- The AI Timeline
- Posts
- Yet Another DeepSeek Architectural Research: Engram
Yet Another DeepSeek Architectural Research: Engram
plus more on DroPE: Dropping RoPE, STEM, and Dr. Zero
by cloud
January 21, 2026
Jan 13th ~ Jan 19th
#91 Latest AI Research Explained Simply
🗞️ Industry News in 1 Line
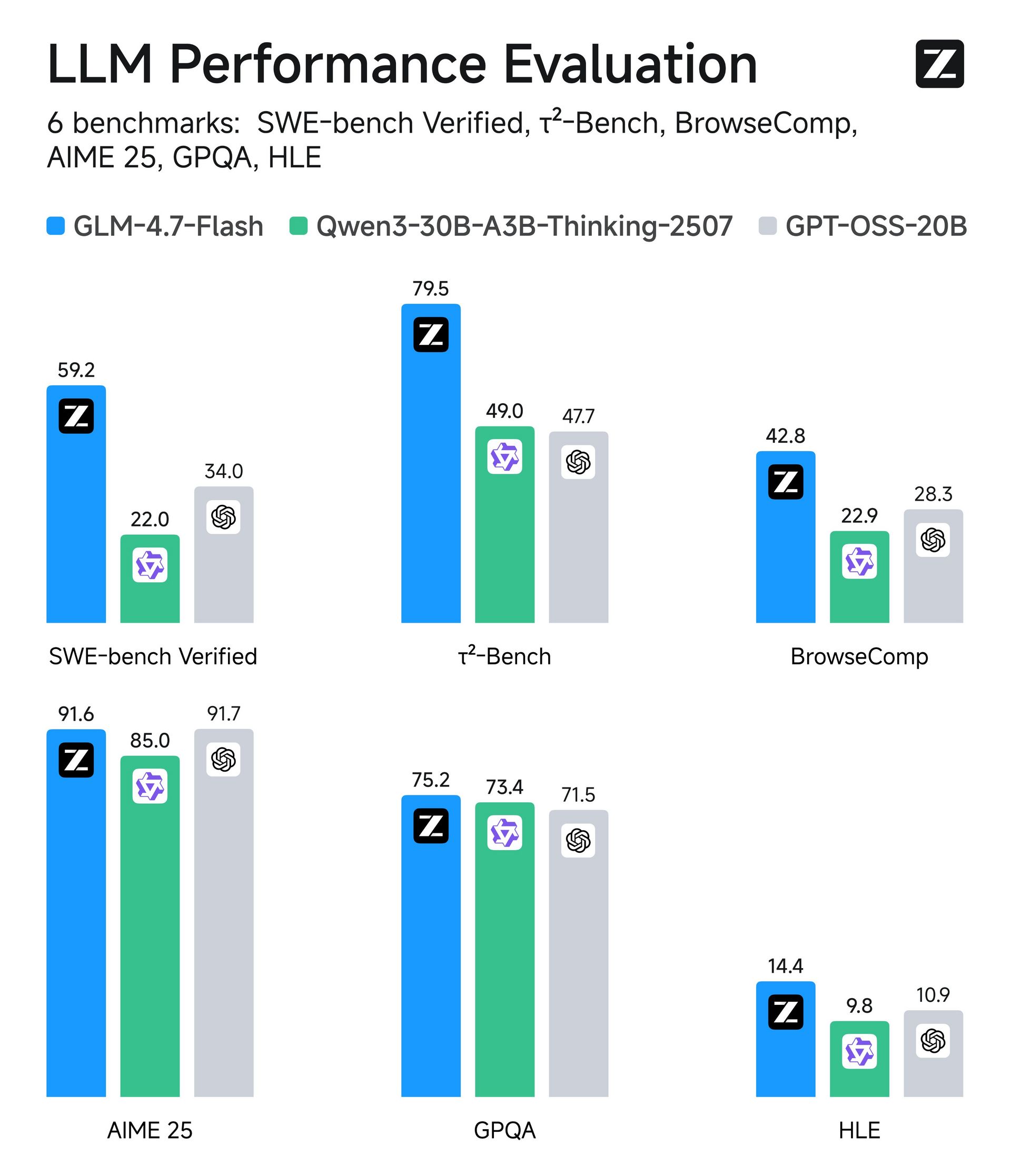
♥ 5.9k Z.ai has released GLM-4.7-Flash, a lightweight ~30B-class local model aimed at coding and agentic workflows, with support for long-context writing, translation, and roleplay. Weights are available on Hugging Face, and the API includes a free GLM-4.7-Flash tier (1 concurrency) plus a faster GLM-4.7-FlashX option.
♥ 9.5k OpenAI says it will begin testing ads in ChatGPT in the coming weeks for logged-in adults on the Free and Go tiers in the U.S., with ads clearly separated and labeled and responses not influenced by advertising. OpenAI also says chats won’t be shared or sold to advertisers, and Pro, Business, and Enterprise tiers will remain ad-free
♥ 6.9k Google has introduced Personal Intelligence inside Gemini App, an opt-in beta that lets it securely connect your Gmail, Photos, Search, and YouTube history to deliver more personalized help.
♥ 7.4k Google DeepMind has released TranslateGemma, a new family of open translation models built on Gemma 3 with 55-language support in 4B, 12B, and 27B sizes. It’s designed for efficient, low-latency translation (including text-in-image) and is available on Hugging Face and Kaggle.

