- The AI Timeline
- Posts
- The Universal Weight Subspace Hypothesis
The Universal Weight Subspace Hypothesis
PretrainZero, Stabilizing RL with LLMs and more
by cloud
December 09, 2025
Dec 2nd ~ Dec 9th
#85 Latest AI Research Explained Simply
🗞️ Industry News in 1 Line
♥ 300 Mistral introduces Devstral 2, a SoTA open-source coding model family in 123B and 24B sizes, alongside Mistral Vibe CLI, a natural-language-powered tool for executing codebase changes.
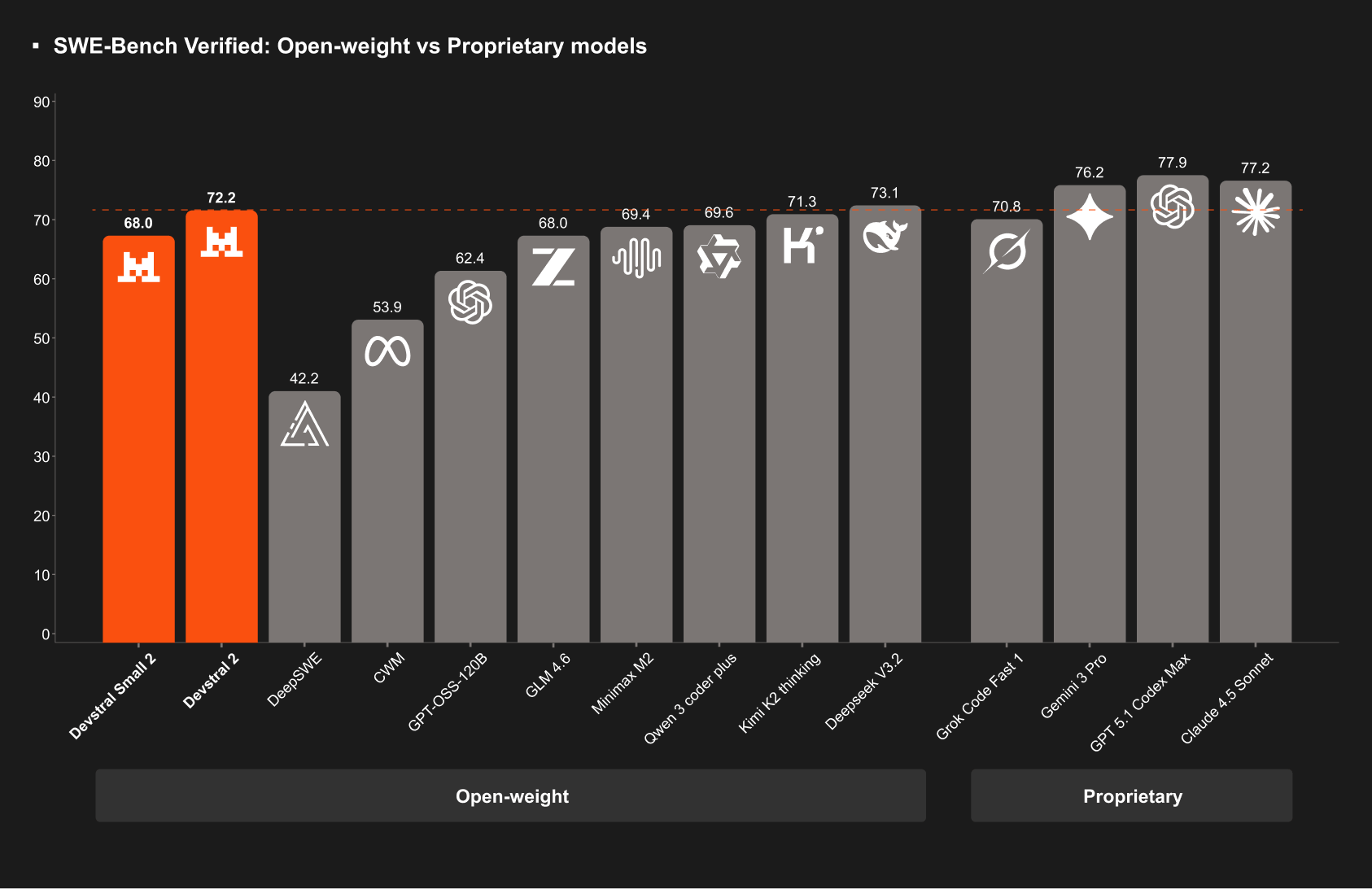
♥ 1.6k Z.ai introduces GLM-4.6V, which is a 106B vision-language model with 128K context capable of multimodal input, interleaved image-text generation, and function calling. While the 9B GLM-4.6V-Flash offers low-latency performance for local use. Both models support end-to-end search, reasoning, and video analysis with strong frontend development capabilities.
