- The AI Timeline
- Posts
- Flash Attention Author's New Work: SonicMoE
Flash Attention Author's New Work: SonicMoE
Next-Embedding Prediction Makes Strong Vision Learners, Let's (not) just put things in Context, Spherical Equivariant Graph Transformers, and moree
by cloud
December 23, 2025
In partnership with
Dec 15th ~ Dec 22nd
#87 Latest AI Research Explained Simply
🗞️ Industry News in 1 Line
♥ 1.5k MiniMax has launched its M2.1 model, which is designed for complex, real-world tasks. In addition to coding, the model introduces powerful capabilities for office automation, enabling it to handle "digital employee" workflows and complex instructions. M2.1 is also more efficient, delivering faster, more concise responses that use fewer resources. You can access the M2.1 model now through the MiniMax API and as an open-source download on HuggingFace.

♥ 2.8k Z.ai has launched GLM-4.7, a new AI model that delivers significant improvements in coding and reasoning capabilities. This update introduces advanced features like "Preserved Thinking," which allows the model to retain its reasoning process across multiple steps, making it more stable and effective for complex, long-term tasks. Developers can access the model now through the Z.ai platform and OpenRouter, or download it for local use via HuggingFace.
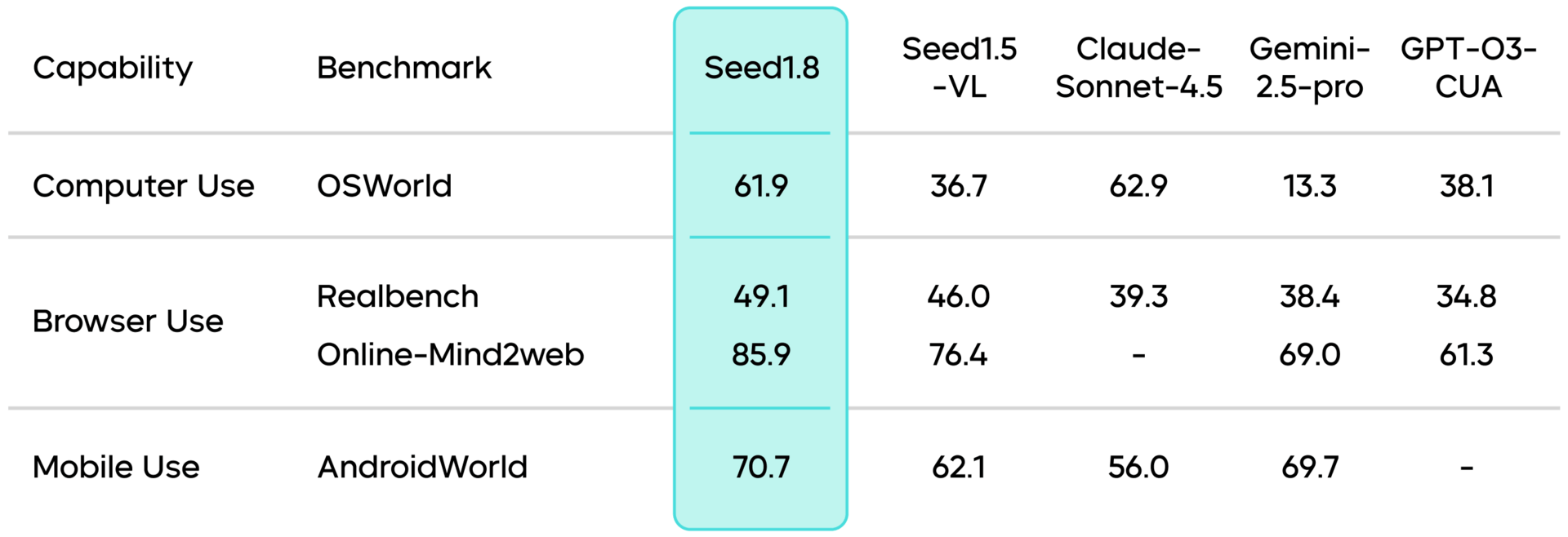
♥ 1.1k Bytedance has introduced Seed-1.8, a generalized agentic model designed to efficiently handle complex, real-world tasks. This new release excels in multimodal processing and it supports both text and image inputs with strong performance in Graphical User Interface (GUI) interaction, coding, and information retrieval. The model can perceive video streams in real-time, perform non-blocking interactions, and utilize specific video tools to analyze details or extract highlights from long-form content.
