- The AI Timeline
- Posts
- Scaling Up Diffusion Language Models to 100B!
Scaling Up Diffusion Language Models to 100B!
Scaling Up Diffusion Language Models to 100B, Adding 1 Attention Layer & Make Visual Encoders Generate Images, LayerNorm Is Not Needed In Transformer, and more
by cloud
December 16, 2025
Dec 8th ~ Dec 15th
#86 Latest AI Research Explained Simply
🗞️ Industry News in 1 Line
♥ 1.3k Alibaba’s Qwen Team has released Qwen3-Omni-Flash, which is capable of processing text, audio, and video with seamless real-time responses. This upgraded iteration significantly enhances audio-visual interactions by resolving previous stability issues and offering precise control over system prompts and personas. Furthermore, it seamlessly integrates natural multi-turn video and audio understanding with indistinguishable human voices and fully customizable personalities, all backed by robust support for 119 text and 19 speech languages. Try it on Modelscope or HuggingFace.

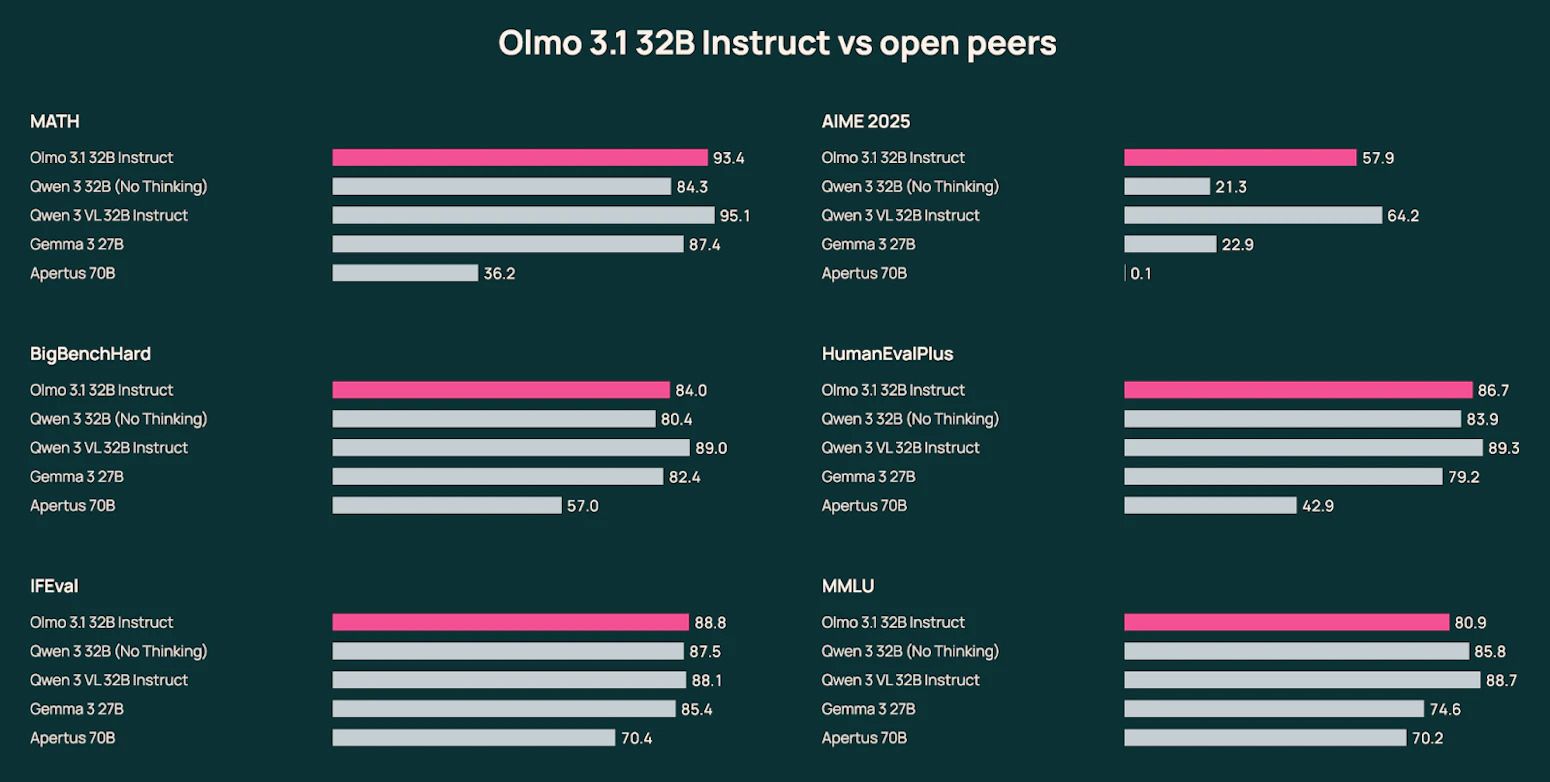
♥ 712 Ai2 has announced the release of Olmo 3.1, which is their most capable model to date with the new Think 32B and Instruct 32B variants. The Olmo 3.1 Think 32B model achieves significant performance gains in logic and reasoning benchmarks. They also launched updated 7B models optimized for math and code along with full weights, data, and training recipes for the entire suite. Try it online or download from HuggingFace.
♥ 1k NVIDIA has launched the Nemotron 3 family with a suite of open models, datasets, and libraries designed to advance specialized agentic AI. Nemotron 3 Nano is a hybrid Mamba-Transformer mixture-of-experts (MoE) model that delivers highly efficient inference and a 1 million token context window while using only roughly 3B active parameters. NVIDIA has released the model under an open license alongside NeMo Gym, a new open-source reinforcement learning library for scalable agent training. If you are feeling adventurous, why not join the Nemotron Model Reasoning challenge?