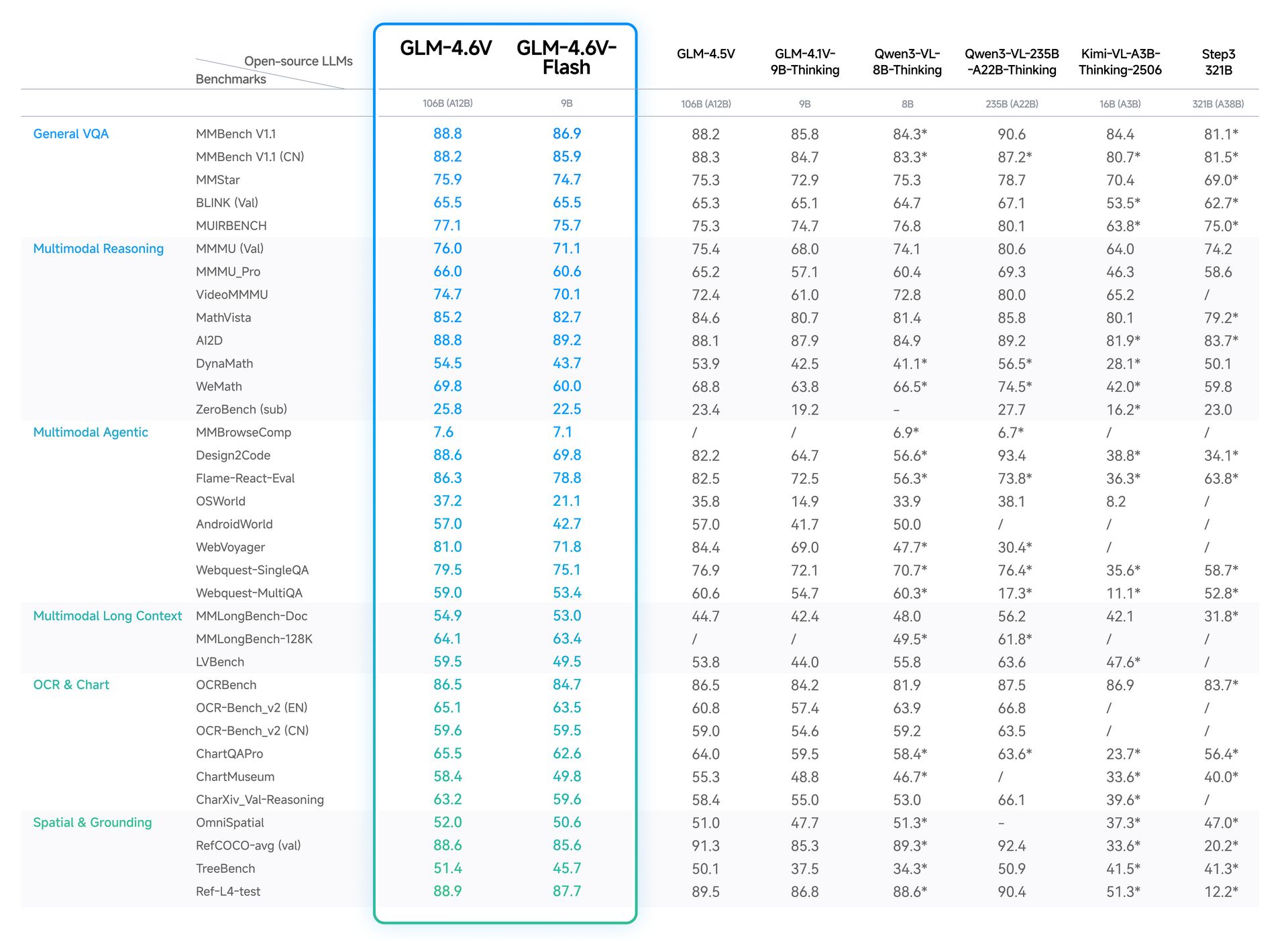
♥ 1k Essential AI introduces Rnj-1, which is an 8B open-source base and instruct model optimized for code, math, and STEM reasoning, achieving top-tier results on SWE-bench Verified.
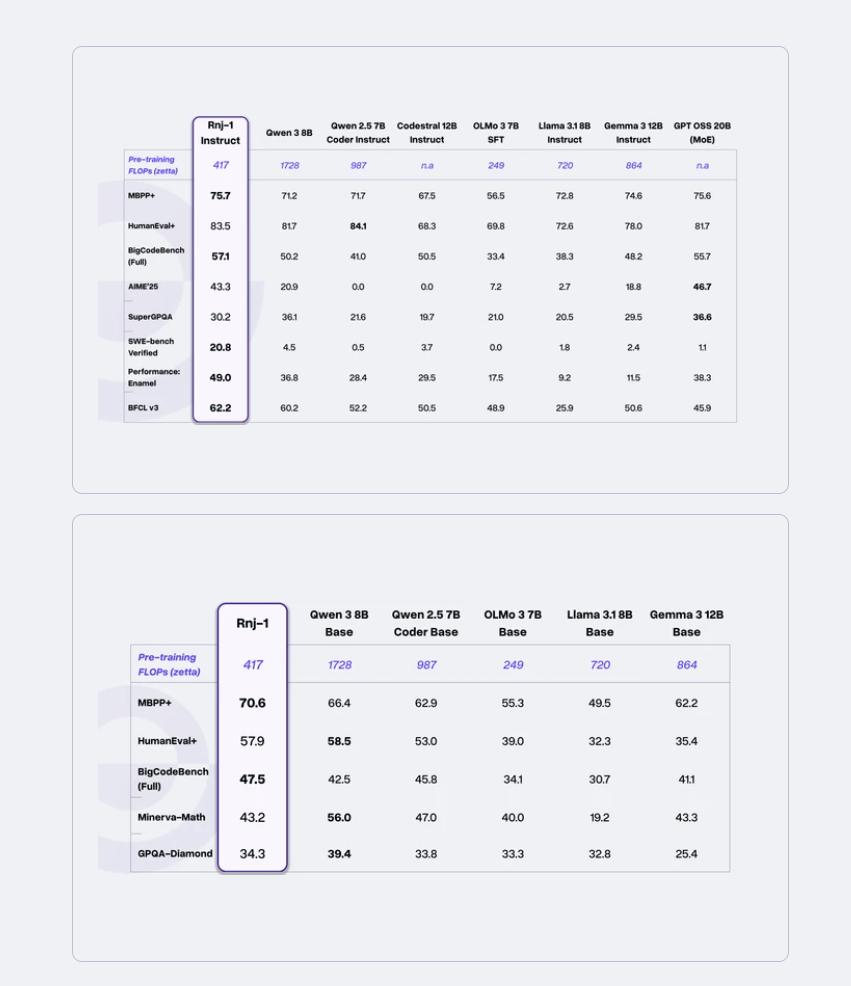
♥ 449 NousResearch introduces Hermes 4.3, which is a 36B model post-trained on the decentralized Psyche network secured by Solana, delivering performance on par with the 70B Hermes 4 while using half the parameters, showcasing a leap in training efficiency and model compression.
New Premium Insights release
For context, Premium Insights is where I write down longer form content that I think is interesting but not long enough to be make into YouTube videos. Last week I have published the below blog too:
We also got a new quarterly AI research trend report (~4000 words) coming out this week, so don’t miss out! On it, I’ll be sharing an interesting story about the latest research development, and also the key AI research in the last few months that might determine the directions of AI research in the future.
PretrainZero: Reinforcement Active Pretraining
Xing et al. [Chinese Academy of Sciences, Xiaohongshu Inc.]