Learn LLMs Intuitively - Intuitive AI Academy
Want to learn about LLMs, but never have a good place to start?
Intuitive AI Academy has the perfect starting point for you! We focus on building your intuition to understand LLMs, from transformer components, to post-training logic. All in one place.
This is my latest project, and we will include write-up accompanying my latest videos on the frontier of AI research, all to help you keep up without the hassle of digging through papers and understanding math.

content overview (a total of 100k words explainer so far!)
We currently have a New Year New Me launch offer, where you would get 50% off yearly plan FOREVER for our early users. Use code: 2026
Extending the Context of Pretrained LLMs by Dropping Their Positional Embeddings
Gelberg et al. [Sakana AI, University of Oxford]
♥ 1.7k Positional Embeddings
Teaching LLMs to process long documents is often very costly. Models are trained on shorter snippets of text to save computing power. But when they are asked to handle longer sequences, like analyzing a whole book instead of a chapter, they struggle because they rely on specific "positional embeddings" (mathematical tags that mark the order of words). Until now, fixing this required an expensive second phase of training to retune the model for longer contexts.
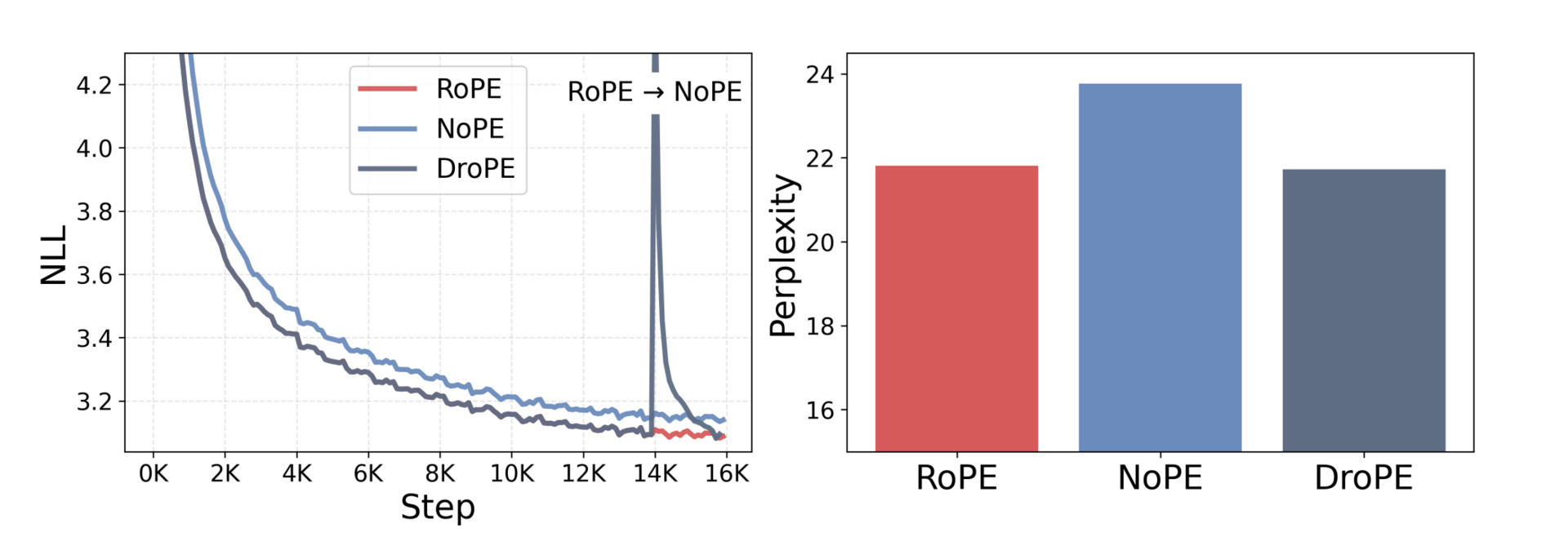
DroPE matches RoPE’s in-context perplexity.
This paper made a counterintuitive discovery that the tools used to help models learn word order are actually holding them back. The team found that while positional embeddings act as a guide during the initial learning process, they become a hindrance later on, which prevents the model from generalizing to lengths it hasn't seen before.