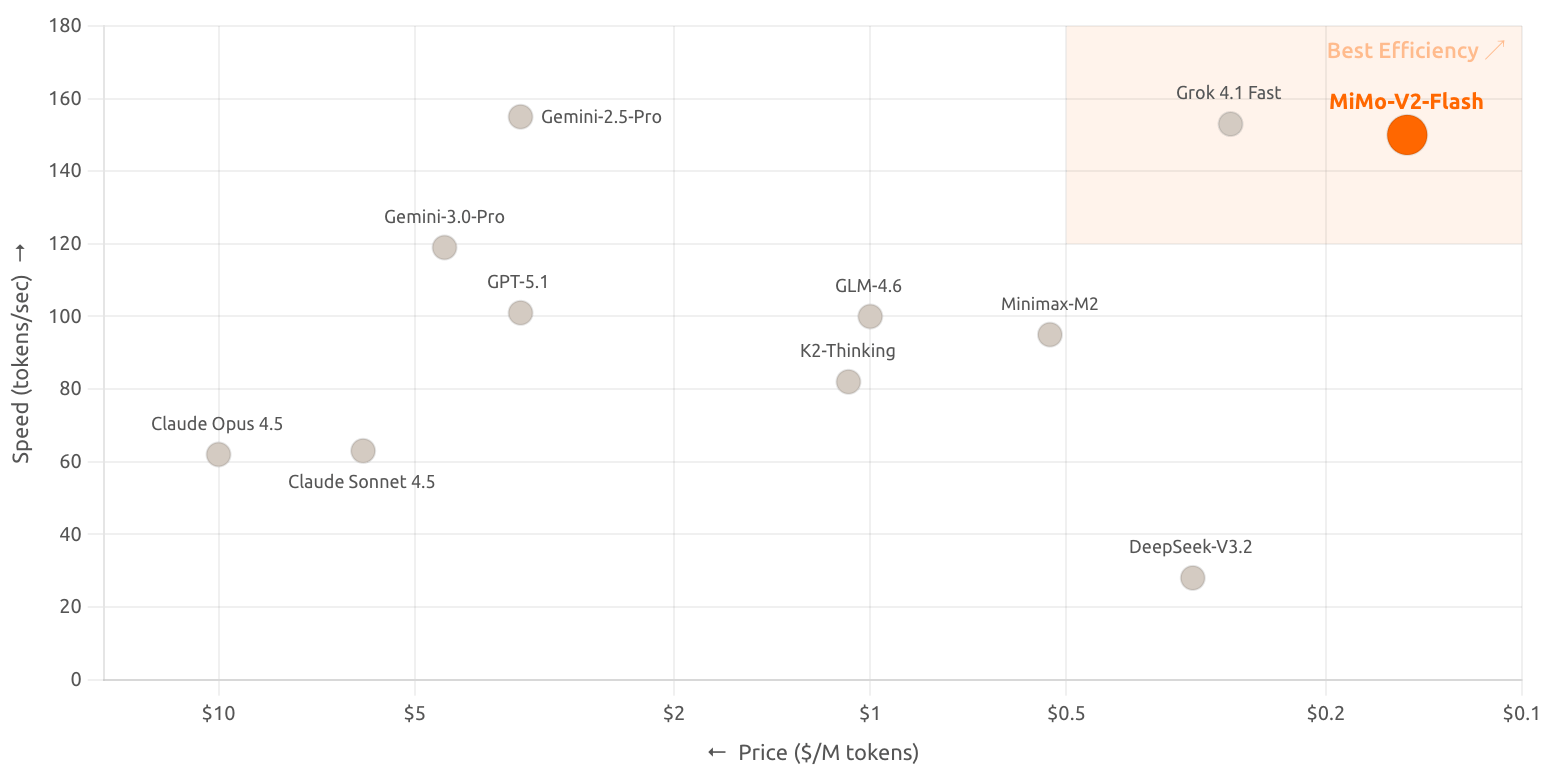
♥ 1.8k Xiaomi has released MiMo-V2-Flash, a new open-source AI model built for high-speed reasoning and coding tasks. This model uses a specialized "Mixture-of-Experts" architecture that delivers exceptionally fast responses (up to 150 tokens/s) while remaining highly cost-effective. With a massive context window capable of handling long documents and seamless integration with coding tools like Cursor and Claude Code, MiMo-V2-Flash is designed to act as an efficient digital assistant. You can access the model now through HuggingFace or Xiaomi's API platform.
Modernize your marketing with AdQuick

AdQuick unlocks the benefits of Out Of Home (OOH) advertising in a way no one else has. Approaching the problem with eyes to performance, created for marketers with the engineering excellence you’ve come to expect for the internet.
Marketers agree OOH is one of the best ways for building brand awareness, reaching new customers, and reinforcing your brand message. It’s just been difficult to scale. But with AdQuick, you can easily plan, deploy and measure campaigns just as easily as digital ads, making them a no-brainer to add to your team’s toolbox.
Let's (not) just put things in Context: Test-Time Training for Long-Context LLMs
Bansal et al. [Meta, Harvard University, Kempner Institute at Harvard, OpenAI, UC Berkeley, UT Austin]
♥ 444 LLM Context
AI models can theoretically process millions of words at once. However, there is a gap between what these models can read and what they can actually use. When you ask a model to find a specific "needle" in a massive "haystack" of text, it often fails, getting distracted by the sheer volume of information.

Until now, the industry standard solution has been to let the model "think" longer by generating more text before answering. But researchers have discovered that for truly long documents, simply generating more words doesn't help as the model’s internal attention mechanism gets overwhelmed.

