- The AI Timeline
- Posts
- RL's Razor: Why Online Reinforcement Learning Forgets Less
RL's Razor: Why Online Reinforcement Learning Forgets Less
Plus more about Small Language Models are the Future of Agentic AI and Why Do MLLMs Struggle with Spatial Understanding?
by cloud
September 09, 2025
Sep 2nd ~ Sep 9th
#72 Latest AI Research Explained Simply
🗞️ Industry News in 1 Line
♥ 1.2k After Vibe Coding, we are now seeing a rise in voice-first development as tools like Flow and Lovable are gaining attention. Flow is enhancing its IDE integration with voice-activated file tagging and syntax-aware variable recognition. At the same time, Lovable has launched a new "Voice Mode" that builds projects entirely from spoken commands.

♥ 3.8k Alibaba has launched Qwen3-Max-Preview, which is a huge model with over one trillion parameters. Early benchmarks and user feedback show that it delivers stronger performance, broader knowledge, and superior capabilities in agentic tasks and instruction following compared to its predecessors. You can experience Qwen3-Max-Preview for yourself on Qwen Chat or via the Alibaba Cloud API.

Qwen3-Max-Preview Benchmarks
♥ 4.1k Higgsfield AI has launched the Ads 2.0 model, which is designed to create million-dollar quality commercials. The new version can produce a wide range of sophisticated scenes, from dynamic "bullet time" effects and crisp pack shots to full-scale product advertisements. You can view generated samples on Twitter or start creating professional-grade ads by trying Higgsfield Ads 2.0 in your browser.

Support My Newsletter
As I aim to keep this newsletter free forever, your support means a lot. If you like reading The AI Timeline, consider forwarding it to another research enthusiast, It helps us keep this up for free!
Why Do MLLMs Struggle with Spatial Understanding? A Systematic Analysis from Data to Architecture
Zhang et al. [Chinese Academy of Sciences, University of Chinese Academy of Sciences, Tsinghua University, Harbin Institute of Technology, Wuhan AI Research, Institute of Microelectronics of the Chinese Academy of Sciences]
♥ 485 Spatial Understanding
Introduction to Spatial Understanding in MLLMs
Spatial understanding is necessary to interpret and reason about the physical world in tasks like navigation or object interaction. However, current models don’t work well with complex spatial scenarios, especially those involving multiple viewpoints or moving images. This paper introduces a new benchmark called MulSeT, which offers a systematic way to evaluate these limitations across three settings: single images, multiple views, and videos.

MulSeT benchmark for Spatial Understanding of LLMs
Inner Workings of Spatial Reasoning in MLLMs
From a data perspective, the performance plateaus as training examples increase. Tasks that require spatial imagination, like imagining an object’s position from a different angle, show especially low ceilings, which suggests that MLLMs lack intuitive spatial reasoning.
Using ablation tests, the authors showed that disrupting positional cues in the vision encoder causes a major drop in spatial performance. At the same time, similar changes in the language module have less effect. This indicates that spatial understanding depends heavily on how the model “sees” and structures visual information, not just how it describes it.

Interestingly, not all models handle spatial information the same way. Cascaded architectures, where vision and language components are separate, rely more on the vision encoder’s positional data than native end-to-end models. This means improving spatial reasoning may require redesigning how visual position is embedded and used throughout the model.

MulSeT Benchmark Overview
Evaluation and Future Directions for Spatial Understanding
The tests show that MLLMs perform well on single-view tasks, and they nearly match human ability, but struggle significantly with multi-view and video-based spatial questions. For example, in azimuth transfer tasks, which require imagining directions from different viewpoints, model performance remains low even after fine-tuning.

Benchmark Results on MulSeT
RL's Razor: Why Online Reinforcement Learning Forgets Less
Shenfeld et al. [Improbable AI Lab at MIT]
♥ 22k Reinforcement Learning
Introduction to RL's Razor and Catastrophic Forgetting
When we fine-tune large AI models on new tasks, we often face a frustrating problem: the model gets better at the new skill but forgets some of what it knew before. This phenomenon is known as catastrophic forgetting.
This paper compares two common fine-tuning methods: supervised fine-tuning (SFT) and reinforcement learning (RL). It shows that, even when both methods achieve similar performance on a new task, RL preserves prior knowledge much better than SFT.
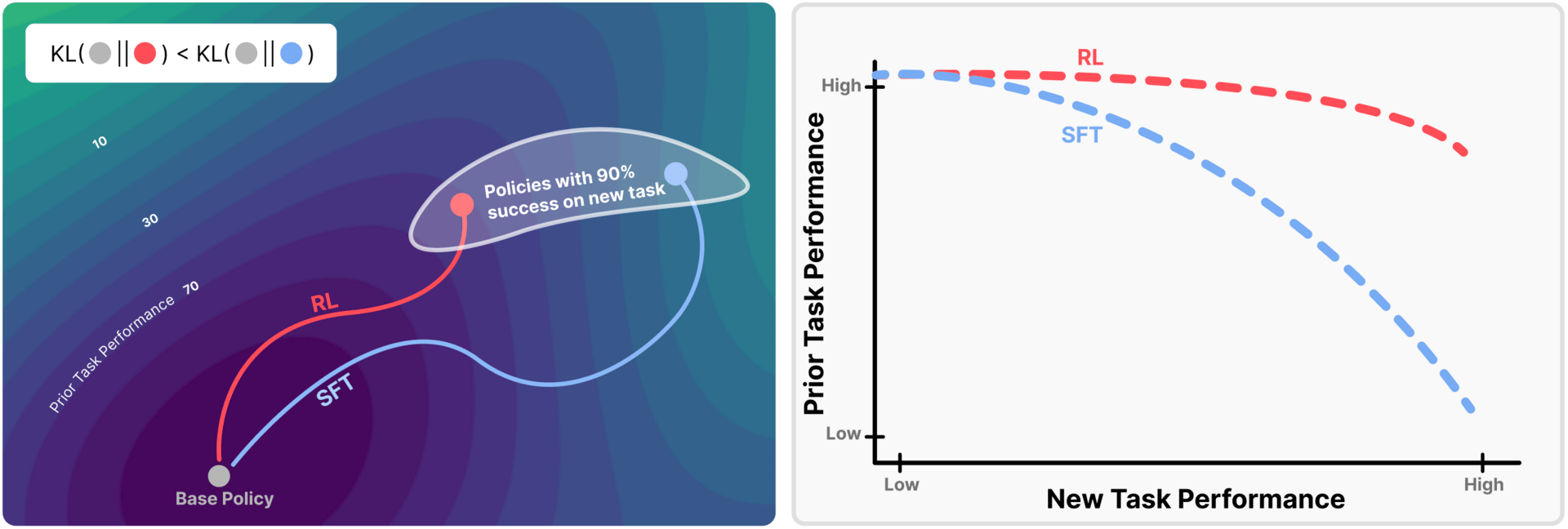
How RL Minimizes Knowledge Loss
The difference between SFT and RL comes down to how they update the model. In SFT, the model is trained on a fixed set of labeled examples, which can push it toward a new distribution that might be very different from its original behavior.
On the other hand, RL uses an on-policy approach: it samples responses from its current policy and updates based on which lead to good outcomes. This means RL naturally stays closer to its starting point.