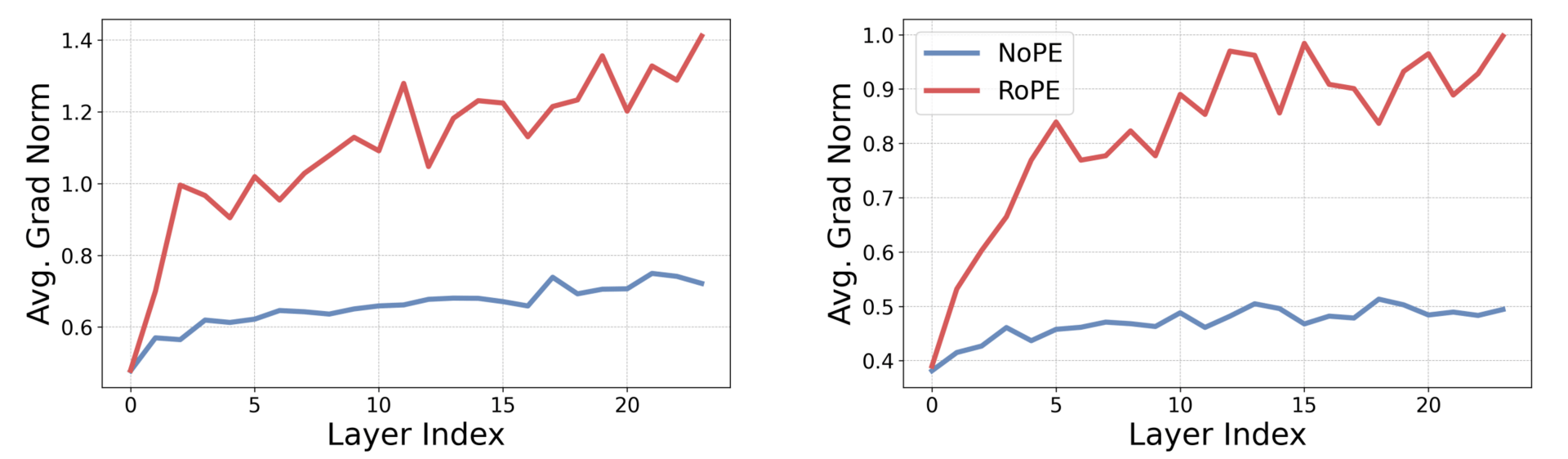
RoPE transformers have higher positional bias gradients at initialization.
By simply removing these embeddings after the initial training (a method they call DroPE), the model acts more flexibly. Surprisingly, once these rigid guides were removed and the model underwent a very brief recalibration, it could immediately understand and retrieve information from sequences far longer than anything it had seen before. This method effectively unlocks long-context capabilities without compromising the model’s performance on standard tasks.
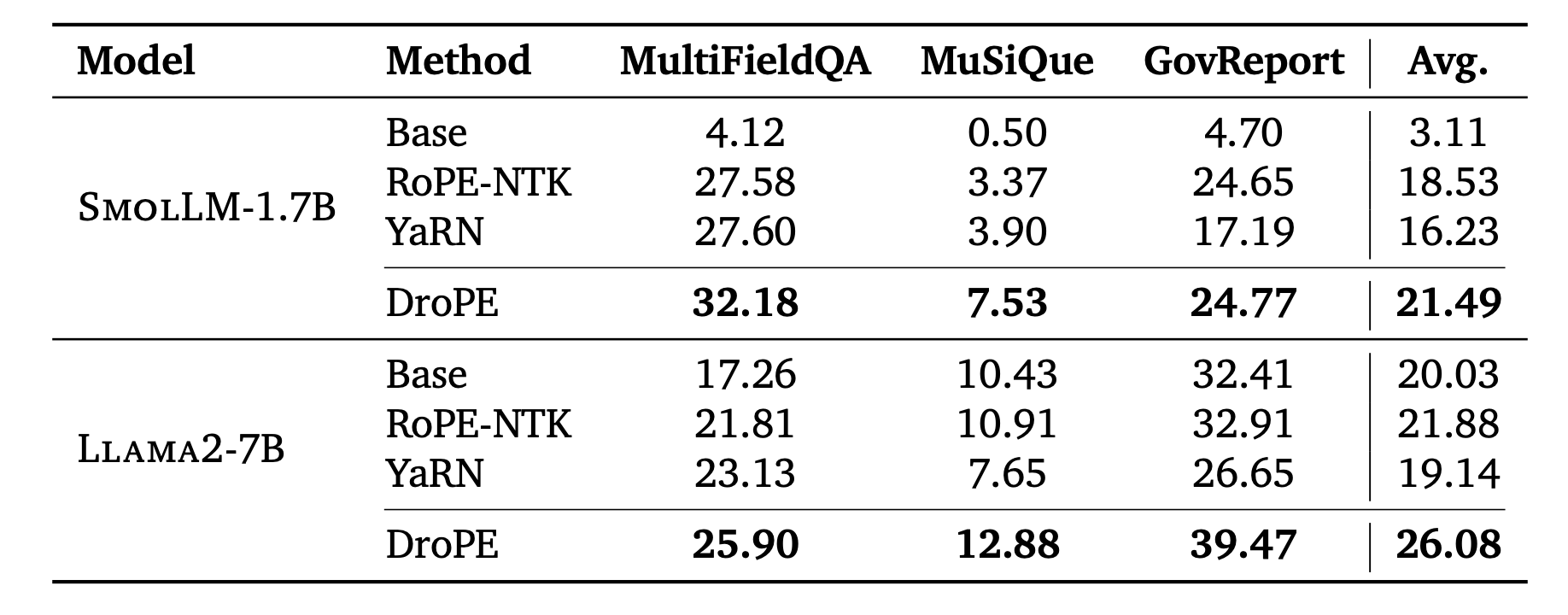
Length generalization results on larger models.
By proving that complex fine-tuning isn't always necessary to upgrade a model's memory, this approach opens the door to systems that can digest vast amounts of information (from entire codebases to legal archives) at a fraction of the current cost.