This paper has identified a mathematical bottleneck called "score dilution". As a document gets longer, the "signal" of the correct answer gets drowned out by the "noise" of unrelated text. To fix this, they developed a technique called query-only test-time training (qTTT). Instead of asking the model to generate more text to solve a problem, this method allows the model to pause and perform a tiny, temporary update to its internal settings based specifically on the document it is reading.
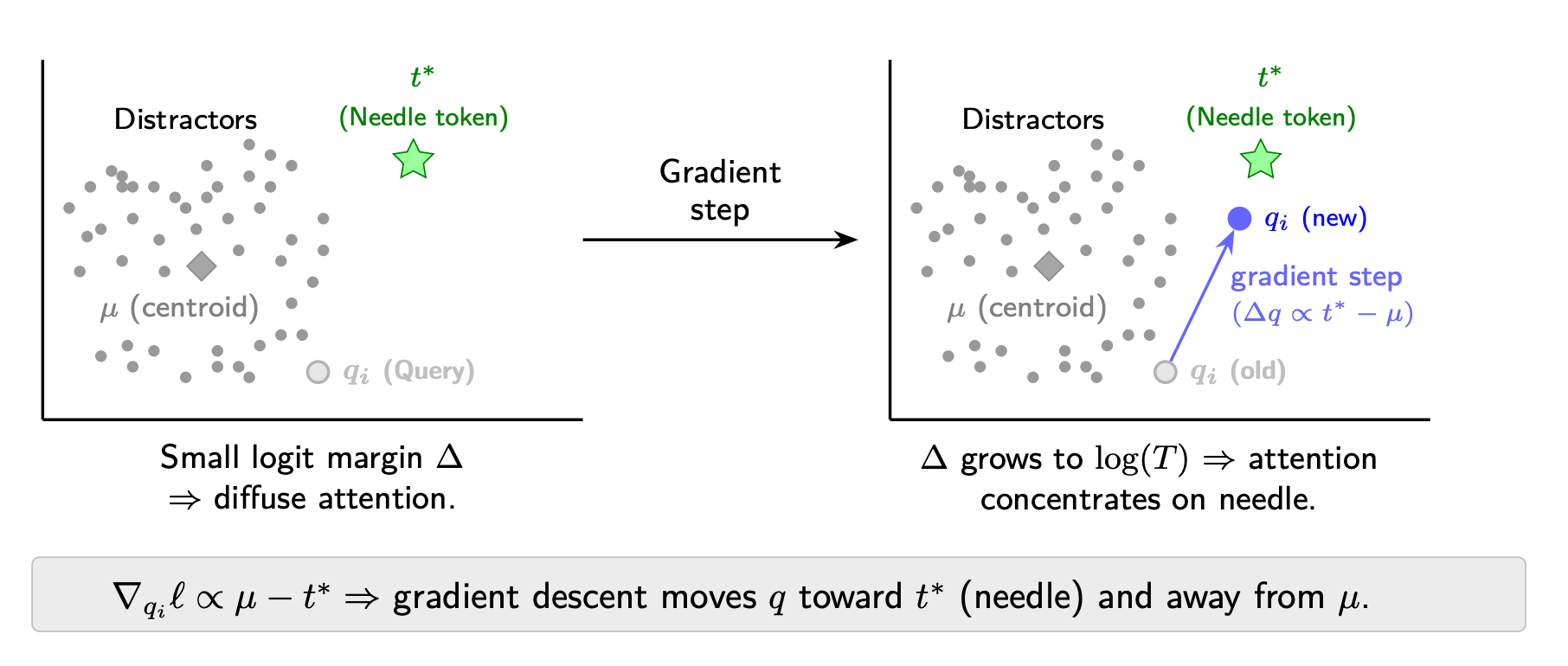
A visual representation of how qTTT improves the logit margin.
It effectively lets the model "study" the context for a moment before answering. This approach proved far more effective than standard methods, and provided massive double-digit improvements in accuracy on difficult tasks like finding bugs in code or details in long records.
A Complete Guide to Spherical Equivariant Graph Transformers
Sophia Tang [University of Pennsylvania]
♥ 876 Protein Generation bycloud’s pick
For a long time, teaching AI to navigate the 3D world of atoms and molecules was a challenge. The laws of physics remain constant regardless of which way a molecule is facing, but the standard ML models often struggle to recognize a structure simply because it has been rotated. To solve this, researchers have developed a Spherical Equivariant Graph Neural Network.