♥ 258 RL
Teaching AI to learn more like humans can make more capable systems. Today's best models excel in specific areas like coding or math, but they hit a wall when trying to learn general reasoning. This is because their advanced training heavily depends on having clear, verifiable rewards or correct answers, which are scarce outside of narrow domains. This paper introduces a new framework called PretrainZero which tackles this by moving reinforcement learning into the initial pretraining phase, using only raw, unlabeled text.
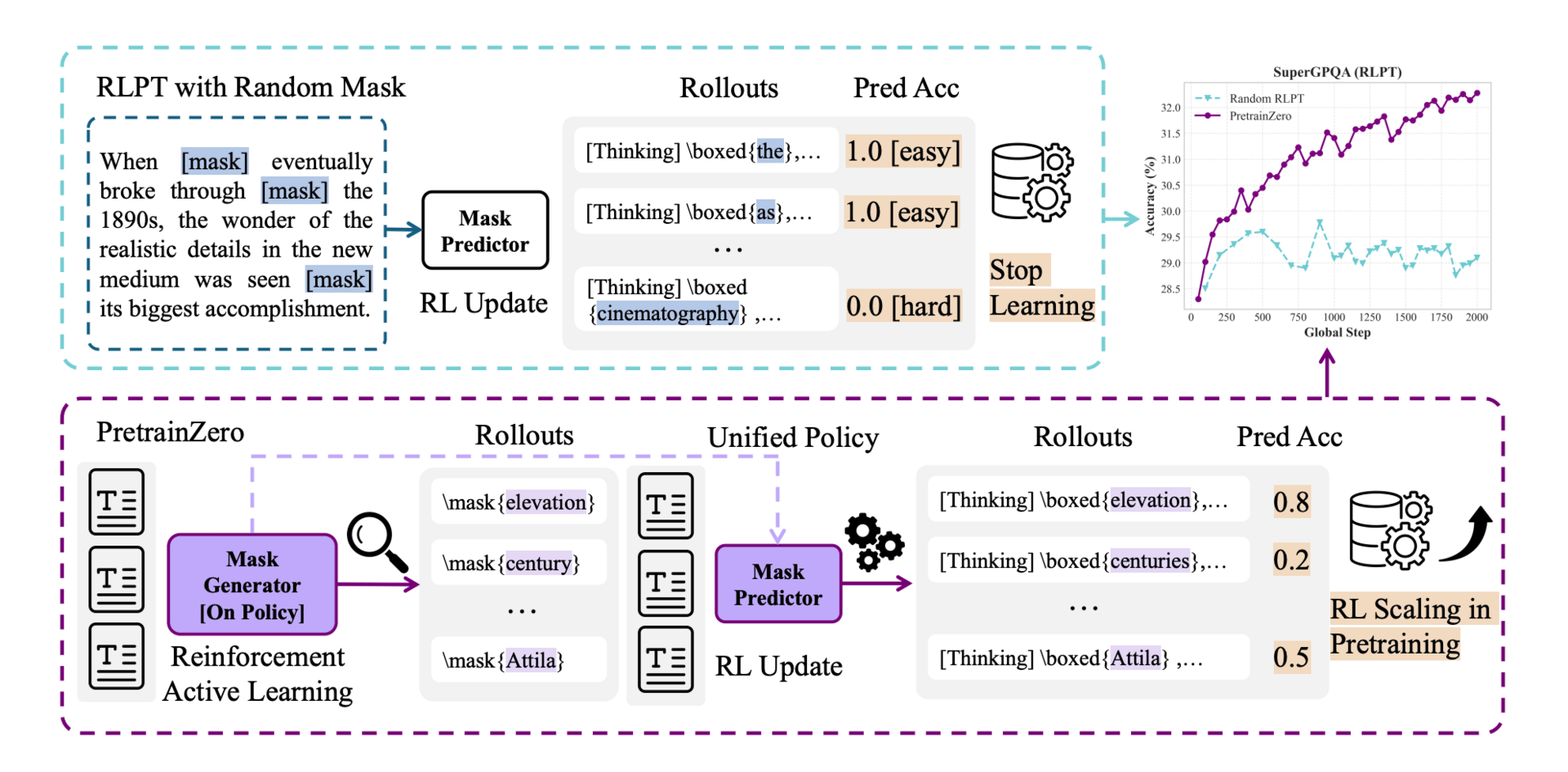
An overview of Reinforcement Active Pretraining.
The main idea is to have the model actively decide what to learn from a massive text corpus, like Wikipedia. Instead of passively predicting every next word, the system uses two parts working together. One part acts as a mask generator, scanning text to pick out specific, informative spans of words to hide. Think of it as a student choosing the most valuable practice questions from a textbook. The other part, the mask predictor, then tries to reason through and fill in those hidden spans. The two parts are trained jointly: the generator learns to propose masks that are reasonably challenging for the predictor, and the predictor improves its reasoning to solve them.
