists of a causal tokenizer and an interactive dynamics model, which both use the same block-causal transformer architecture.
This setup allows the model to handle multiple modalities, like images and actions, within a single transformer. It uses a shortcut forcing objective, which helps the model generate frames quickly and accurately with just four sampling steps per frame. This approach reduces error accumulation over long video sequences and supports real-time inference on a single GPU.

The model is trained in three phases. First, the tokenizer and dynamics model are pretrained on videos, with or without action labels. Next, the model is fine-tuned with task-specific inputs to predict actions and rewards. Finally, the policy is improved through imagination training, where the agent practices decision-making inside the world model using reinforcement learning.
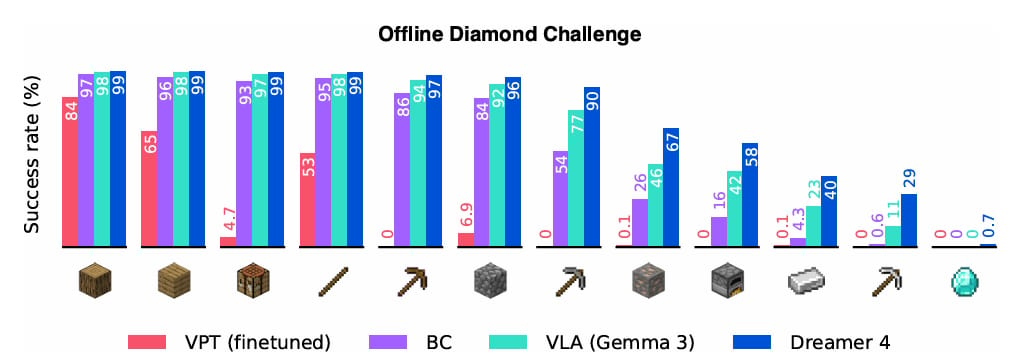
Agent performance in Minecraft without environment interaction.
Evaluation and Results of Dreamer 4
Dreamer 4 was able to achieve a major milestone: it is the first agent to obtain diamonds in Minecraft using only offline data, without any environment interaction. This task requires executing over 20,000 low-level mouse and keyboard actions from raw pixels. Dreamer 4 significantly outperforms previous methods, such as OpenAI’s VPT agent, despite using 100 times less data.
It also surpasses agents that leverage large vision-language models like Gemma 3, nearly tripling the success rate for crafting iron pickaxes. The world model itself shows remarkable accuracy in predicting object interactions and game mechanics, successfully completing 14 out of 16 complex tasks in human-in-the-loop evaluations.
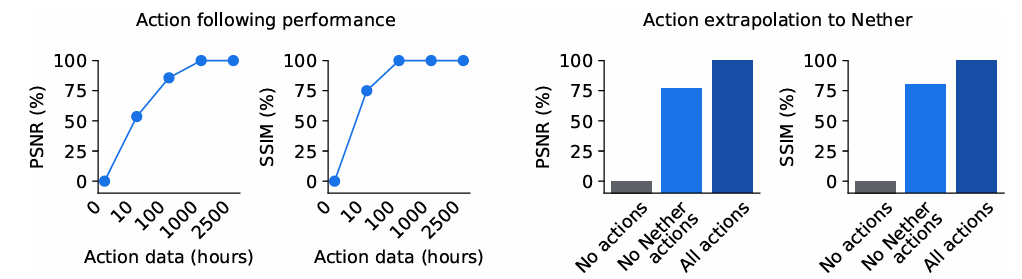
Action generalization.
Stochastic activations
Lomeli et al. [Meta FAIR, Ecole Normale Supérieure Paris Saclay, Paris Cité University]
♥ 22k LLM Activation Functions
Introduction to Stochastic Activations
Many AI architectures use ReLU activation because it produces sparse outputs (many zeros), which can speed up inference by reducing the number of calculations needed. However, ReLU has a known weakness: for negative inputs, its gradient is zero, which can halt learning in parts of the network during training.
On the other hand, the SILU activation avoids this problem and generally leads to better model accuracy, but it doesn’t produce sparsity. So, how can we get the best of both worlds?
This paper introduces stochastic activations. Instead of committing to one activation function, this approach randomly chooses between ReLU and SILU during training.