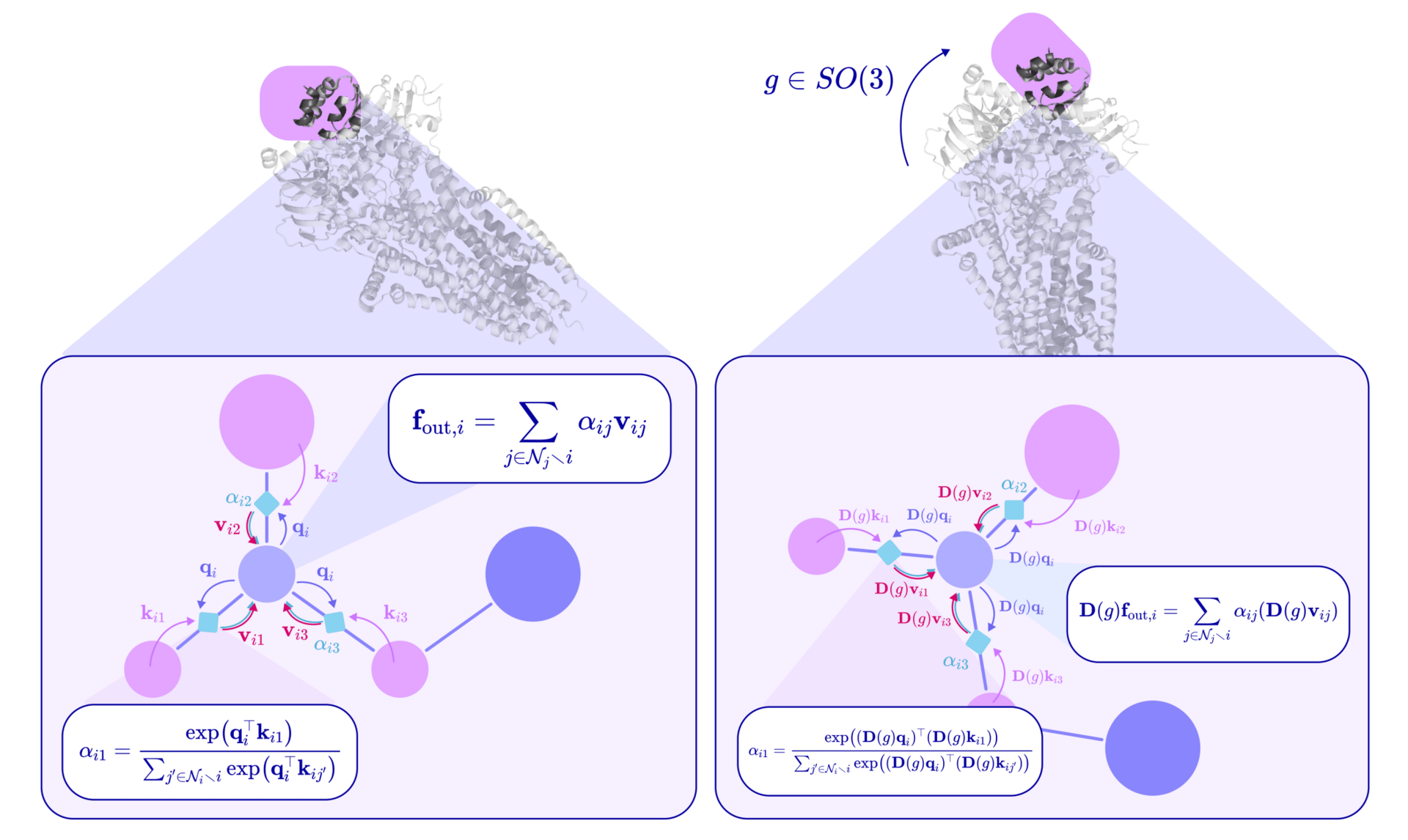
Rather than treating molecular features as static lists of numbers, this framework uses "spherical tensors", which is a mathematical concept taken from quantum mechanics. The researchers proved that by representing data this way, the model can perform "equivariant" message-passing. This means that if a molecule rotates in virtual space, the model's internal calculations transform in perfect synchronization, and it preserves the correct physical relationships between atoms.

A feature vector f is split into its type-0, type-1, and type-2 components and arranged into a feature tensor with a tensor axis, a channel axis, and a tensor-component axis.
By adding specific geometric tools like spherical harmonics and Clebsch-Gordan coefficients, the architecture guarantees that the AI respects the rotational symmetries of the physical world without needing to be retrained on every possible orientation of a protein or chemical compound.
New Premium Insights release
For context, Premium Insights is where I write down longer form content that I think is interesting but not long enough to be make into YouTube videos.
Last week, I published the following blog:
Aug~Nov AI Research Trend Report
Basically recapping what I missed in the last 4 months
I spent a lot of time on this quarterly(?) AI research trend report (~4000 words), so don’t miss out!
T5Gemma 2: Seeing, Reading, and Understanding Longer
Zhang et al. [Google DeepMind]
♥ 1.4k LLM
AI can generate text, but it can’t see images, process multiple languages, and remember long conversations without losing the thread. Recent models have focused on "decoder-only" models, but we still don’t have a lightweight model that can handle all these tasks simultaneously.

Summary of pretraining (top) and post-training (bottom) performance for Gemma 3 and T5Gemma 2 at 270M, 1B and 4B over five capabilities.