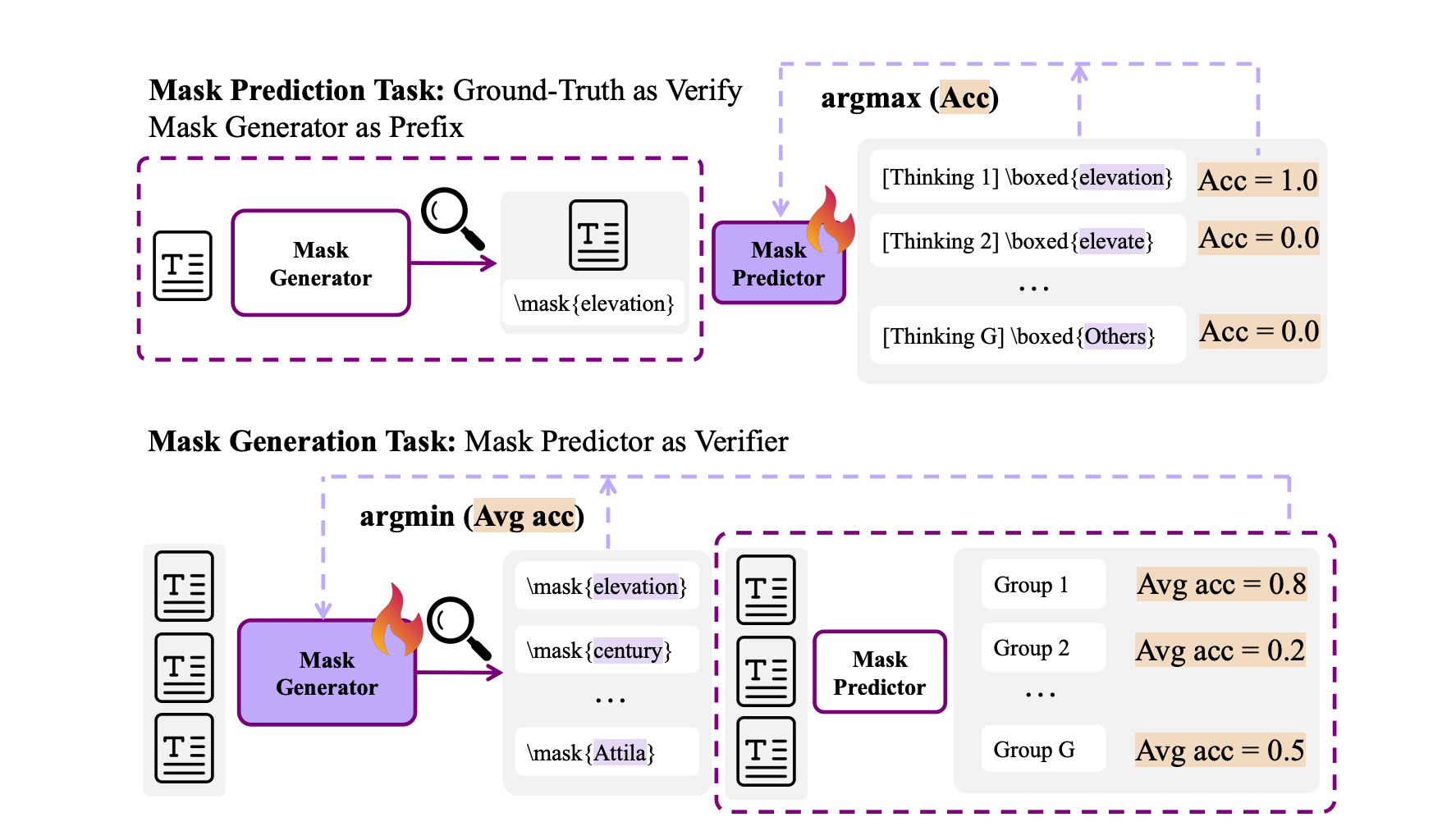
Pretraining Mask Prediction and Mask Generation tasks with GRPO.
This active back-and-forth creates a virtuous cycle for learning. The generator avoids picking trivially easy or impossibly noisy text, steering the predictor toward genuinely useful concepts. The only feedback is whether the predictor's final answer matches the original hidden text. This is a simple, self-supervised signal that requires no external labels. This allows the model to practice chain-of-thought reasoning at a massive scale directly from base models, breaking past the need for curated, verifiable data.

Prompt for Mask Generation and Prediction.
After reinforcement pretraining with PretrainZero, the model showed significant gains on tough benchmarks like MMLU-Pro and mathematical reasoning.
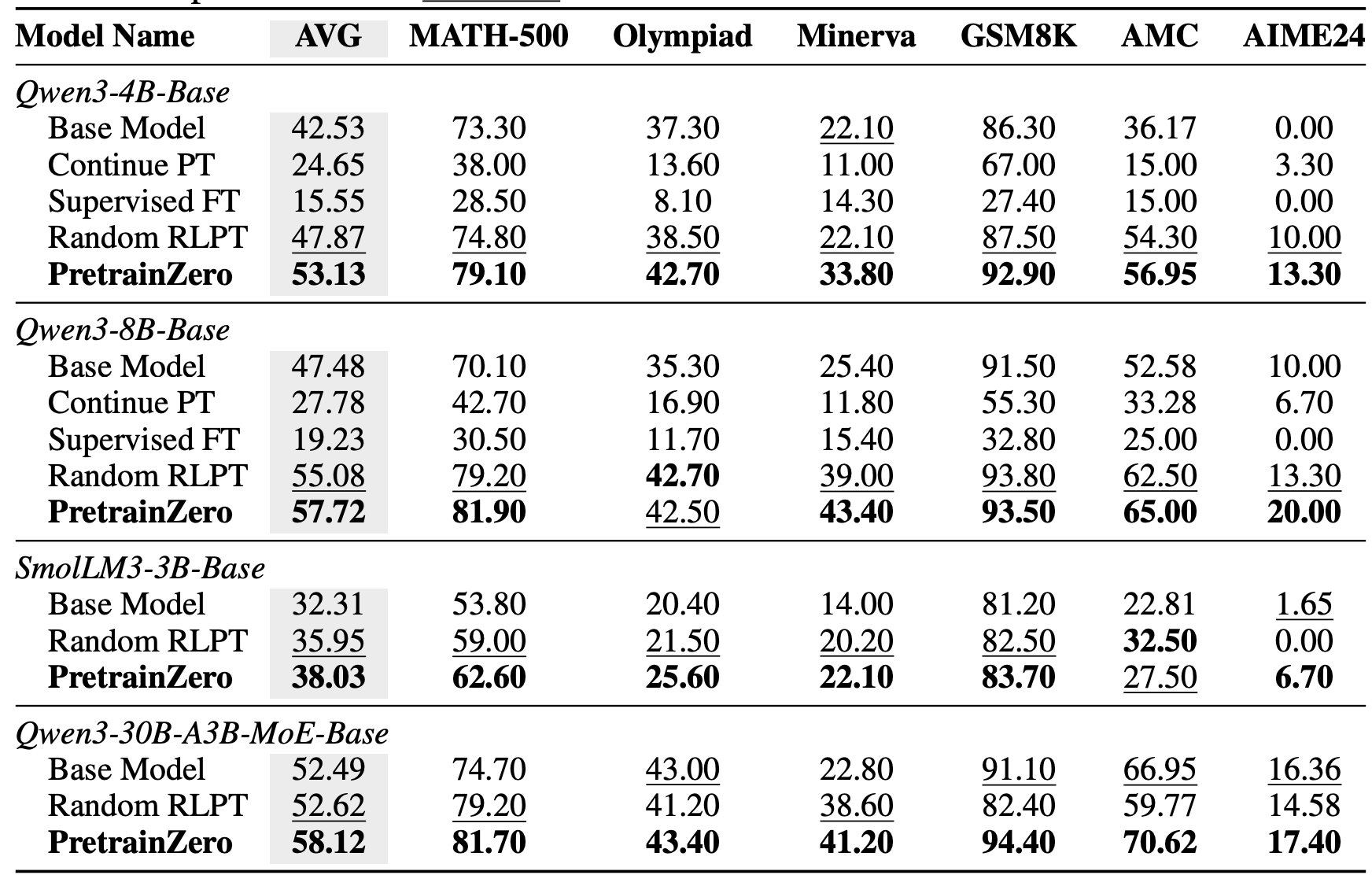
Results on math-domain reasoning benchmarks.