STEM: Scaling Transformers with Embedding Modules
Sadhukhan et al. [Carnegie Mellon University, Meta AI]
♥ 257 Transformers
When we need a smarter LLM, we often try to get a bigger model, which makes them slow and expensive to run. To solve this problem, researchers are trying to build sparse models by teaching the model to activate only a small fraction of its "brain" for any given task.
However, current methods for doing this are notoriously fickle. They often suffer from training instability and create complex communication bottlenecks between computer chips, all while making the model’s decision-making process harder for humans to interpret.
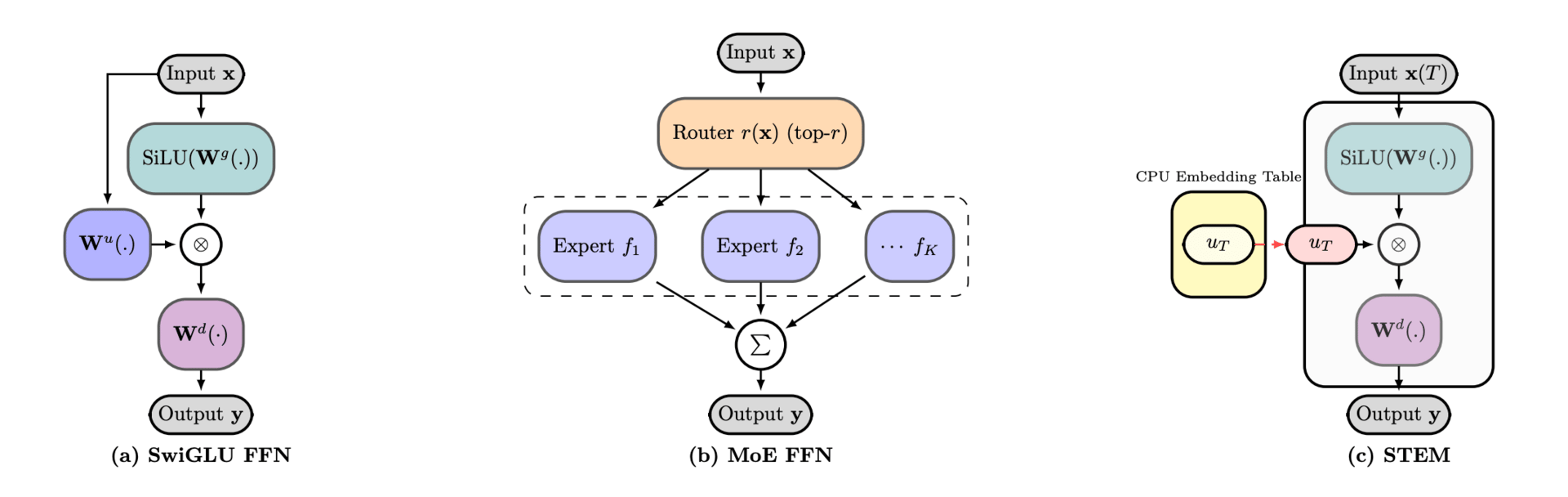
Schematics of (a) SwiGLU FFN, (b) MoE FFN, and (c) STEM with a single prefetched token embedding.
The team developed a new architecture called STEM (Scaling Transformers with Embedding Modules) that simplifies how models process information. Instead of forcing every piece of data through the same complex mathematical transformations, the system uses a static, specialized approach.
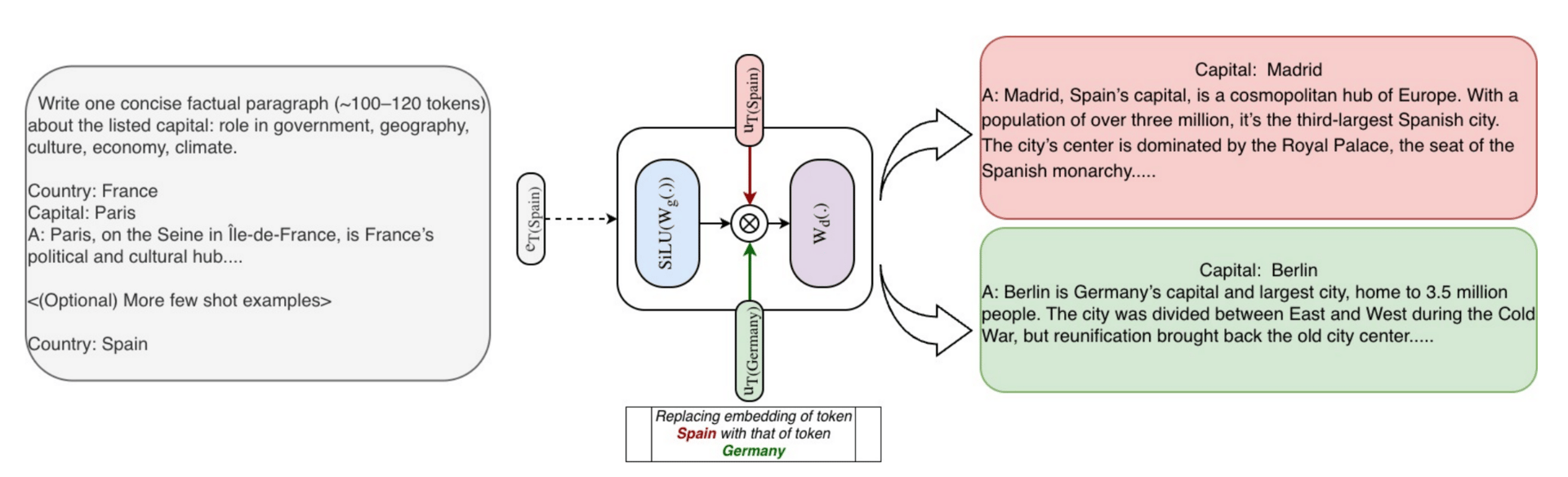
Knowledge injection/edit demonstration.