This paper introduces T5Gemma 2, which is a new family of models that successfully adapts the powerful Gemma 3 foundation into this specialized encoder-decoder structure. They utilized a clever "recipe" that initializes the new system using pre-existing technology. This teaches a text-generator to become a better reader and observer.
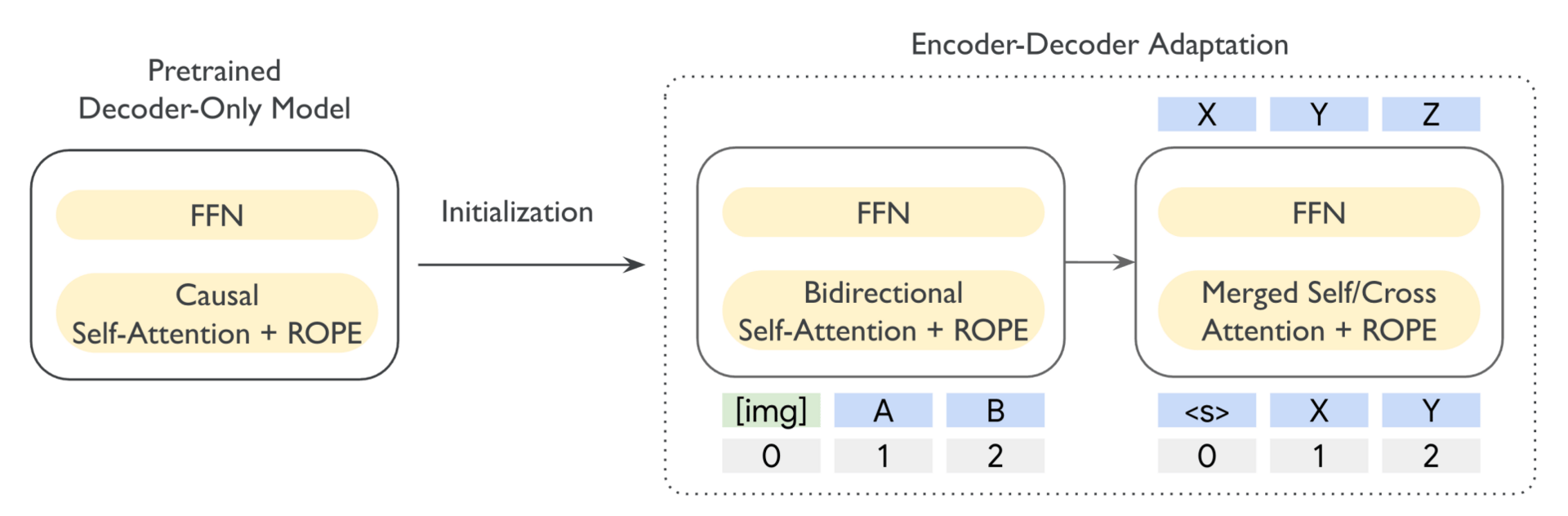
Overview of T5Gemma 2. Encoder/decoder parameters are initialized from the pretrained decoder-only model, and then pretrained with UL2.
To make these models highly efficient, the researchers streamlined the internal machinery by merging different attention mechanisms into a single, unified module and sharing vocabulary tools across the system.

Detailed post-training results for Gemma 3, T5Gemma, and T5Gemma 2.
The results were impressive: despite being trained on shorter sequences of data, the models demonstrated a surprising ability to handle extremely long contexts, extrapolating well beyond their training wheels. Furthermore, even the smallest versions of the model proved capable of understanding images alongside text, matching or even outperforming their predecessors.