Stabilizing Reinforcement Learning with LLMs: Formulation and Practices
Zheng et al. [New York University]
♥ 204 RL
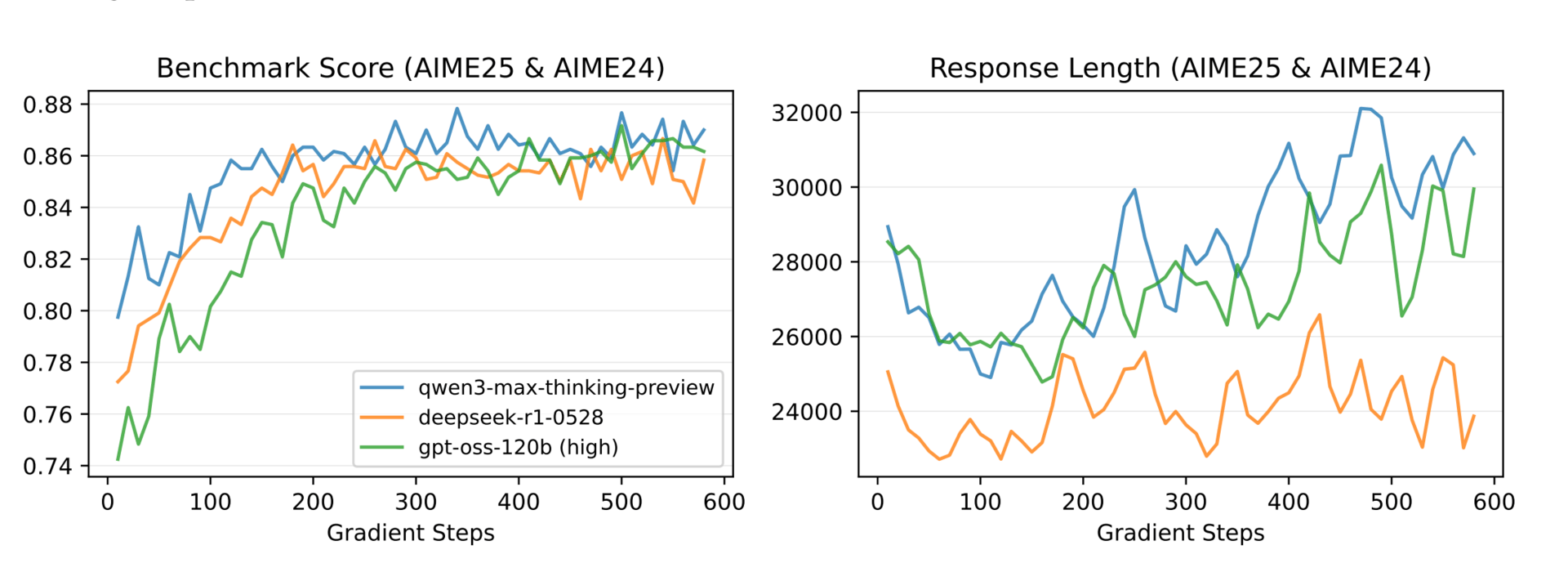
If you’ve ever trained a large language model with reinforcement learning, you know that rewards are usually assigned to entire responses. But the model is optimized token by token. That mismatch can make training unstable, and it’s especially tricky with models that use a mixture of experts, where the routing of different experts can change unpredictably. This paper shows us when and why a simple token-level optimization can actually work to improve the full response.