New Premium Insights release
For context, Premium Insights is where I write down longer form content that I think is interesting but not long enough to be make into YouTube videos.
Last week I have published the below blog:

I spent a lot of time on this quarterly(?) AI research trend report (~4000 words), so don’t miss out!
One Layer Is Enough: Adapting Pretrained Visual Encoders for Image Generation
Gao et al. [Apple]
♥ 450 Image Generation
Using powerful, pre-trained visual AI models with image generators has always been tricky. These understanding models produce rich, high-dimensional features, but today’s best generators need to work in a much smaller, more stable space to create images efficiently. This mismatch usually forces complex solutions. But a new method shows we might have been overcomplicating things.

Comparison between standard VAE, VA-VAE, RAE, and FAE.
Instead of forcing the generator to work with the bulky original features or building a complex translator, the method, called FAE, uses a minimal encoder (just a single attention layer) to gently compress those features into a compact, generation-friendly space. The real cleverness is in the double-decoder setup.
First, a dedicated decoder faithfully reconstructs the original high-quality features from this compact code. Then, a second, separate decoder uses those reconstructed features as its guide to generate the final image pixels. This separation of duties means the system retains the semantic understanding from the powerful pre-trained model while giving the image decoder the clear, low-dimensional signals it needs to work reliably.

An illustration of Training Stages of FAE. Stage Ia and Ib can be trained independently.
It can plug into different types of generators, like diffusion models or normalizing flows, and can use features from various popular pre-trained models like DINO or SigLIP. The results are impressive. On the standard ImageNet 256x256 benchmark, a diffusion model using FAE achieved top-tier image quality, scoring a near state-of-the-art FID of 1.29.
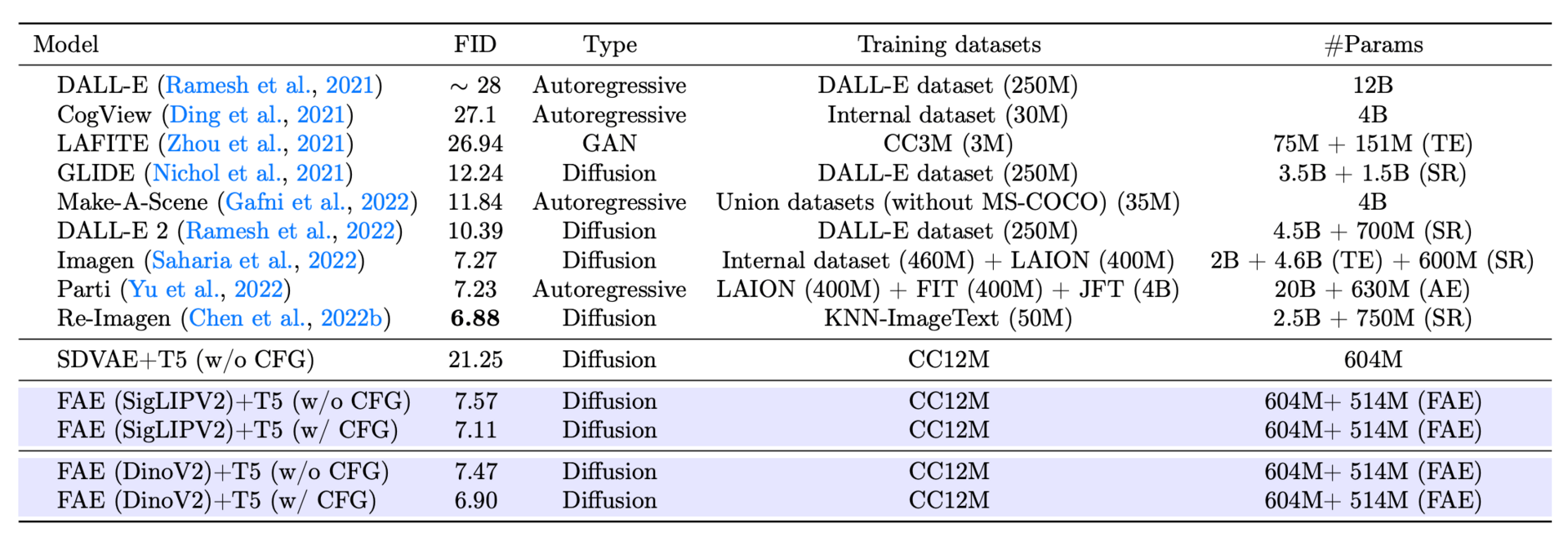
FID results of different models on MS-COCO validation (256 × 256).
Stronger Normalization-Free Transformers
Chen et al. [Princeton University, NYU, Carnegie Mellon University]