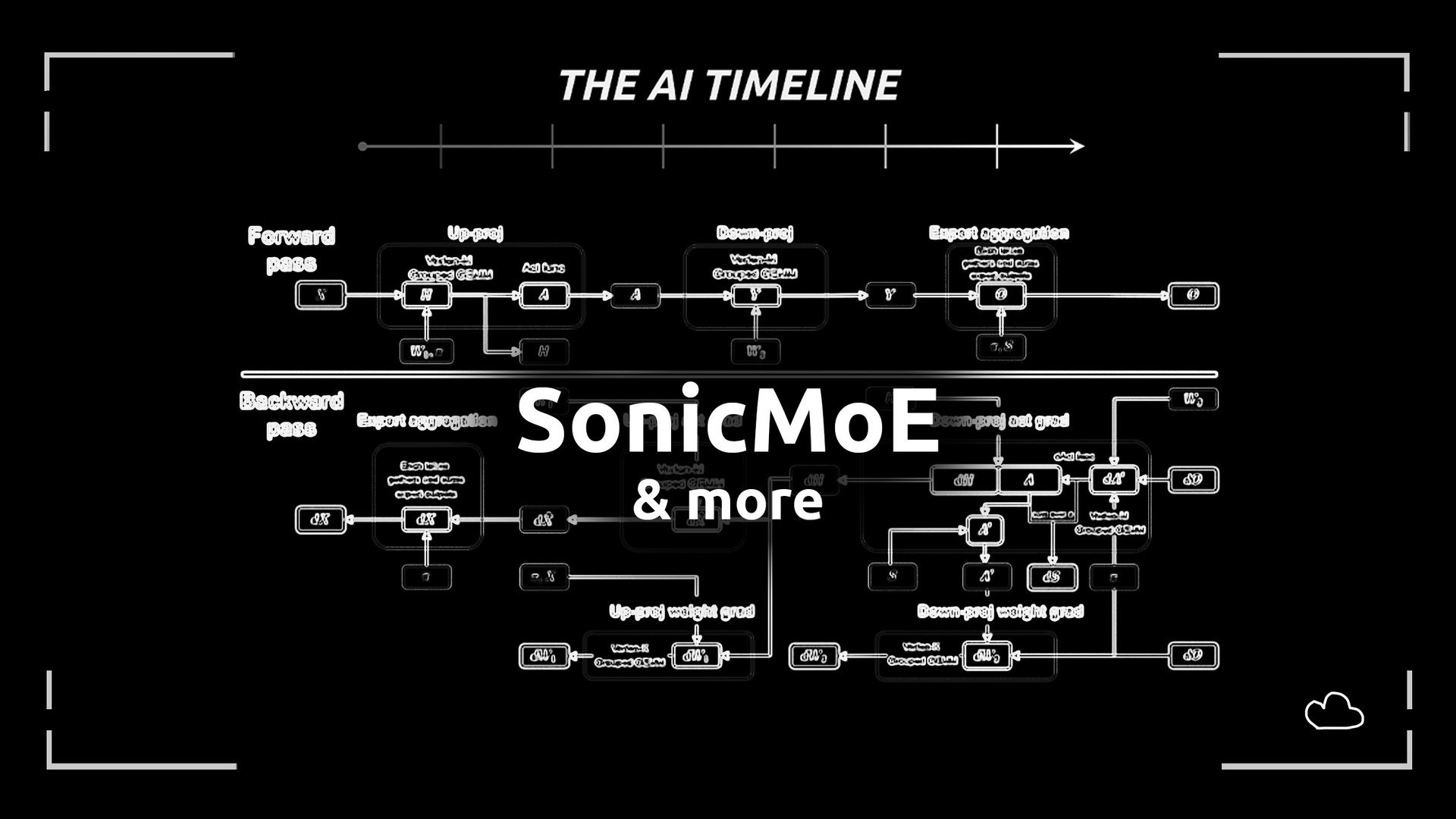
SonicMoE: Accelerating MoE with IO and Tile-aware Optimizations
Karan and Du [Harvard University]
♥ 1.4k LLM MoE Optimization
We want better AI, but don’t want to pay millions of dollars to train it. Right now, one popular solution is to use the "Mixture of Experts" approach, which works by dividing a large neural network into many specialized sub-networks, activating only the few necessary ones for any given task.
This approach theoretically promises smarter and more efficient models, but as these experts become smaller and more numerous to improve precision, the computer chips running them struggle to keep up. The hardware begins spending more time simply moving data around than actually processing it.
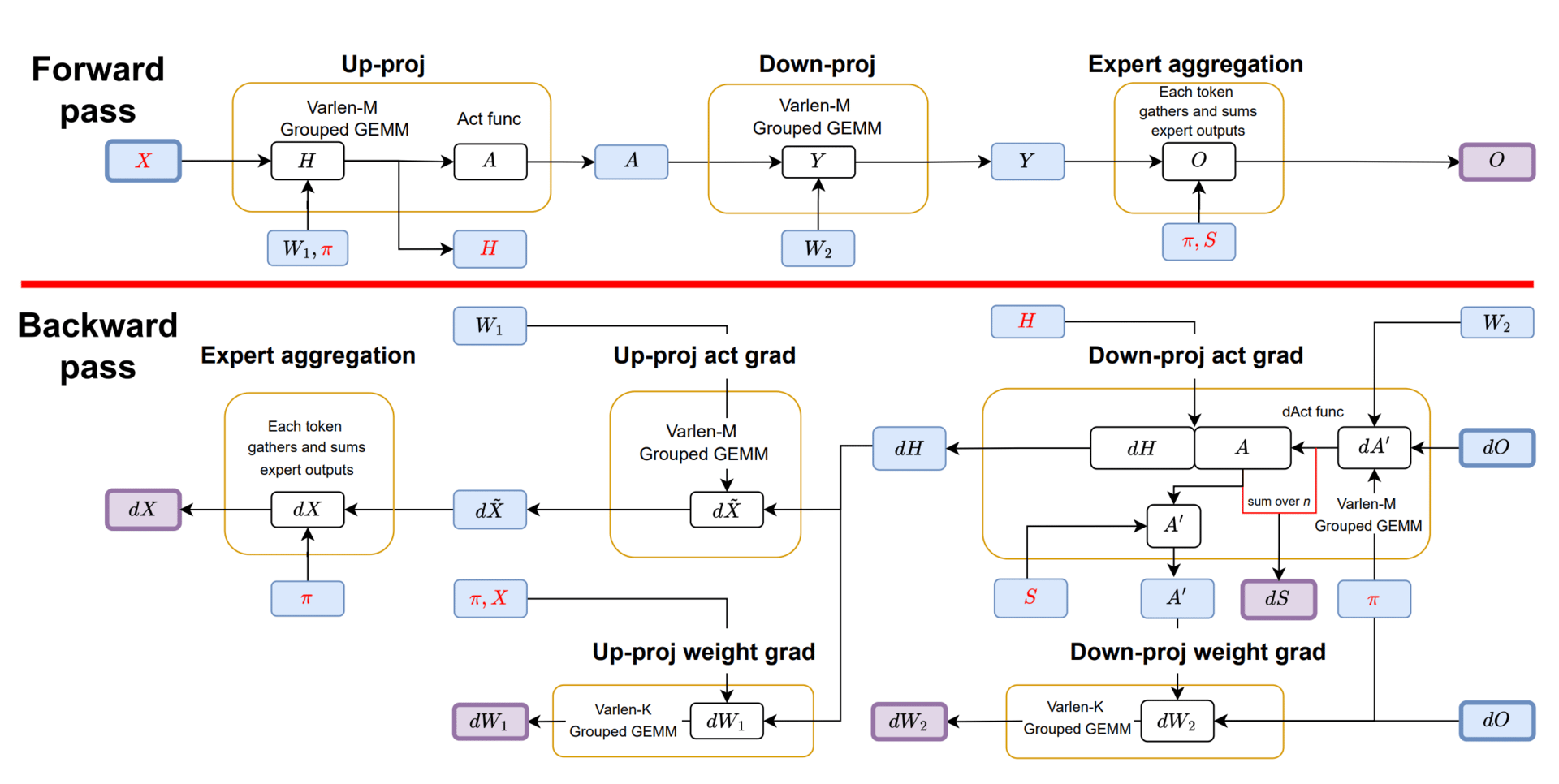
Computational workflow of SonicMoE’s 8 launched kernels, grouped by yellow boxes.
This paper has introduced a new system called SonicMoE that changes how these complex networks use computer memory. They discovered that by intelligently reorganizing the mathematical operations required for training, they could drastically reduce the amount of temporary data the system needs to remember, which cuts the memory footprint nearly in half without losing any information.