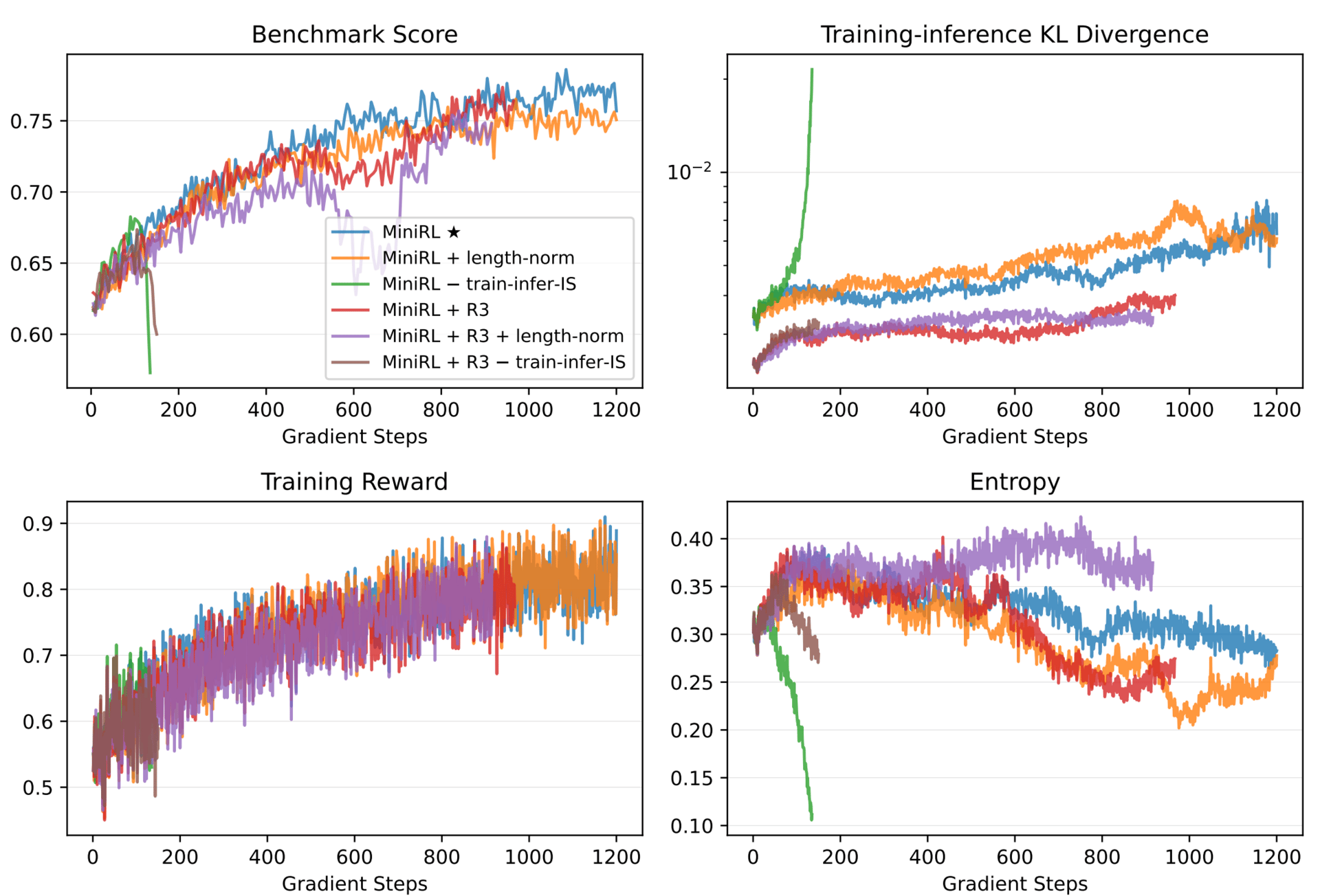
Results of on-policy training with gbs (global batch size) = mbs (mini-batch size) = 1024.
This paper argues that optimizing the expected sequence-level reward can be approximated by a simpler, token-level objective. This approximation holds when two conditions are met: the numerical outputs from the training and inference engines are close, and the policy being optimized isn’t too different from the one used to sample data. When these gaps are small, the token-level update becomes a valid first-order approximation of what you really want to optimize.
This explains why certain techniques help. The importance sampling weight isn’t just a trick; it directly corrects for the mismatch between training and inference. Similarly, clipping prevents overly aggressive updates that would widen the gap between the sampling policy and the learning policy. For mixture-of-experts models, a method called Routing Replay fixes which experts are used during optimization, reducing both the engine discrepancy and policy drift. Together, these methods keep the approximation valid and training stable.
Results of varying cold-start initializations.
The researchers tested this extensively using a 30B parameter mixture-of-experts model. They found that for on-policy training, the basic policy gradient with importance sampling correction was most stable.
Generative Video Motion Editing with 3D Point Tracks
Lee et al. [Adobe Research, Adobe, University of Maryland College Park]
♥ 880 Video Generation
AI models can edit motion videos, but it is more than just moving objects or changing the camera angles as AI models often fail to keep the entire scene consistent and realistic. Current tools often fall short, either losing the original background when editing an object or being unable to finely control how something moves in 3D space. This research tackles that by using 3D point tracks as a guide, allowing for joint editing of both camera viewpoints and detailed object motion while preserving the full context of the original video.
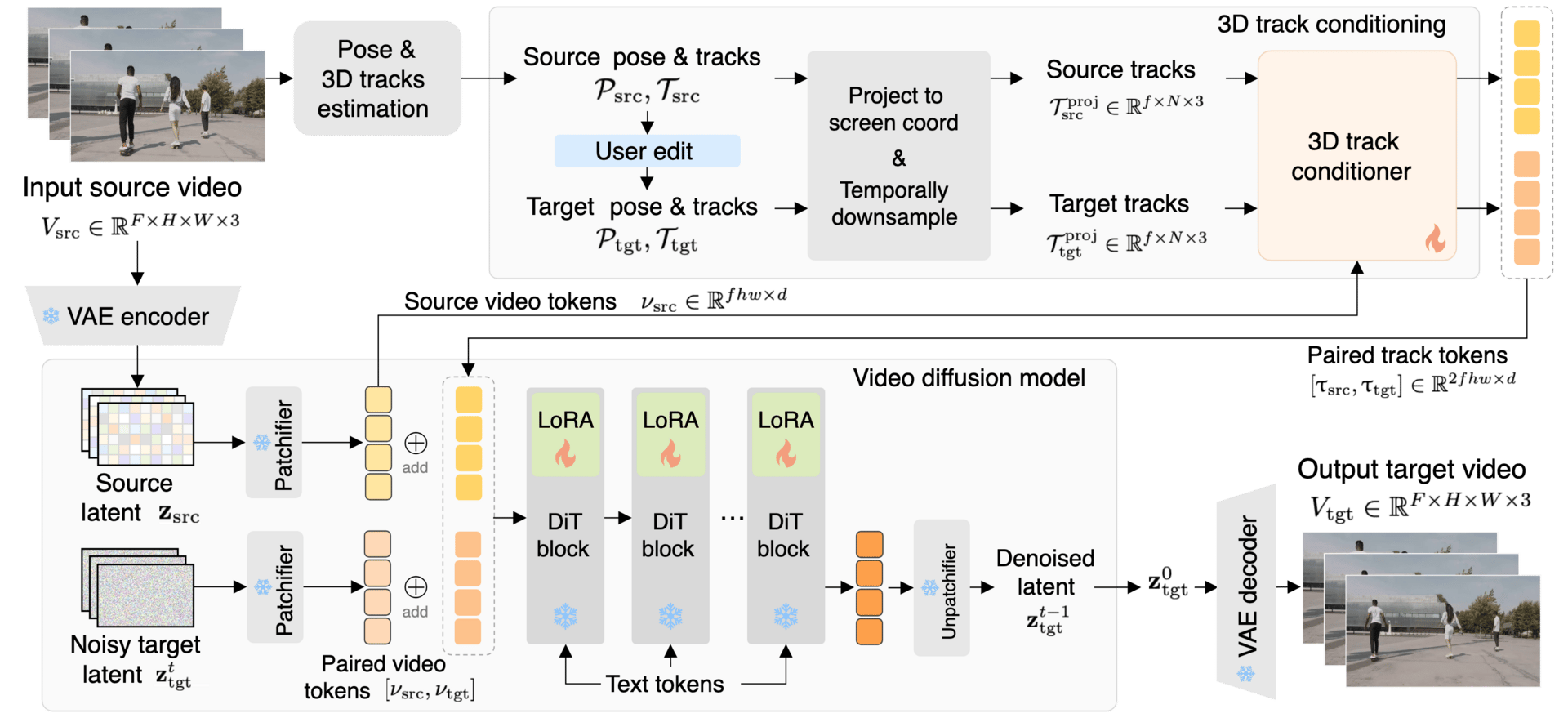
Edit-by-Track framework.