By replacing a computationally heavy slice of the network with a simple, dedicated lookup table for each specific word, they successfully decoupled the model's storage capacity from its processing cost. This approach proved remarkably stable, effectively removing about one-third of the usual parameters required for these calculations while actually improving accuracy on knowledge-heavy tasks.
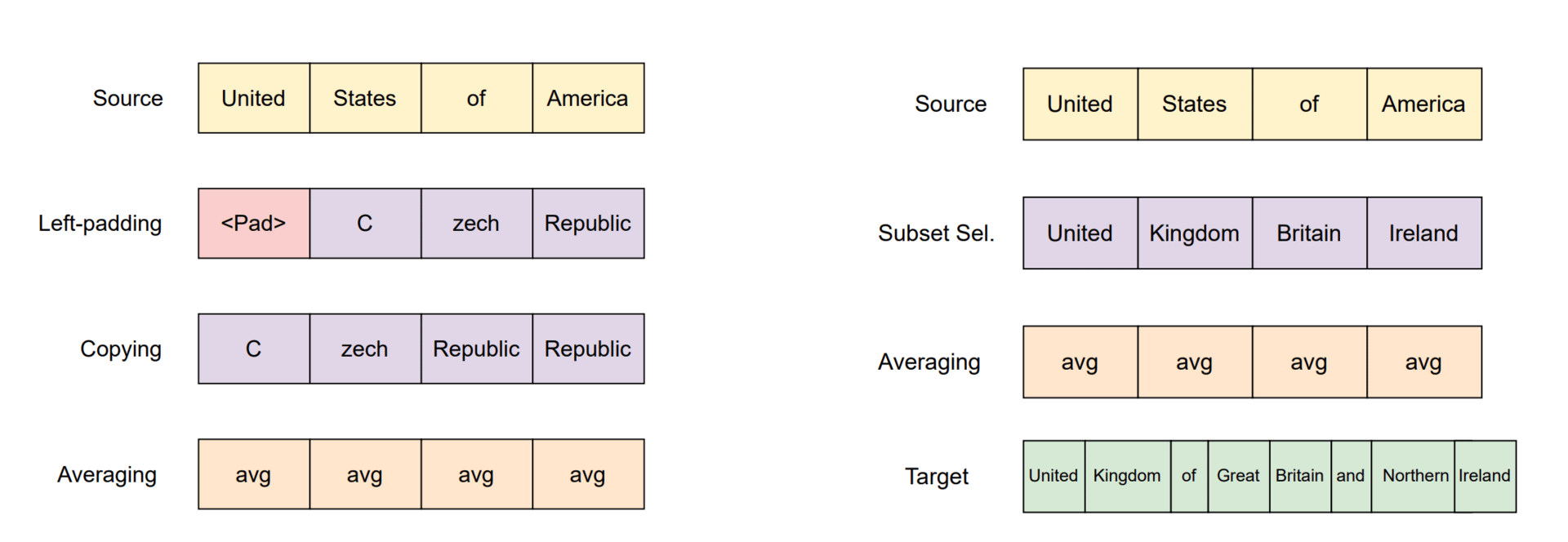
STEM-based knowledge editing schemes for length-mismatched source (ns) and target (nt) entity tokenizations.
Because this information is organized by specific tokens rather than hidden inside a "black box" of varying experts, the model became much more interpretable. The researchers found they could even "edit" the model's knowledge in a transparent way without retraining the entire system.
Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
Cheng et al. [Peking University, DeepSeek-AI]
♥ 2.8k LLM Memory bycloud’s pick
LLMs are getting better at complex reasoning, but they don’t have a built-in mechanism to simply "remember" fixed information. To recall a common phrase, a specific name, or a formulaic pattern, a standard Transformer model must spend valuable processing power computing the answer from scratch, effectively "thinking" its way to a memory every single time.
What if we gave the model a dedicated, instantly accessible memory bank for static facts, allowing its neural circuitry to focus entirely on difficult problem-solving? This approach acknowledges that language consists of two distinct parts (creative composition and rote knowledge) and suggests that our AI architectures should reflect that duality.