Additionally, they introduced a clever "token rounding" strategy that ensures data is assigned to experts in perfectly sized chunks. Previously, the hardware would often waste energy processing empty filler space just to satisfy rigid computational requirements.

MoE Scaling Trends
By aligning the data flow with the physical design of the chips and performing data transfer and calculation simultaneously, the researchers were able to process information nearly twice as fast as previous methods on modern graphics processors.
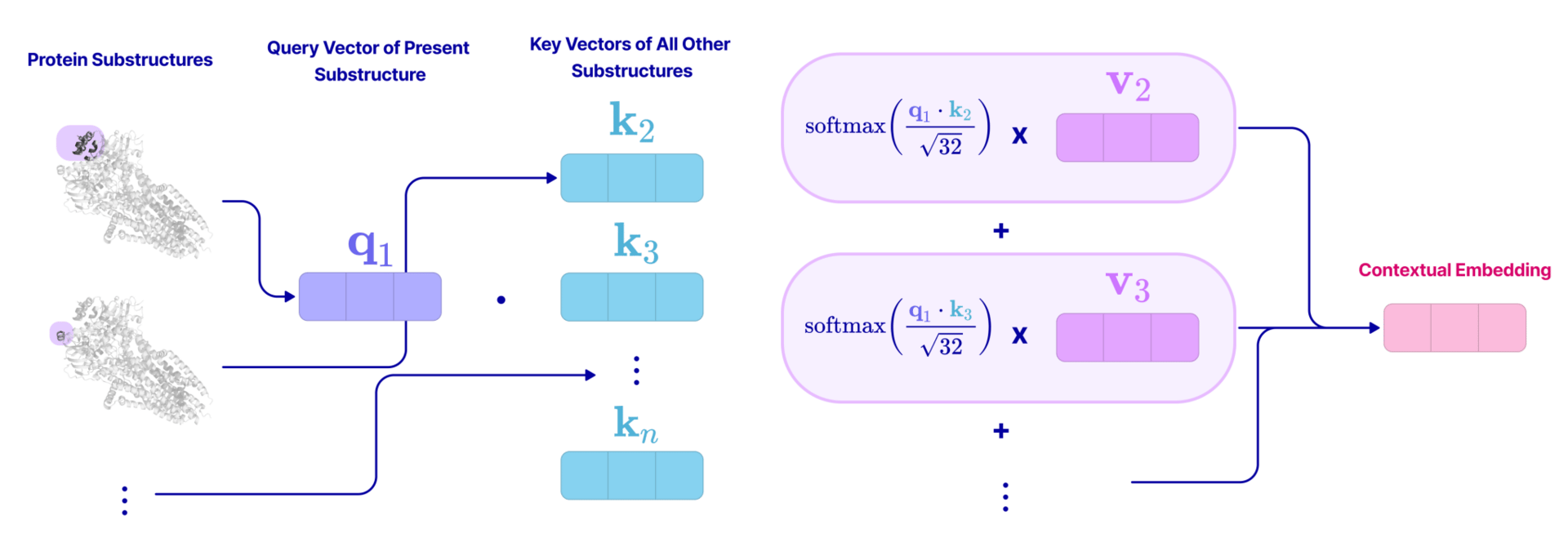
Next-Embedding Prediction Makes Strong Vision Learners
Xu et al. [University of Michigan, New York University, Princeton University, University of Virginia]
♥ 624 Vision
Teaching computers to "see" has required a different playbook than teaching them to read. While LLMs grew powerful by simply guessing the next word in a sentence, vision models rely on complex engineering tricks, such as reconstructing missing pixels like a puzzle or comparing thousands of image pairs to learn differences.