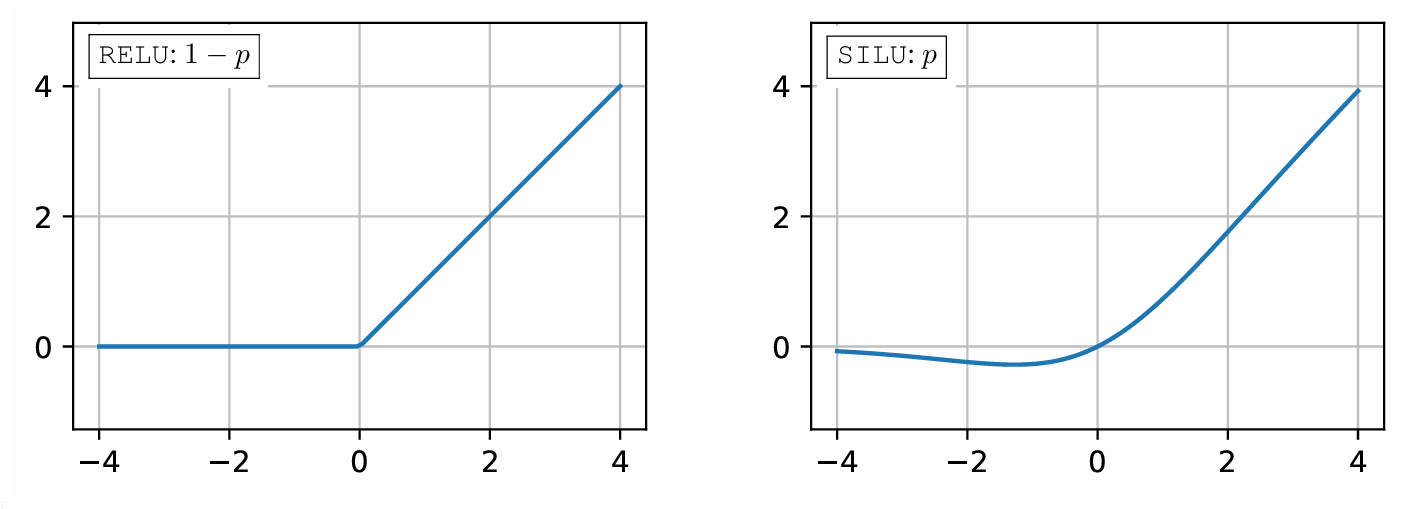
Stochastic activation randomly selects one of two activations when x < 0: (1) RELU selected with probability 1-p; otherwise (2) another activation, in particular SILU.
Inner Workings of Stochastic Activations
The core idea behind stochastic activations is to randomly switch between ReLU and SILU when the input to the activation function is negative. This is controlled by a Bernoulli random variable: with probability (p), the model uses SILU, and with probability (1-p), it uses ReLU.
For positive inputs, the function remains fixed, i.e., it is either the identity (like ReLU) or as SILU, depending on the configuration. This stochastic behavior during training ensures the network experiences both the smooth gradients of SILU, which help optimization, and the sparsity-inducing pattern of ReLU, which is useful later.