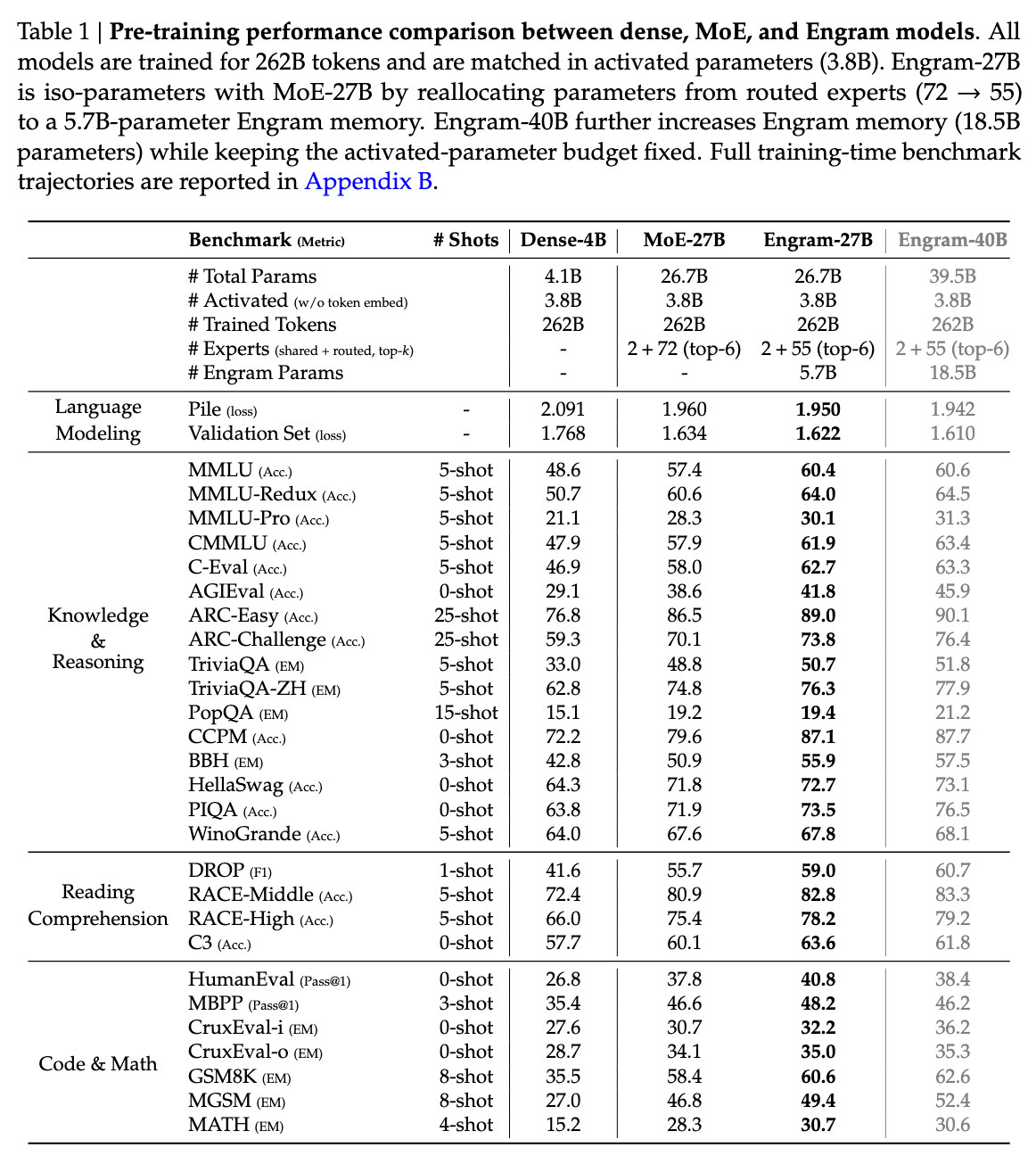
The team introduced "Engram," a sophisticated memory module that modernizes classic text-analysis techniques to function as a high-speed lookup table for the model. By analyzing how to balance this new memory system with traditional computation, they discovered a distinct "U-shaped" scaling law, pinpointing the optimal ratio between processing power and static memory.
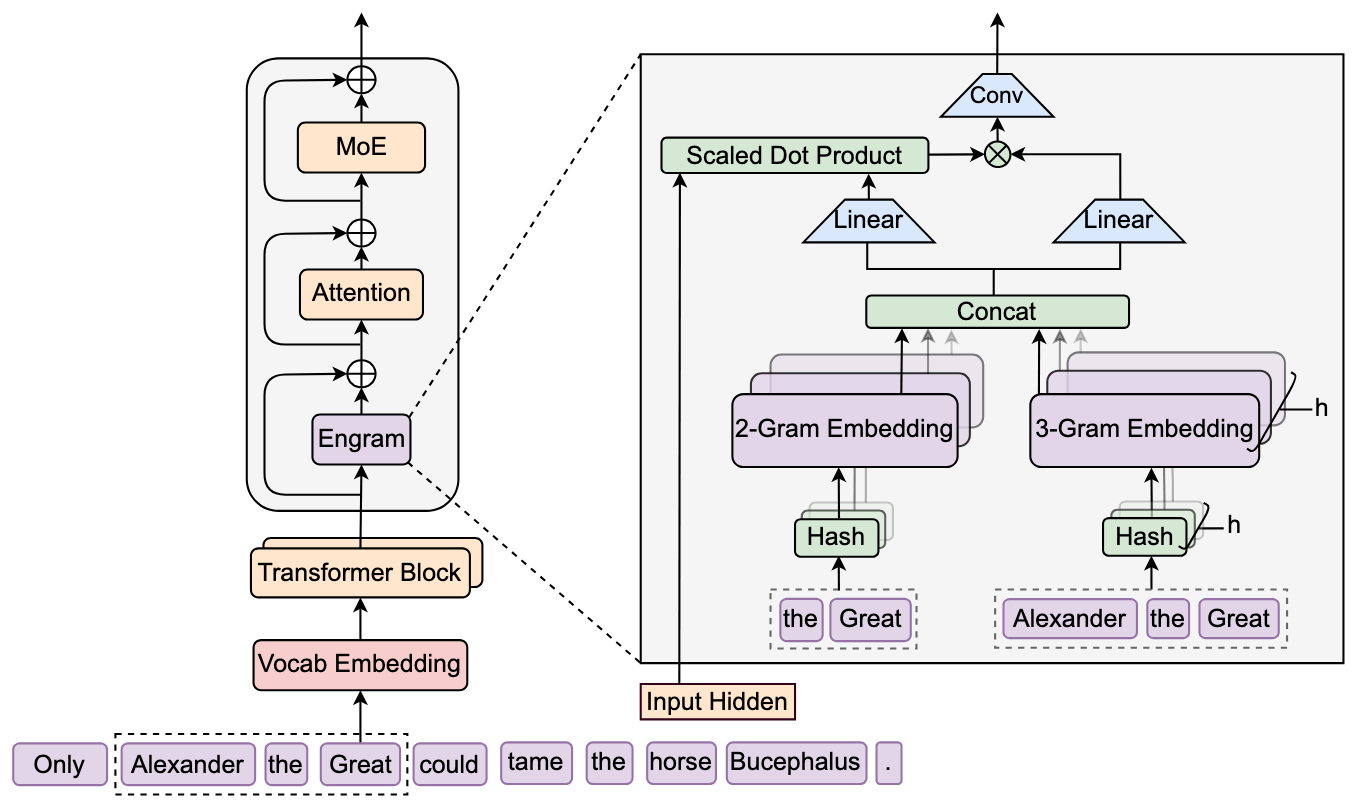
When they built a large-scale model using these principles, the results were counterintuitive. While the system predictably improved at factual retrieval, it saw even larger gains in complex reasoning, mathematics, and coding. The researchers found that by offloading the "easy" work of recognizing local patterns to the Engram module, the model’s deeper layers were relieved of the burden of reconstruction.

This effectively freed up the network's attention mechanisms to process global context and tackle much harder cognitive tasks, leading to superior performance without increasing the computational budget.