A team of researchers recently asked could the simple "predict what comes next" strategy that worked for NLP, work just as well for images? The team introduced a method called Next-Embedding Predictive Autoregression, or NEPA. Instead of asking the model to paint back missing parts of a picture pixel-by-pixel, they trained it to predict the abstract features (or "embeddings") of the next patch of an image based on what it has already seen.

In simple words, this is like asking a person to guess the meaning of the next puzzle piece before picking it up, rather than trying to draw the picture from memory. Remarkably, this simplified approach allowed a standard Transformer model to achieve top-tier accuracy on major classification benchmarks without needing complex decoders, specific visual vocabularies, or heavy data augmentation.
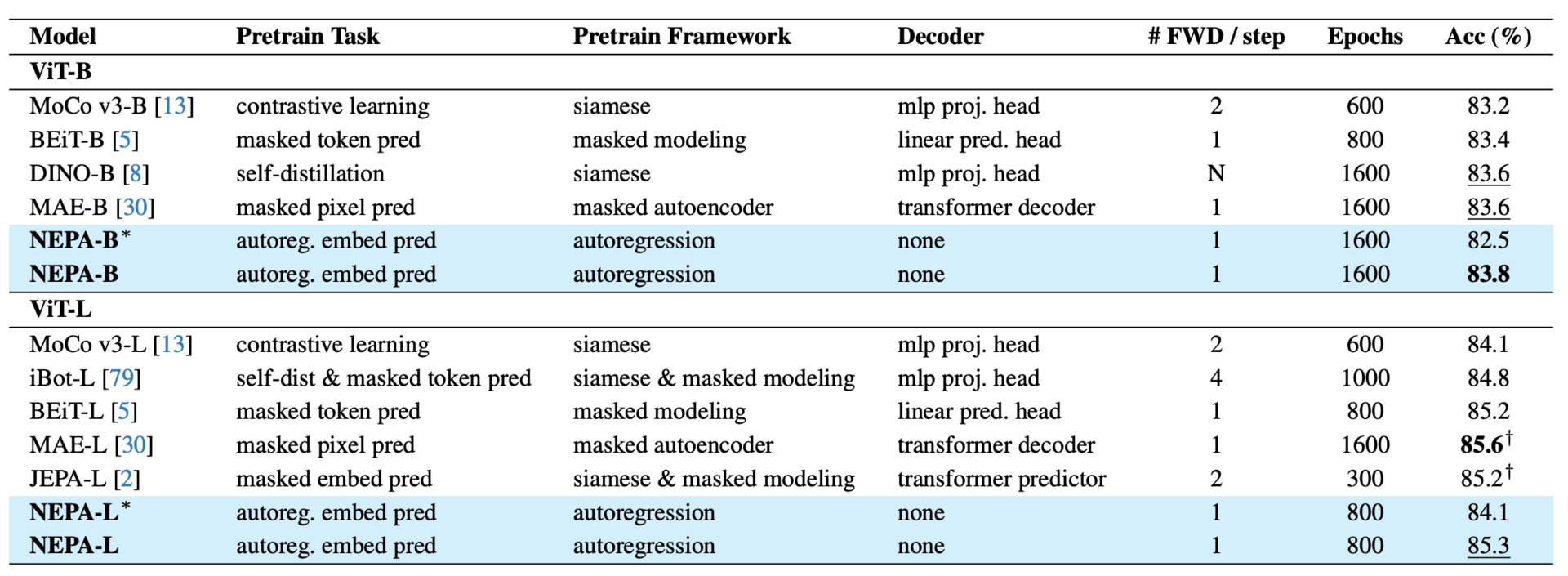
Comparison of different self-supervised learning frameworks on ImageNet-1K classification.
By focusing on predicting high-level information rather than raw details, the model naturally learned rich, transferable visual concepts that performed exceptionally well even on dense tasks like segmentation. This discovery suggests that the heavy architectural machinery often used in computer vision might be unnecessary.
Reply