The system works by first estimating the 3D path of points in the source video. Users can then edit these paths to define new motions for the camera or objects. A special component called the 3D track conditioner is key; it uses the original video frames and the edited 3D tracks to intelligently sample visual details and project them into the new video. Unlike simpler 2D methods, these 3D tracks provide depth information, which helps the model correctly handle occlusions and the order of objects in space, leading to more precise edits.
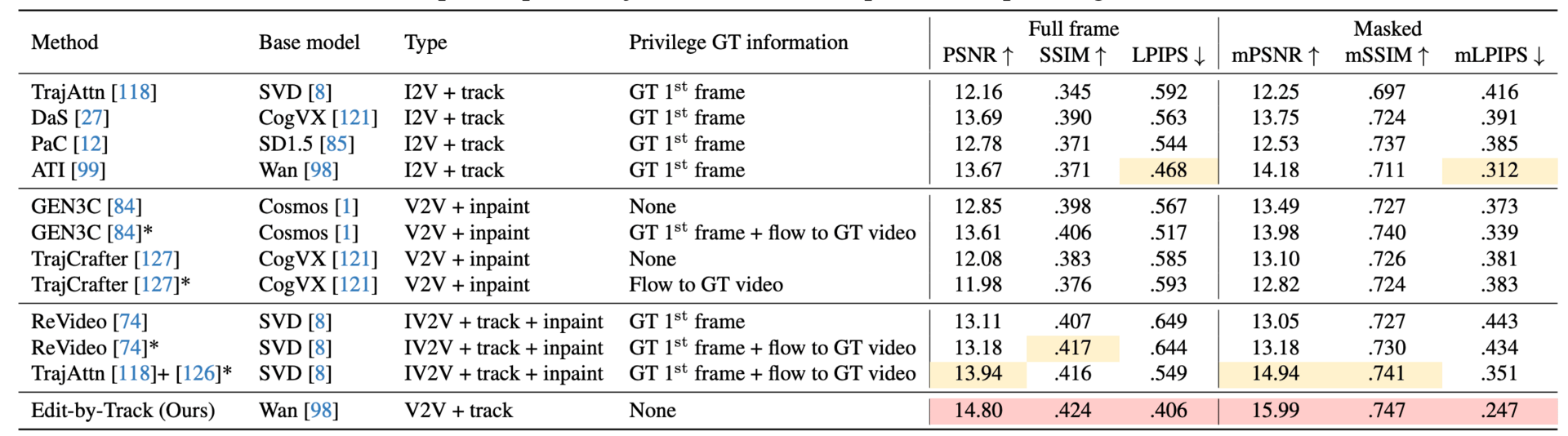
Quantitative comparison on joint camera and object motion on DyCheck
To train this model without a huge dataset of perfect video pairs, the team used a two-stage approach. They first trained on synthetic videos with perfect 3D track data to teach the model the basics of motion control. Then, they fine-tuned it on real-world videos by cleverly using non-consecutive clips from the same video as pairs, which naturally simulates changes in both camera and object movement.

In tests, this method outperformed other state-of-the-art techniques in video quality and motion accuracy. It opens up new creative possibilities, from synchronizing dancers' movements to deforming objects or changing viewpoints seamlessly.
The Universal Weight Subspace Hypothesis
Kaushik et al. [Johns Hopkins University]
♥ 805 LLM Interpretability
Even though different neural networks are trained on wildly different tasks, they might all be speaking the same geometric language? While training a model for a specific task often feels like a unique journey, new research suggests the final destination in weight space might be surprisingly similar for many models. When you analyze the weight matrices of models trained on diverse tasks, they don't scatter randomly but instead converge to remarkably similar low-dimensional subspaces.