♥ 1k Transformers bycloud’s pick
Normalization layers are a common trick to help deep neural networks train smoothly, but they come with a cost. They need extra computation to track statistics and can be sensitive to settings like batch size. Researchers have been looking for simpler, drop-in replacements, and point-wise functions like Dynamic Tanh (DyT) showed it was possible to match normalization performance.

Structure of Dynamic erf (Derf), a point-wise function, that outperforms normalization layers and other point-wise functions.
To find an optimal design, the researchers first identified what makes a point-wise function work well as a normalization replacement. They tested four key properties: the function should be zero-centered, bounded in its output, sensitive to small changes around zero, and monotonic (always increasing or decreasing). Functions that broke these rules often led to unstable training or worse performance. With these principles as a guide, they performed a large-scale search across many candidate S-shaped functions.

Results of zero-centeredness on ViT-Base.
The search identified a clear winner: a dynamically parameterized version of the error function, called Derf. This function, related to the Gaussian cumulative distribution, naturally has all the desired properties. When integrated into a model, it simply transforms each neuron's activation using learnable scaling and shifting parameters. The team tested Derf extensively, replacing normalization layers in Transformers for vision, speech, DNA, and language tasks. In nearly every case, Derf outperformed both standard normalization layers and the previous best alternative, DyT.
On the Interplay of Pre-Training, Mid-Training, and RL on Reasoning Language Models
Zhang et al. [Carnegie Mellon University, Language Technologies Institute]
♥ 1.3k LLM Reasoning
We often see language models get better at reasoning after reinforcement learning, but it's hard to tell if RL is teaching them new skills or just polishing what they already learned in pre-training. To solve this, researchers built a fully controlled test using synthetic math problems. This let them isolate and study the distinct roles of pre-training, mid-training, and RL.