Reinforcement Learning Forgets Less than SFT
This behavior is captured by a concept called KL divergence, which measures how much two probability distributions differ. The paper shows that the degree of forgetting is directly related to the KL divergence between the fine-tuned model and the base model when evaluated on the new task.
Because RL samples from its own distribution during training, it is biased toward solutions with low KL divergence from the original model. The authors call this principle "RL’s Razor": out of all ways to solve a new task, RL prefers those closest to the original model.
To validate this, the researchers constructed an "oracle" SFT distribution that explicitly minimizes KL divergence. When trained on this ideal distribution, SFT actually outperformed RL in preserving prior knowledge. This confirms that it’s not the algorithm itself, but the KL-minimal behavior that reduces forgetting. The advantage of RL is that it implicitly encourages this behavior through its on-policy updates.

On-policy methods leads to smaller KL divergence
Evaluation and Implications of RL’s Razor
The researchers performed experiments across multiple domains, including math reasoning, science Q&A, tool use, and robotics. It showed that RL fine-tuning maintains prior task performance much better than SFT for the same level of new-task accuracy. For example, in math tasks, SFT suffered sharp drops in prior capabilities even with small gains on the new task, while RL kept prior performance nearly unchanged.

These findings suggest that KL divergence on the new task is a reliable predictor of catastrophic forgetting, independent of the fine-tuning method. This has practical implications: instead of focusing solely on reward or accuracy, training methods should aim to minimize distributional shift from the base model.

Small Language Models are the Future of Agentic AI
Belcak et al. [NVIDIA Research, Georgia Institute of Technology]
♥ 424 Small LLMs bycloud’s pick

Introduction to the Rise of Small Language Models in Agentic AI
Businesses are increasingly relying on AI agents to handle specialized and repetitive tasks. Although most AI agents used LLMs to power these systems, many people are now turning to small language models (SLMs), which might actually be better suited for many agentic applications. This paper argues that by adopting SLMs, we can make agentic systems more economical, flexible, and scalable.
Inner Workings and Mechanisms of Small Language Models
SLMs operate on the same foundational principles as LLMs but are optimized for narrow, well-defined tasks. Their smaller parameter count (below 10 billion) allows them to be fine-tuned more easily and deployed on consumer-grade hardware. This makes them ideal for agentic systems, where tasks like tool calling, code generation, and structured output formatting are repetitive and require strict consistency.
For example, an SLM can be trained to generate JSON responses for API calls or follow specific dialogue patterns, reducing the risk of formatting errors that could disrupt an agent’s workflow.
The architecture of agentic systems naturally supports the use of multiple specialized models. Instead of relying on a single general-purpose LLM, an agent can invoke different SLMs for different subtasks. This modular approach not only improves performance but also allows for greater customization.
Fine-tuning techniques like LoRA and QLoRA make it cost-effective to adapt SLMs to new tasks quickly, which enables rapid iteration and deployment. Additionally, SLMs' compact size means they can run efficiently on edge devices, offering low-latency responses without depending on cloud infrastructure.

Evaluation and Benchmark Performance of SLMs in Agentic Systems
Experimental results strongly support the effectiveness of SLMs in agentic applications. Models like Phi-3 (7B), NVIDIA Nemotron (2–9B), and DeepSeek-R1-Distill (1.5–8B) demonstrate performance comparable to much larger LLMs on tasks such as commonsense reasoning, tool calling, and instruction following. For example, Phi-3 matches the capabilities of 70B parameter models while running up to 15 times faster, highlighting the efficiency gains possible with SLMs.
Additionally, deploying a 7B parameter SLM can be 10–30 times cheaper than using a 70B–175B LLM, considering factors like latency, energy consumption, and computational overhead. These savings become especially significant at scale, where agentic systems often handle millions of repetitive invocations.
Reply