Dr. Zero: Self-Evolving Search Agents without Training Data
Yue et al. [Meta Superintelligence Labs, University of Illinois Urbana-Champaign]
♥ 426 LLM RL
Building bigger LLMs requires massive amounts of high-quality data curated by humans. But we are slowly running out of high-quality human data, particularly for complex tasks like researching the web to answer open-ended questions.
While AI has successfully taught itself to solve math problems or play chess (domains with clear rules), teaching a machine to navigate the messy, unstructured internet without human supervision has proven far more difficult.
Researchers at the University of Illinois Urbana-Champaign and Meta set out to solve this puzzle, asking if an AI could essentially pull itself up by its bootstraps to become a better researcher without seeing a single human example.
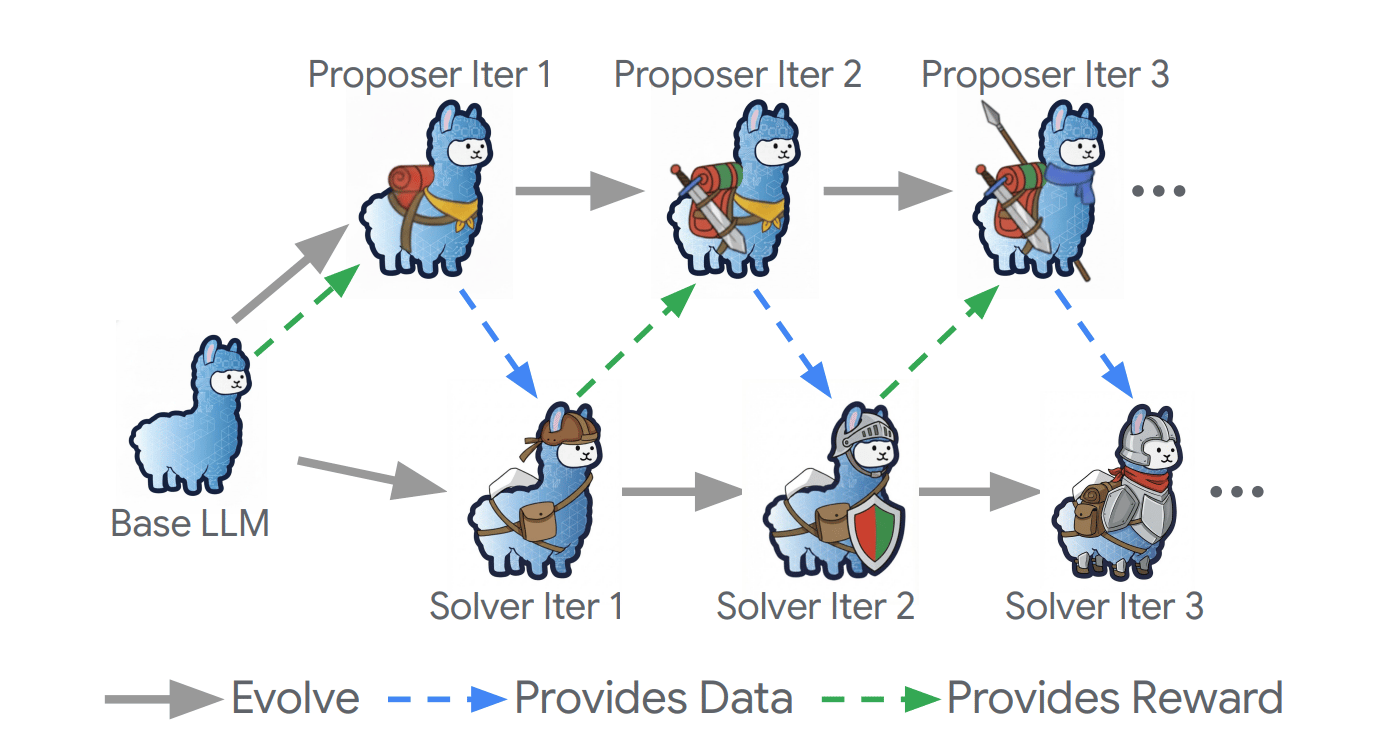
The self-evolving LLM training framework (Huang et al., 2025a) that iteratively trains a proposer and a solver with minimal supervision.