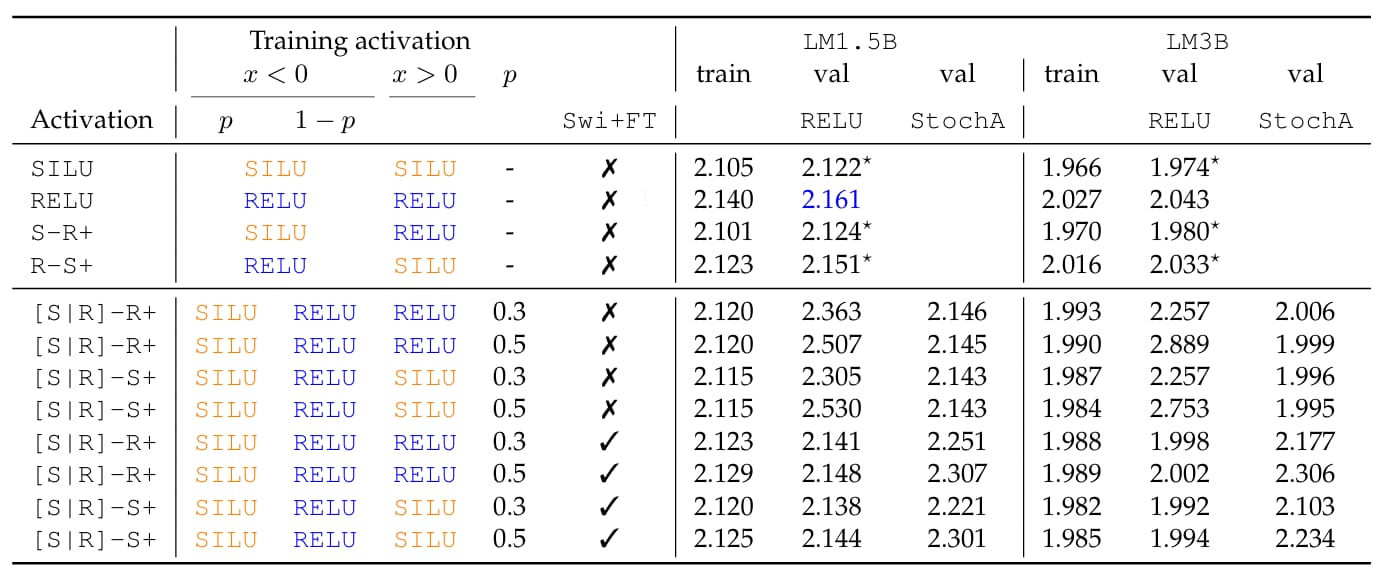
The authors combined this technique with a fine-tuning step called Swi+FT to prepare the model for efficient inference. Here, the model is first pre-trained mostly with SILU or a stochastic mix, and then, for the last 5–10% of training steps, it switches entirely to ReLU.
This final tuning phase adapts the weights to ReLU’s behavior, so the model performs well when ReLU is used at inference time.
Losses during the last 500 steps of the training loss of LM1.
Evaluation and Results of Stochastic Activations
The researchers tested this method on models with 1.5 billion and 3 billion parameters, and evaluated it on a range of tasks, including code generation, common-sense reasoning, and question answering.
When using ReLU at inference time, models trained with stochastic activations and fine-tuning (Swi+FT) achieved validation losses close to those of SILU-trained models, and significantly better than models trained with ReLU alone.
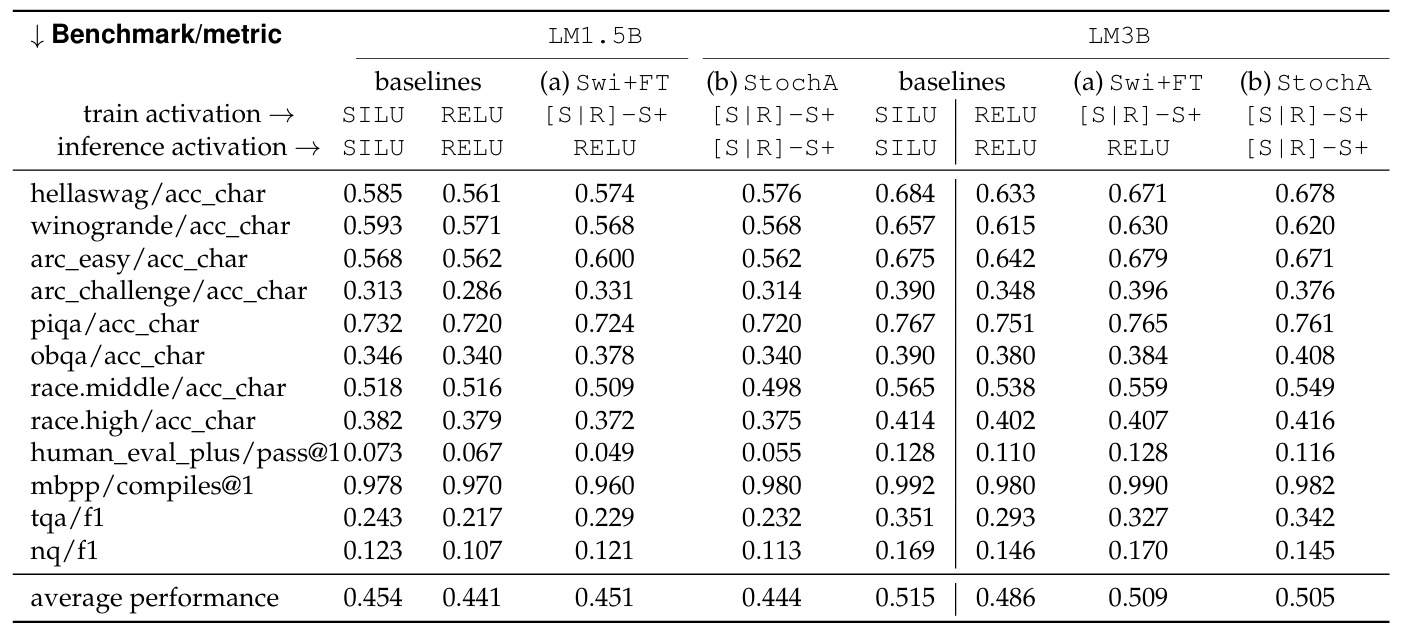
Performance per benchmark of the RELU and SILU.