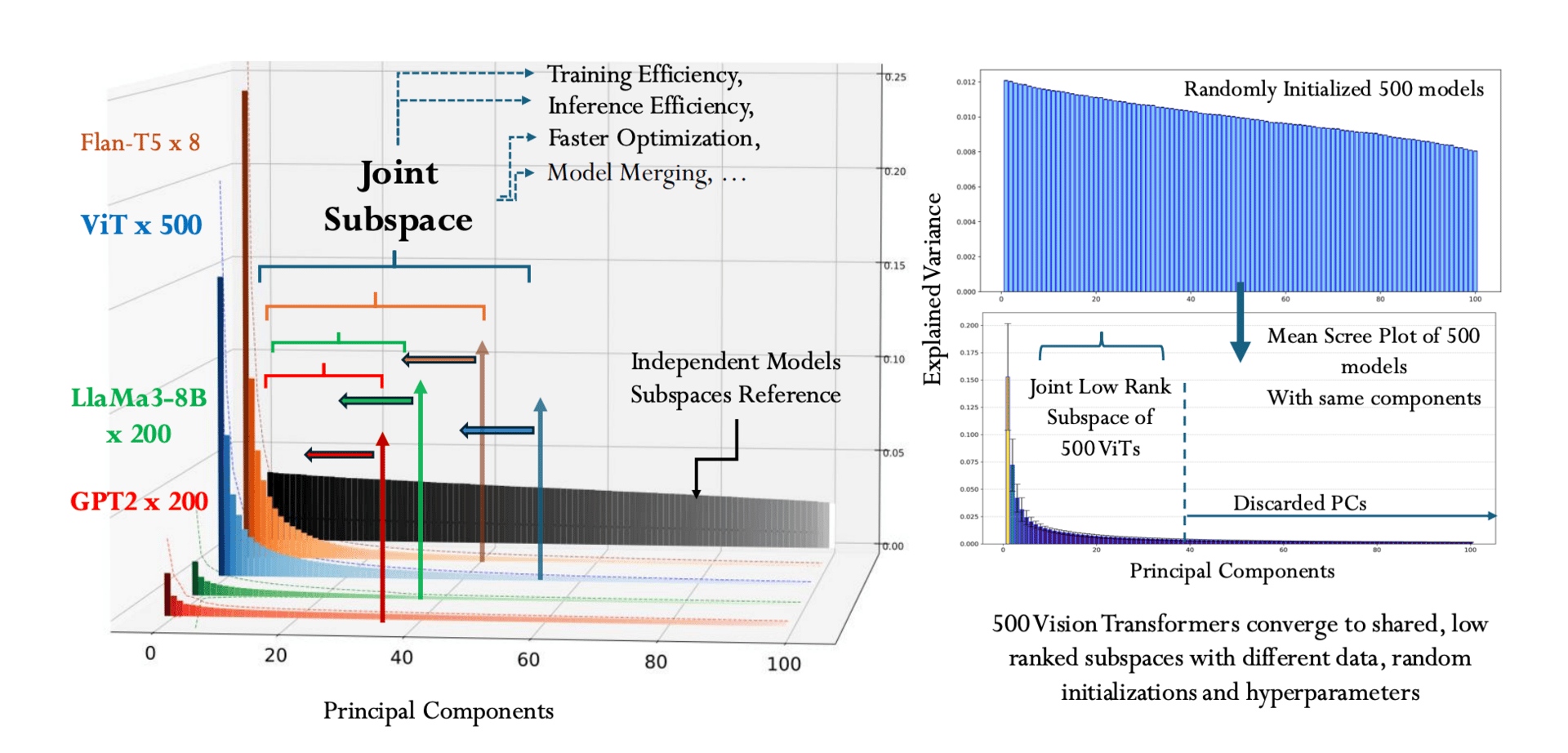
Deep Networks Converge to Shared, Low-Rank (Universal) Subspaces.
The researchers looked at over 1100 models, including 500 Vision Transformers and 500 Mistral-7B LoRA adapters. By applying spectral decomposition to the models' weights, they found that the vast majority of each model's important information is captured by just a handful of principal directions. It’s as if, regardless of what a model was trained to do (recognize images, understand text, or generate content) its parameters end up living in a shared, low-dimensional neighborhood defined by its architecture.

These shared, or "universal," subspaces have powerful practical implications. They allow for efficient model merging, where hundreds of individual models can be compressed into a single, compact representation, saving massive amounts of memory. In tests, a subspace model built from 500 Vision Transformers maintained strong performance while being about 100 times smaller.
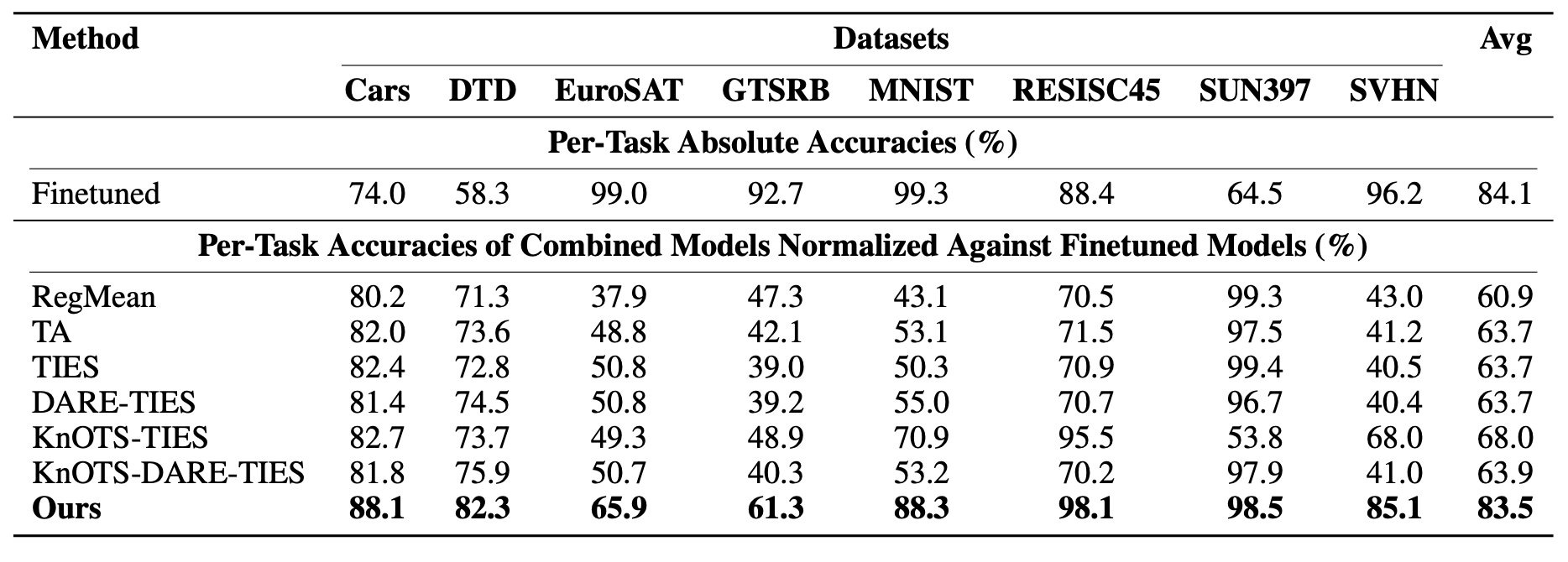
Per-task results for eight ViT-B/32 models, each finetuned with LoRA on a different image classification dataset.
The findings point toward a future where AI development can be more resource-efficient. By leveraging these intrinsic geometric properties, we can build systems that reuse knowledge more effectively, require less storage, and train on new tasks faster. This could significantly reduce the computational and environmental costs of scaling large neural models.
Reply