The team developed a framework called Dr. Zero, which creates a symbiotic relationship between two versions of the same artificial intelligence. They split the system into two distinct roles: a "Proposer" and a "Solver." The Proposer is tasked with inventing questions based on documents it finds, while the Solver uses a search engine to answer them.
The brilliance lies in how they learn from each other. The system uses a specialized feedback loop that rewards the Proposer only when it creates questions that are challenging but ultimately solvable. This creates an automated curriculum that gets progressively harder as the Solver gets smarter.
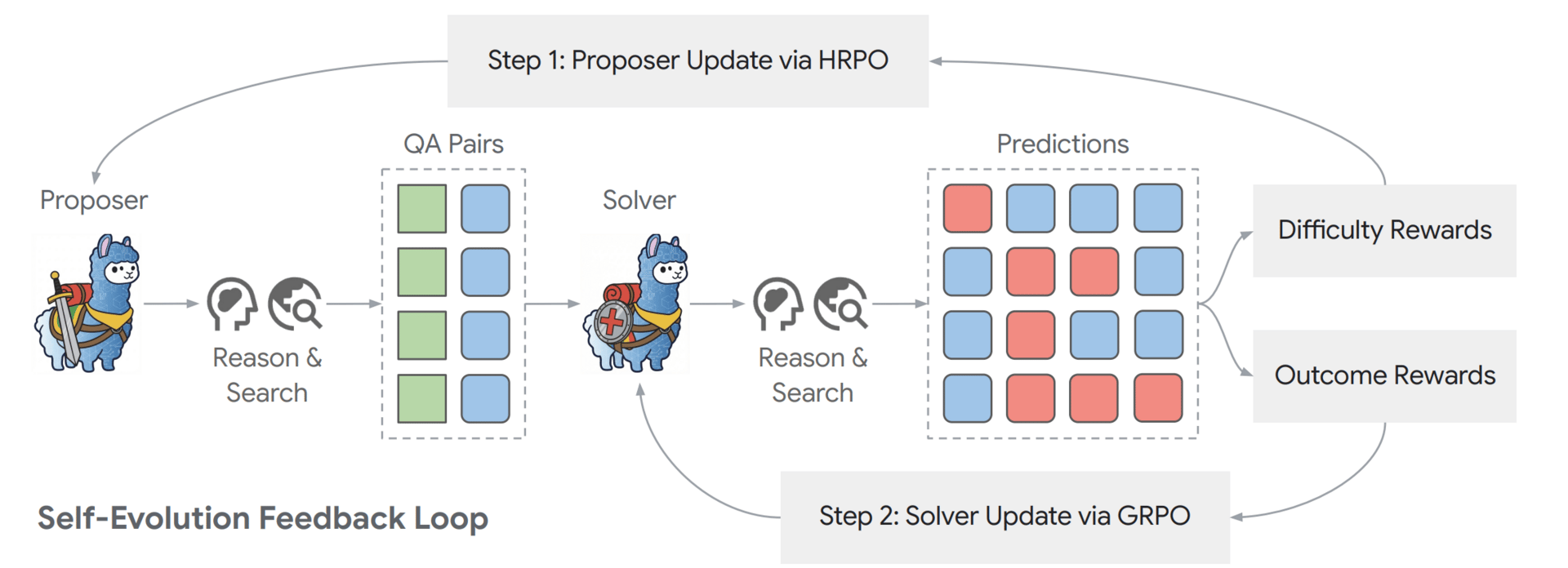
The Dr. Zero self-evolution feedback loop.
To make this computationally feasible, the team introduced a technique called Hop-Grouped Relative Policy Optimization (HRPO). This method cleverly groups similar questions to estimate their difficulty efficiently, allowing the model to learn complex, multi-step reasoning without requiring the massive computing power usually needed to test every possible outcome repeatedly.

System prompt for the proposer in Dr. Zero
The study revealed that this self-taught system often outperformed AI agents that were explicitly trained with human supervision. This suggests that complex reasoning and search capabilities can emerge naturally through self-evolution, without needing the expensive human datasets.
Reply