It was able to produce 1.65 times faster inference on a CPU, with around 90% of activation outputs being zero. This shows that the approach successfully balances accuracy and computational cost. Additionally, when stochastic activations were used directly during inference for text generation, they provided a way to sample diverse outputs. In some tasks, this stochastic generation outperformed standard temperature sampling, though results varied across benchmarks.
Polychromic Objectives for Reinforcement Learning
Hamid et al. [Stanford University]
♥ 424 LLM Reinforcement Learning bycloud’s pick
Introduction to Polychromic Objectives in RLFT
Reinforcement learning fine-tuning is a powerful technique for tuning pretrained AI models, but it often comes with a hidden cost. As policies are refined for better performance, they can lose the rich diversity of behaviors they once had.
This entropy collapse makes it harder for models to explore new solutions and adapt to unfamiliar tasks. To tackle this issue, researchers have developed polychromic objectives, a new approach that explicitly encourages policies to maintain and refine a wide range of behaviors during fine-tuning.
Inner Workings of Polychromic PPO
This method shifts the focus from optimizing individual trajectories to evaluating entire sets of them. Instead of rewarding a single successful path, the policy is trained to generate groups of trajectories that collectively exhibit high performance and diversity. This broader perspective helps prevent the model from over-specializing on just a few high-reward actions.

This reinforcement learning approach uses the polychromic objective, which scores a set based on both the average reward of its trajectories and a measure of their diversity. For example, in grid-world tasks, diversity might be defined by whether trajectories visit different rooms, while in algorithmic tasks, it could involve generating unique sequences. By combining these elements, the objective ensures that policies are incentivized to explore varied strategies without sacrificing success.
To implement this in practice, the researchers adapted proximal policy optimization (PPO) into polychromic PPO. They use vine sampling to collect multiple rollouts from key states during training, and then compute a shared advantage signal for all trajectories in a set. This means that every action in a diverse and successful set receives the same positive update, reinforcing the policy to produce such sets consistently. The result is a fine-tuning process that naturally balances exploitation of known good behaviors with exploration of new ones.
Evaluation and Results of Polychromic PPO
The researchers tested this approach on BabyAI, Minigrid, and Algorithmic Creativity tasks, and the results show that polychromic PPO achieves higher success rates and better coverage of different environment configurations compared to standard RL methods. In pass@k evaluations, where models get multiple attempts to solve a task, polychromic PPO shows substantially improved performance as k increases. In challenging tasks like Bosslevel, it achieved up to 15% higher pass rates with more attempts, while baselines plateaued early.

Average reward and success rate (%) on BabyAI tasks.
While there is a slight trade-off in some validity metrics, the overall gains in creativity and coverage make polychromic objectives a promising direction for future AI systems that need to explore and innovate.
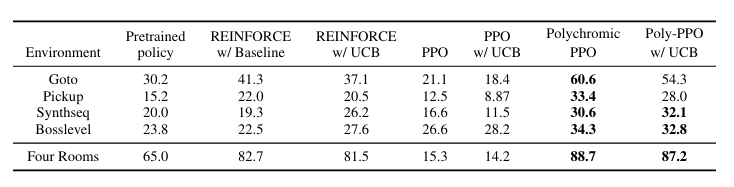
Average pass rate (%) in one attempt on BabyAI tasks under large initial-state perturbations.
Reply