Overview of the data generation framework, task setup, and process-verified evaluation.
The study shows RL can create new reasoning ability, but only under specific conditions. If a task is already well understood from pre-training, RL just fine-tunes the model's existing skill. For RL to teach something genuinely new, the task must be slightly beyond the model's current ability. The model also needs a seed of knowledge from pre-training.
For example, to solve a problem in a new context like a "zoo" scenario, the model must have seen that context at least a little bit during pre-training. Even just 1% exposure gives RL enough material to work with and generalize from.

The researchers found that mixing mid-training with RL leads to the best generalization. Mid-training, which uses supervised learning on data from the model's edge of competence, builds a strong foundation. RL then explores from that foundation.
Allocating most compute to mid-training with a little RL is great for known tasks, while dedicating more budget to RL is better for tackling completely new, harder problems. Adding rewards for correct reasoning steps, not just the final answer, further reduced errors and improved the reliability of the model's solutions.

In tests, a well-calibrated RL approach improved performance on harder tasks by up to 42%, and proper pre-training seeding allowed contextual generalization improvements of up to 60%. These findings show us that when we design training pipelines, we need to ensure broad pre-training coverage of basic concepts, use mid-training to build robust priors, and then apply RL to explore just beyond the model's current limits.
LLaDA2.0: Scaling Up Diffusion Language Models to 100B
Bie et al. [Ant Group, Renmin University of China, Zhejiang University, Westlake University, HongKong University of Science and Technology]
♥ 757 Diffusion LLM
Today's powerful language models generate text one word at a time, which creates a bottleneck. This new approach aims to break that bottleneck by converting existing models into a different kind that can predict many words at once.
It uses a three-stage training method. Instead of building a parallel model from scratch, which is very costly, the researchers start with a strong existing model trained for sequential generation. They then carefully retrain it using a process called Warmup-Stable-Decay.

A schematic of the progressive training framework for transforming an AR model into a MDLM.
First, in the Warmup phase, the model slowly learns to reconstruct small, masked blocks of text instead of just the next word. The block size gradually increases until the model is reconstructing entire sequences at once in the Stable phase. Finally, in the Decay phase, the model is tuned back to working with smaller blocks, which makes it much faster for practical use while keeping its new parallel skills.

To make this conversion stable and efficient, the team introduced important techniques. They use a special document-level attention mask during training. This prevents the model from getting confused by attending to unrelated text when multiple documents are packed together for efficiency, ensuring it learns clean, coherent reconstructions. For the final instruction-tuning phase, they also apply a method called complementary masking. This clever trick ensures nearly every token in the training data contributes to the learning signal in each step, speeding up training and improving the model's grasp of language.

The final models, including a 100B-parameter version called LLaDA2.0-flash, show strong performance on reasoning, coding, and general knowledge benchmarks. It also shows a significant boost in inference speed, generating many more tokens per second than comparable auto-regressive models.
Closing the Train-Test Gap in World Models for Gradient-Based Planning
Parthasarathy et al. [Columbia University, New York University]
♥ 1.3k LLM
Gradient-based planning world models can be used for intelligent robot control, but in practice, its performance has often fallen short of slower, search-based alternatives. This is because of train-test mismatch: these models learn to predict the next state from expert demonstrations, but are later used to optimize sequences of actions, which often leads them into unfamiliar and unreliable territory.

Overview of our two proposed methods.
To bridge this gap, the researchers developed two clever fine-tuning methods. Online World Modeling tackles the problem of the model venturing into unknown states during planning. It works by using a simulator to correct the trajectories that gradient-based planning produces, and then training the model on these new, corrected paths.

This teaches the model to be accurate even for the non-expert actions it will encounter during optimization. Separately, Adversarial World Modeling focuses on smoothing the optimization landscape itself. It trains the model on deliberately perturbed versions of expert data, making the model more robust and creating a loss surface that is easier for gradient descent to navigate.

These techniques significantly close the train-test performance gap. In tests on object manipulation and navigation tasks, gradient-based planning with an adversarially fine-tuned model matched or exceeded the success rates of the powerful but computationally heavy Cross-Entropy Method (CEM) using only 10% of the computation time.
Reply